 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploration of A Self-Supervised Speech Model: A Study on Emotional Corpora
Paper and Code
Oct 05, 2022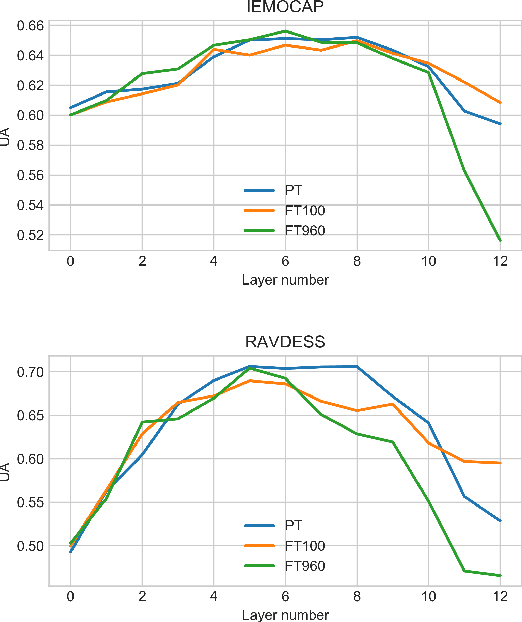
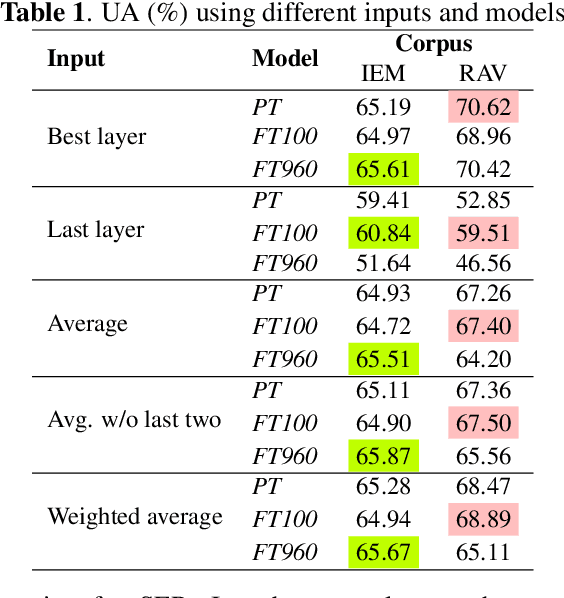
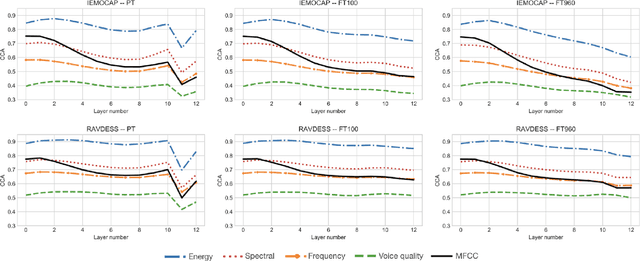

Self-supervised speech models have grown fast during the past few years and have proven feasible for use in various downstream tasks. Some recent work has started to look at the characteristics of these models, yet many concerns have not been fully addressed. In this work, we conduct a study on emotional corpora to explore a popular self-supervised model -- wav2vec 2.0. Via a set of quantitative analysis, we mainly demonstrate that: 1) wav2vec 2.0 appears to discard paralinguistic information that is less useful for word recognition purposes; 2) for emotion recognition, representations from the middle layer alone perform as well as those derived from layer averaging, while the final layer results in the worst performance in some cases; 3) current self-supervised models may not be the optimal solution for downstream tasks that make use of non-lexical features. Our work provides novel findings that will aid future research in this area and theoretical basis for the use of existing models.