 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Source Neural Machine Translation with Data Augmentation
Paper and Code


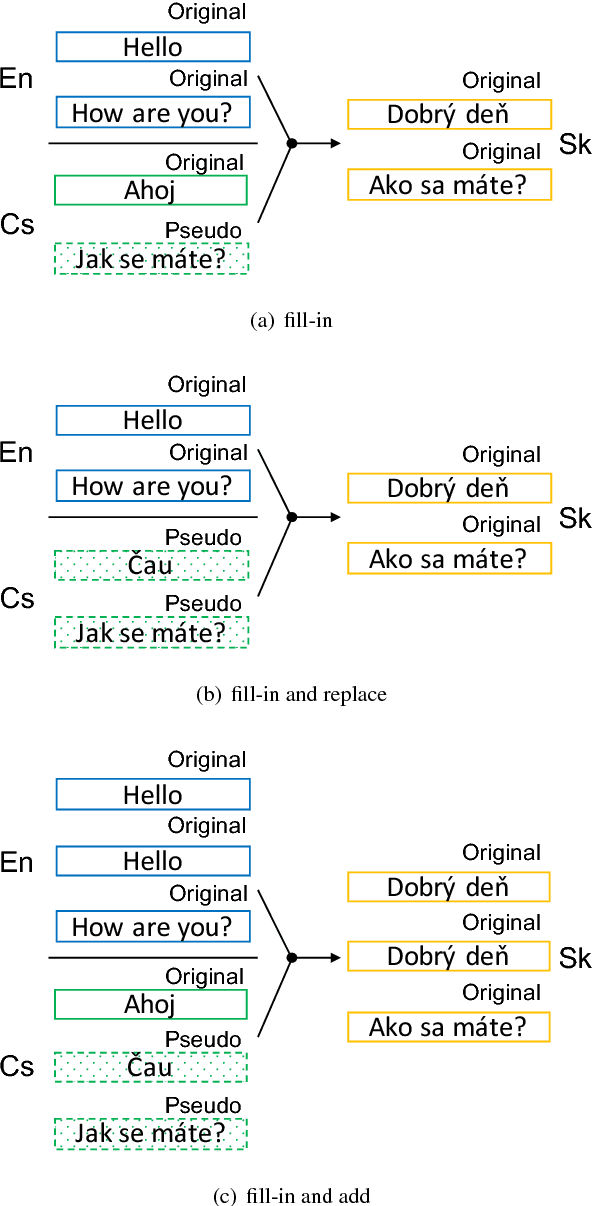

Multi-source translation systems translate from multiple languages to a single target language. By using information from these multiple sources, these systems achieve large gains in accuracy. To train these systems, it is necessary to have corpora with parallel text in multiple sources and the target language. However, these corpora are rarely complete in practice due to the difficulty of providing human translations in all of the relevant languages. In this paper, we propose a data augmentation approach to fill such incomplete parts using multi-source neural machine translation (NMT). In our experiments, results varied over different language combinations but significant gains were observed when using a source language similar to the target language.