 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Synthetic Data with Formal Privacy Guarantees: State of the Art and the Road Ahead
Mar 26, 2025Privacy-preserving synthetic data offers a promising solution to harness segregated data in high-stakes domains where information is compartmentalized for regulatory, privacy, or institutional reasons. This survey provides a comprehensive framework for understanding the landscape of privacy-preserving synthetic data, presenting the theoretical foundations of generative models and differential privacy followed by a review of state-of-the-art methods across tabular data, images, and text. Our synthesis of evaluation approaches highlights the fundamental trade-off between utility for down-stream tasks and privacy guarantees, while identifying critical research gaps: the lack of realistic benchmarks representing specialized domains and insufficient empirical evaluations required to contextualise formal guarantees. Through empirical analysis of four leading methods on five real-world datasets from specialized domains, we demonstrate significant performance degradation under realistic privacy constraints ($\epsilon \leq 4$), revealing a substantial gap between results reported on general domain benchmarks and performance on domain-specific data. %Our findings highlight key challenges including unaccounted privacy leakage, insufficient empirical verification of formal guarantees, and a critical deficit of realistic benchmarks. These challenges underscore the need for robust evaluation frameworks, standardized benchmarks for specialized domains, and improved techniques to address the unique requirements of privacy-sensitive fields such that this technology can deliver on its considerable potential.
Prototype of a Cardiac MRI Simulator for the Training of Supervised Neural Networks
May 25, 2023Supervised deep learning methods typically rely on large datasets for training. Ethical and practical considerations usually make it difficult to access large amounts of healthcare data, such as medical images, with known task-specific ground truth. This hampers the development of adequate, unbiased and robust deep learning methods for clinical tasks. Magnetic Resonance Images (MRI) are the result of several complex physical and engineering processes and the generation of synthetic MR images provides a formidable challenge. Here, we present the first results of ongoing work to create a generator for large synthetic cardiac MR image datasets. As an application for the simulator, we show how the synthetic images can be used to help train a supervised neural network that estimates the volume of the left ventricular myocardium directly from cardiac MR images. Despite its current limitations, our generator may in the future help address the current shortage of labelled cardiac MRI needed for the development of supervised deep learning tools. It is likely to also find applications in the development of image reconstruction methods and tools to improve robustness, verification and interpretability of deep networks in this setting.
Adversarial Information Factorization
Sep 28, 2018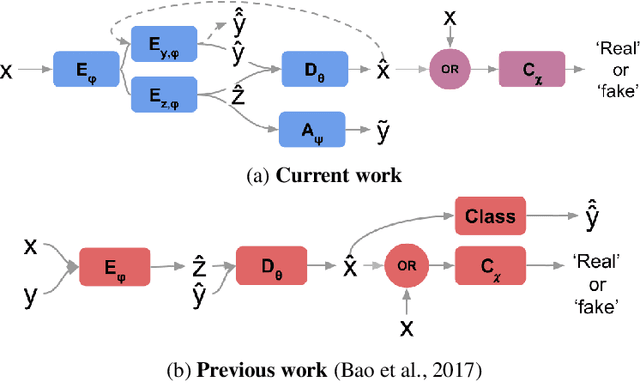
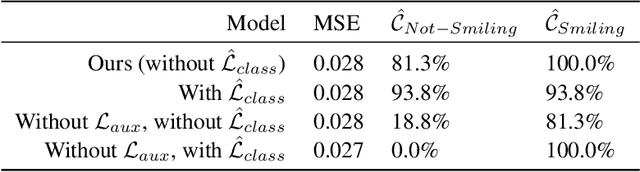
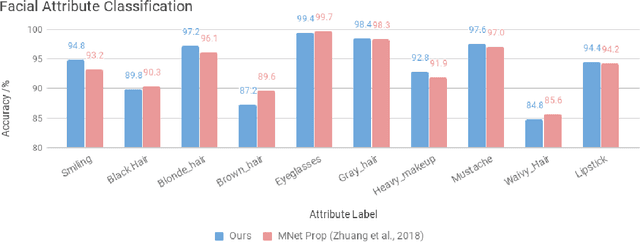

We propose a novel generative model architecture designed to learn representations for images that factor out a single attribute from the rest of the representation. A single object may have many attributes which when altered do not change the identity of the object itself. Consider the human face; the identity of a particular person is independent of whether or not they happen to be wearing glasses. The attribute of wearing glasses can be changed without changing the identity of the person. However, the ability to manipulate and alter image attributes without altering the object identity is not a trivial task. Here, we are interested in learning a representation of the image that separates the identity of an object (such as a human face) from an attribute (such as 'wearing glasses'). We demonstrate the success of our factorization approach by using the learned representation to synthesize the same face with and without a chosen attribute. We refer to this specific synthesis process as image attribute manipulation. We further demonstrate that our model achieves competitive scores, with state of the art, on a facial attribute classification task.
Inverting The Generator Of A Generative Adversarial Network (II)
Feb 15, 2018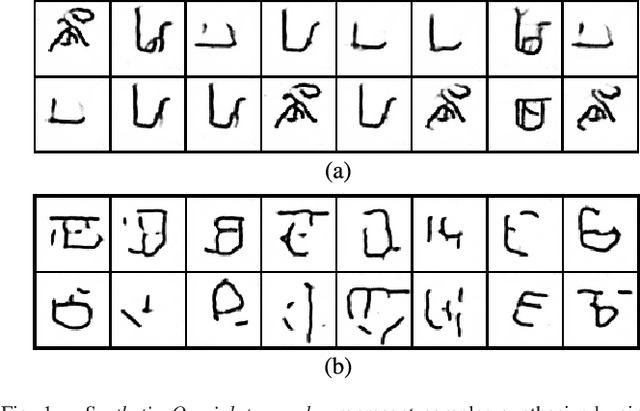


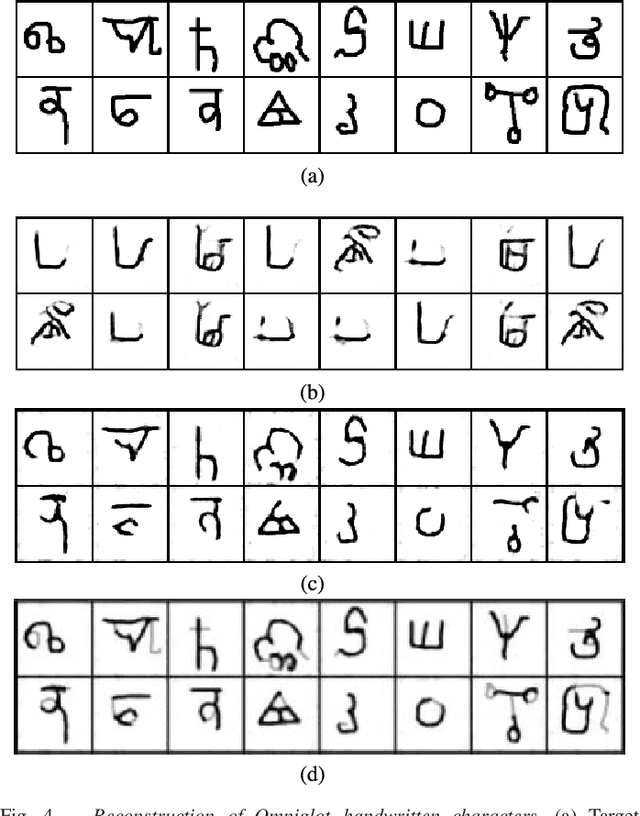
Generative adversarial networks (GANs) learn a deep generative model that is able to synthesise novel, high-dimensional data samples. New data samples are synthesised by passing latent samples, drawn from a chosen prior distribution, through the generative model. Once trained, the latent space exhibits interesting properties, that may be useful for down stream tasks such as classification or retrieval. Unfortunately, GANs do not offer an "inverse model", a mapping from data space back to latent space, making it difficult to infer a latent representation for a given data sample. In this paper, we introduce a technique, inversion, to project data samples, specifically images, to the latent space using a pre-trained GAN. Using our proposed inversion technique, we are able to identify which attributes of a dataset a trained GAN is able to model and quantify GAN performance, based on a reconstruction loss. We demonstrate how our proposed inversion technique may be used to quantitatively compare performance of various GAN models trained on three image datasets. We provide code for all of our experiments, https://github.com/ToniCreswell/InvertingGAN.
Denoising Adversarial Autoencoders: Classifying Skin Lesions Using Limited Labelled Training Data
Jan 02, 2018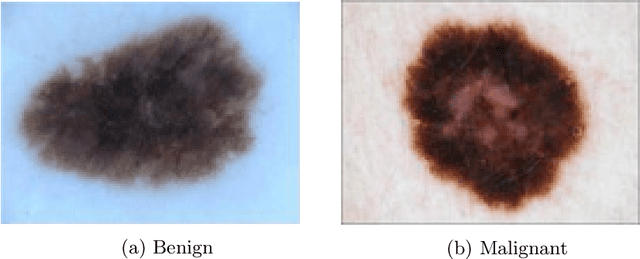

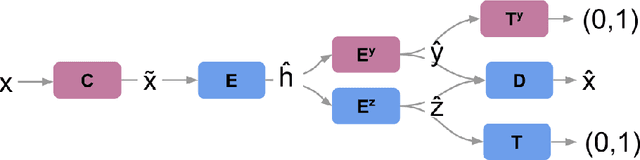

We propose a novel deep learning model for classifying medical images in the setting where there is a large amount of unlabelled medical data available, but labelled data is in limited supply. We consider the specific case of classifying skin lesions as either malignant or benign. In this setting, the proposed approach -- the semi-supervised, denoising adversarial autoencoder -- is able to utilise vast amounts of unlabelled data to learn a representation for skin lesions, and small amounts of labelled data to assign class labels based on the learned representation. We analyse the contributions of both the adversarial and denoising components of the model and find that the combination yields superior classification performance in the setting of limited labelled training data.
Generative Adversarial Networks: An Overview
Oct 19, 2017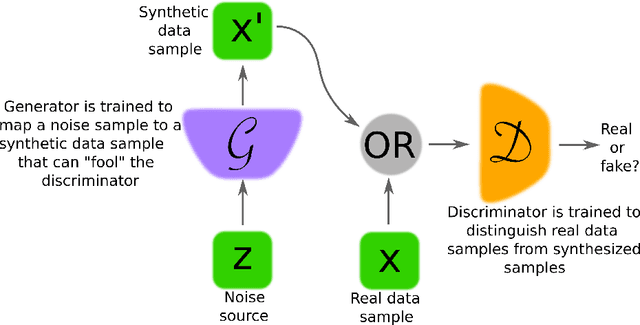

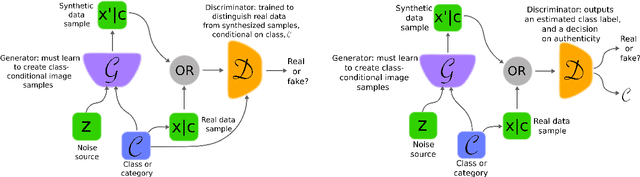
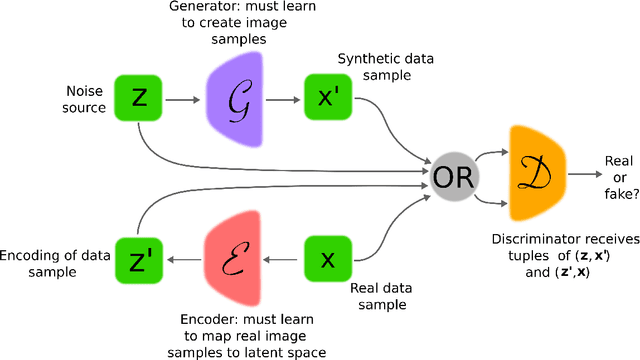
Generative adversarial networks (GANs) provide a way to learn deep representations without extensively annotated training data. They achieve this through deriving backpropagation signals through a competitive process involving a pair of networks. The representations that can be learned by GANs may be used in a variety of applications, including image synthesis, semantic image editing, style transfer, image super-resolution and classification. The aim of this review paper is to provide an overview of GANs for the signal processing community, drawing on familiar analogies and concepts where possible. In addition to identifying different methods for training and constructing GANs, we also point to remaining challenges in their theory and application.