 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReverse-Engineering Decoding Strategies Given Blackbox Access to a Language Generation System
Sep 09, 2023Neural language models are increasingly deployed into APIs and websites that allow a user to pass in a prompt and receive generated text. Many of these systems do not reveal generation parameters. In this paper, we present methods to reverse-engineer the decoding method used to generate text (i.e., top-$k$ or nucleus sampling). Our ability to discover which decoding strategy was used has implications for detecting generated text. Additionally, the process of discovering the decoding strategy can reveal biases caused by selecting decoding settings which severely truncate a model's predicted distributions. We perform our attack on several families of open-source language models, as well as on production systems (e.g., ChatGPT).
On minimizers and convolutional filters: a partial justification for the unreasonable effectiveness of CNNs in categorical sequence analysis
Nov 19, 2021
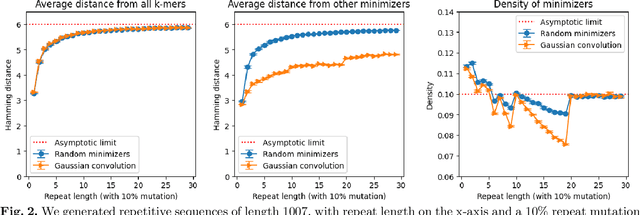
Minimizers and convolutional neural networks (CNNs) are two quite distinct popular techniques that have both been employed to analyze biological sequences. At face value, the methods seem entirely dissimilar. Minimizers use min-wise hashing on a rolling window to extract a single important k-mer feature per window. CNNs start with a wide array of randomly initialized convolutional filters, paired with a pooling operation, and then multiple additional neural layers to learn both the filters themselves and how those filters can be used to classify the sequence. In this manuscript, I demonstrate through a careful mathematical analysis of hash function properties that there are deep theoretical connections between minimizers and convolutional filters -- in short, for sequences over a categorical alphabet, random Gaussian initialization of convolutional filters with max-pooling is equivalent to choosing minimizers from a random hash function biased towards more distinct k-mers. This provides a partial explanation for the unreasonable effectiveness of CNNs in categorical sequence analysis.
COVI White Paper
May 18, 2020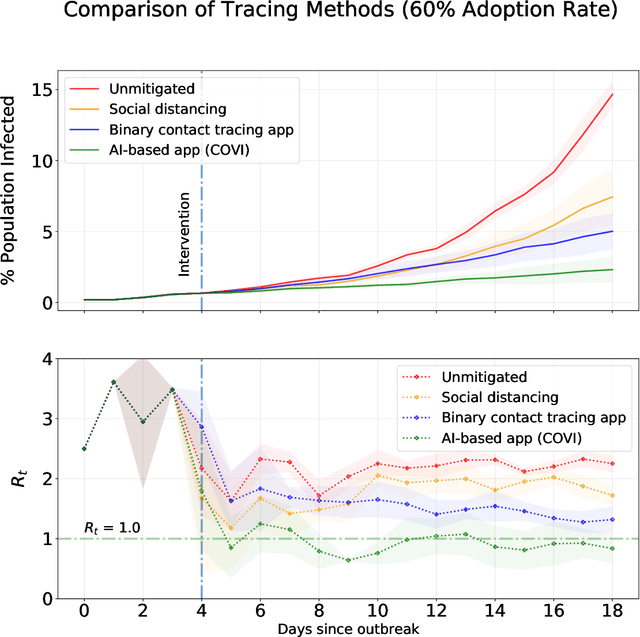
The SARS-CoV-2 (Covid-19) pandemic has caused significant strain on public health institutions around the world. Contact tracing is an essential tool to change the course of the Covid-19 pandemic. Manual contact tracing of Covid-19 cases has significant challenges that limit the ability of public health authorities to minimize community infections. Personalized peer-to-peer contact tracing through the use of mobile apps has the potential to shift the paradigm. Some countries have deployed centralized tracking systems, but more privacy-protecting decentralized systems offer much of the same benefit without concentrating data in the hands of a state authority or for-profit corporations. Machine learning methods can circumvent some of the limitations of standard digital tracing by incorporating many clues and their uncertainty into a more graded and precise estimation of infection risk. The estimated risk can provide early risk awareness, personalized recommendations and relevant information to the user. Finally, non-identifying risk data can inform epidemiological models trained jointly with the machine learning predictor. These models can provide statistical evidence for the importance of factors involved in disease transmission. They can also be used to monitor, evaluate and optimize health policy and (de)confinement scenarios according to medical and economic productivity indicators. However, such a strategy based on mobile apps and machine learning should proactively mitigate potential ethical and privacy risks, which could have substantial impacts on society (not only impacts on health but also impacts such as stigmatization and abuse of personal data). Here, we present an overview of the rationale, design, ethical considerations and privacy strategy of `COVI,' a Covid-19 public peer-to-peer contact tracing and risk awareness mobile application developed in Canada.