 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamically Fused Graph Network for Multi-hop Reasoning
Jun 06, 2019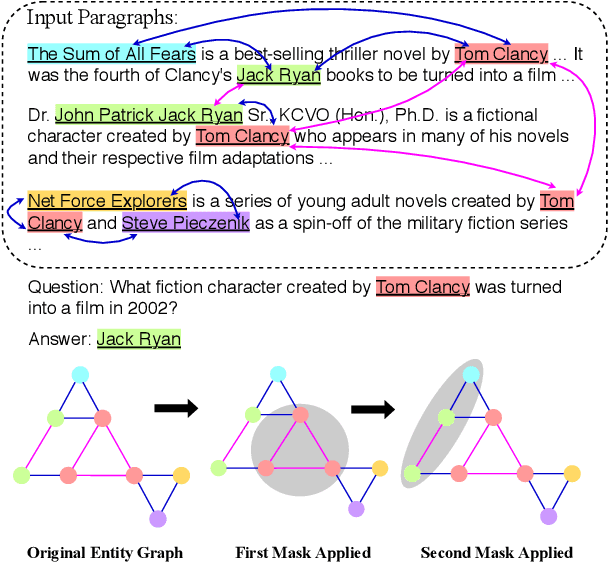
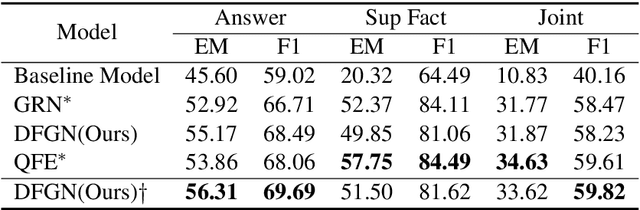

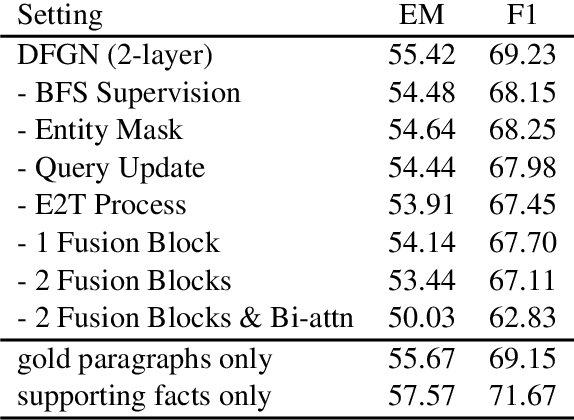
Text-based question answering (TBQA) has been studied extensively in recent years. Most existing approaches focus on finding the answer to a question within a single paragraph. However, many difficult questions require multiple supporting evidence from scattered text among two or more documents. In this paper, we propose Dynamically Fused Graph Network(DFGN), a novel method to answer those questions requiring multiple scattered evidence and reasoning over them. Inspired by human's step-by-step reasoning behavior, DFGN includes a dynamic fusion layer that starts from the entities mentioned in the given query, explores along the entity graph dynamically built from the text, and gradually finds relevant supporting entities from the given documents. We evaluate DFGN on HotpotQA, a public TBQA dataset requiring multi-hop reasoning. DFGN achieves competitive results on the public board. Furthermore, our analysis shows DFGN produces interpretable reasoning chains.
Auto-Retoucher(ART) - A framework for Background Replacement and Image Editing
Jan 13, 2019
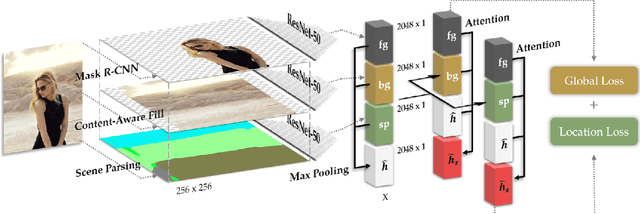

Replacing the background and simultaneously adjusting foreground objects is a challenging task in image editing. Current techniques for generating such images relies heavily on user interactions with image editing softwares, which is a tedious job for professional retouchers. To reduce their workload, some exciting progress has been made on generating images with a given background. However, these models can neither adjust the position and scale of the foreground objects, nor guarantee the semantic consistency between foreground and background. To overcome these limitations, we propose a framework -- ART(Auto-Retoucher), to generate images with sufficient semantic and spatial consistency. Images are first processed by semantic matting and scene parsing modules, then a multi-task verifier model will give two confidence scores for the current background and position setting. We demonstrate that our jointly optimized verifier model successfully improves the visual consistency, and our ART framework performs well on images with the human body as foregrounds.