 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploration of A Self-Supervised Speech Model: A Study on Emotional Corpora
Oct 05, 2022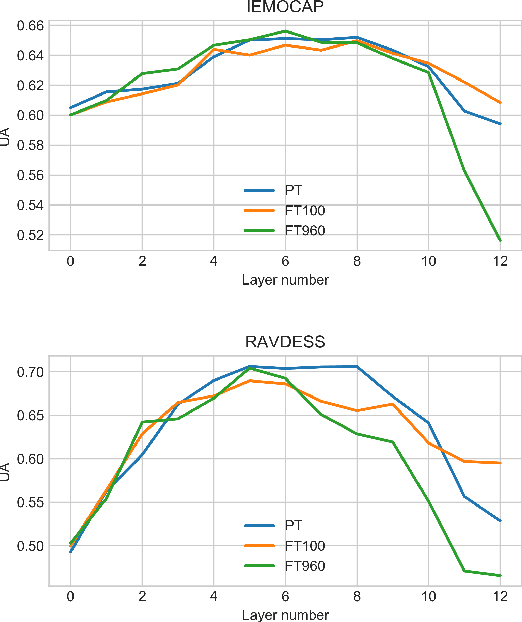
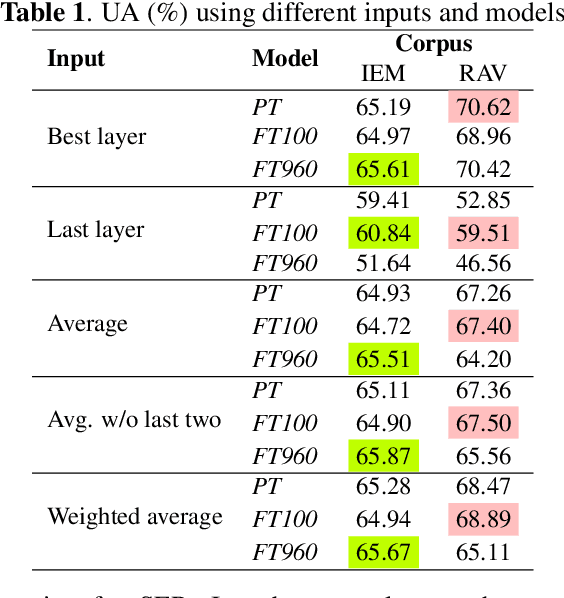
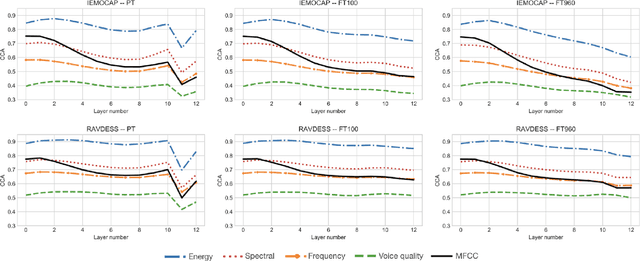

Self-supervised speech models have grown fast during the past few years and have proven feasible for use in various downstream tasks. Some recent work has started to look at the characteristics of these models, yet many concerns have not been fully addressed. In this work, we conduct a study on emotional corpora to explore a popular self-supervised model -- wav2vec 2.0. Via a set of quantitative analysis, we mainly demonstrate that: 1) wav2vec 2.0 appears to discard paralinguistic information that is less useful for word recognition purposes; 2) for emotion recognition, representations from the middle layer alone perform as well as those derived from layer averaging, while the final layer results in the worst performance in some cases; 3) current self-supervised models may not be the optimal solution for downstream tasks that make use of non-lexical features. Our work provides novel findings that will aid future research in this area and theoretical basis for the use of existing models.
Rethinking multiscale cardiac electrophysiology with machine learning and predictive modelling
Oct 09, 2018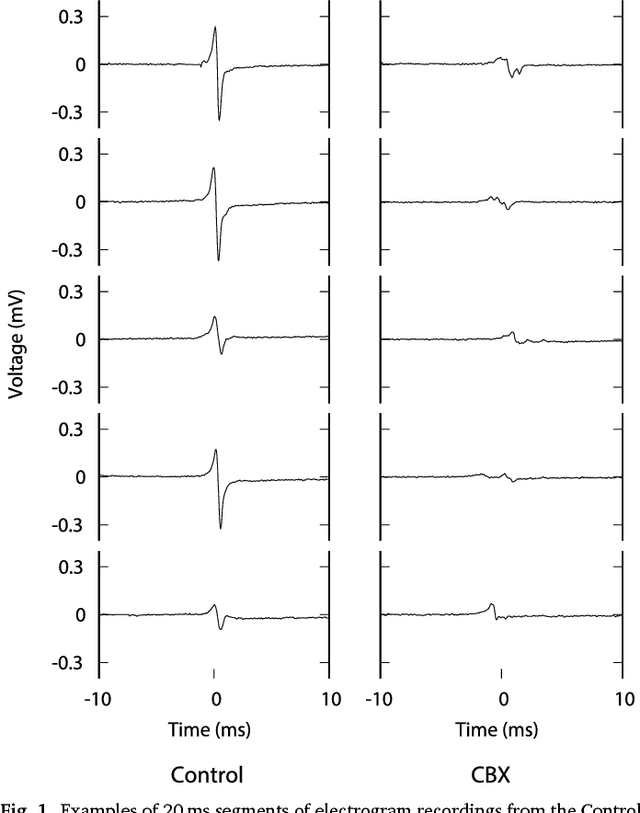
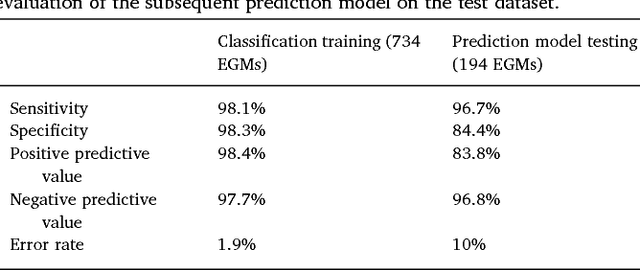
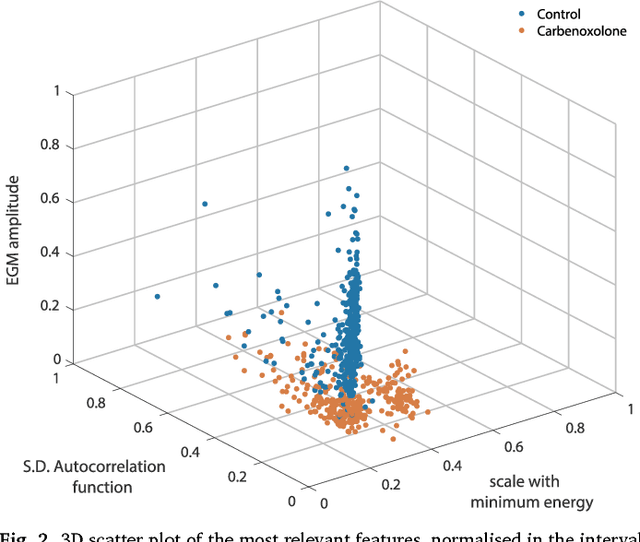
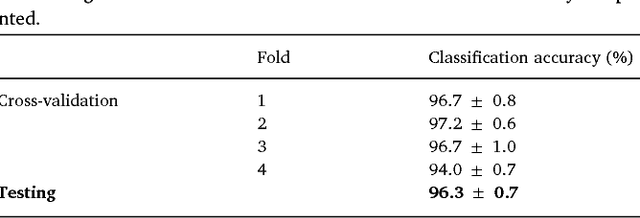
We review some of the latest approaches to analysing cardiac electrophysiology data using machine learning and predictive modelling. Cardiac arrhythmias, particularly atrial fibrillation, are a major global healthcare challenge. Treatment is often through catheter ablation, which involves the targeted localized destruction of regions of the myocardium responsible for initiating or perpetuating the arrhythmia. Ablation targets are either anatomically defined, or identified based on their functional properties as determined through the analysis of contact intracardiac electrograms acquired with increasing spatial density by modern electroanatomic mapping systems. While numerous quantitative approaches have been investigated over the past decades for identifying these critical curative sites, few have provided a reliable and reproducible advance in success rates. Machine learning techniques, including recent deep-learning approaches, offer a potential route to gaining new insight from this wealth of highly complex spatio-temporal information that existing methods struggle to analyse. Coupled with predictive modelling, these techniques offer exciting opportunities to advance the field and produce more accurate diagnoses and robust personalised treatment. We outline some of these methods and illustrate their use in making predictions from the contact electrogram and augmenting predictive modelling tools, both by more rapidly predicting future states of the system and by inferring the parameters of these models from experimental observations.
Adversarial Information Factorization
Sep 28, 2018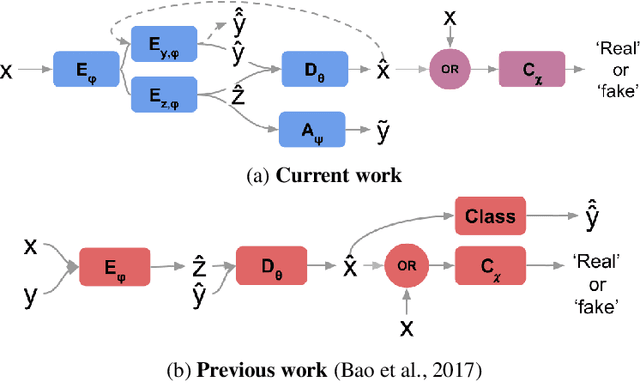
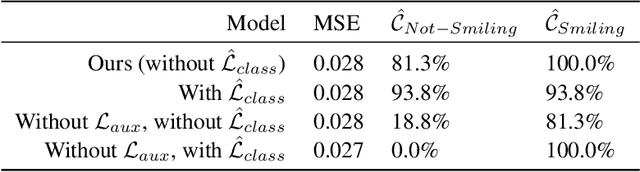
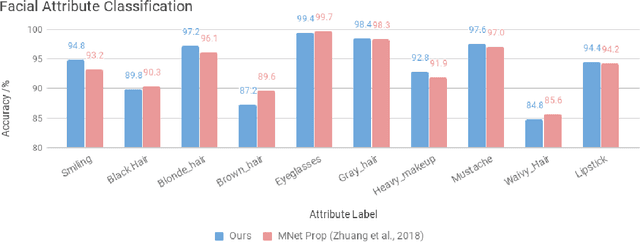

We propose a novel generative model architecture designed to learn representations for images that factor out a single attribute from the rest of the representation. A single object may have many attributes which when altered do not change the identity of the object itself. Consider the human face; the identity of a particular person is independent of whether or not they happen to be wearing glasses. The attribute of wearing glasses can be changed without changing the identity of the person. However, the ability to manipulate and alter image attributes without altering the object identity is not a trivial task. Here, we are interested in learning a representation of the image that separates the identity of an object (such as a human face) from an attribute (such as 'wearing glasses'). We demonstrate the success of our factorization approach by using the learned representation to synthesize the same face with and without a chosen attribute. We refer to this specific synthesis process as image attribute manipulation. We further demonstrate that our model achieves competitive scores, with state of the art, on a facial attribute classification task.