 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuto-Retoucher(ART) - A framework for Background Replacement and Image Editing
Paper and Code

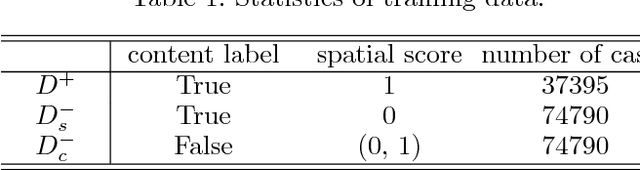
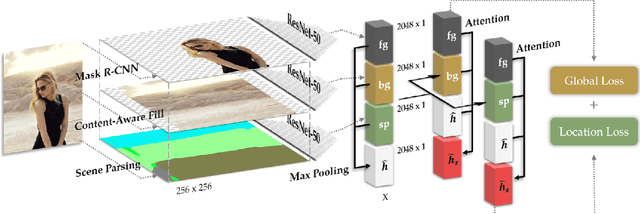

Replacing the background and simultaneously adjusting foreground objects is a challenging task in image editing. Current techniques for generating such images relies heavily on user interactions with image editing softwares, which is a tedious job for professional retouchers. To reduce their workload, some exciting progress has been made on generating images with a given background. However, these models can neither adjust the position and scale of the foreground objects, nor guarantee the semantic consistency between foreground and background. To overcome these limitations, we propose a framework -- ART(Auto-Retoucher), to generate images with sufficient semantic and spatial consistency. Images are first processed by semantic matting and scene parsing modules, then a multi-task verifier model will give two confidence scores for the current background and position setting. We demonstrate that our jointly optimized verifier model successfully improves the visual consistency, and our ART framework performs well on images with the human body as foregrounds.