 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHICH Image/Text : Comprehensive Text and Image Datasets for Hypertensive Intracerebral Hemorrhage Research
Feb 05, 2024In this paper, we introduce a new dataset in the medical field of hypertensive intracerebral hemorrhage (HICH), called HICH-IT, which includes both electronic medical records (EMRs) and head CT images. This dataset is designed to enhance the accuracy of artificial intelligence in the diagnosis and treatment of HICH. This dataset, built upon the foundation of standard text and image data, incorporates specific annotations within the EMRs, extracting key content from the text information, and categorizes the annotation content of imaging data into four types: brain midline, hematoma, left and right cerebral ventricle. HICH-IT aims to be a foundational dataset for feature learning in image segmentation tasks and named entity recognition. To further understand the dataset, we have trained deep learning algorithms to observe the performance. The pretrained models have been released at both www.daip.club and github.com/Deep-AI-Application-DAIP. The dataset has been uploaded to https://github.com/CYBUS123456/HICH-IT-Datasets. Index Terms-HICH, Deep learning, Intraparenchymal hemorrhage, named entity recognition, novel dataset
TarGF: Learning Target Gradient Field for Object Rearrangement
Sep 02, 2022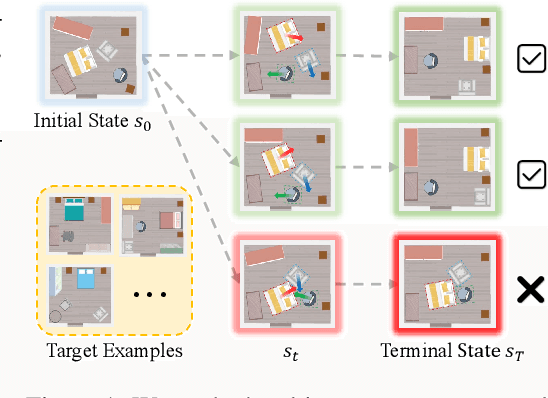

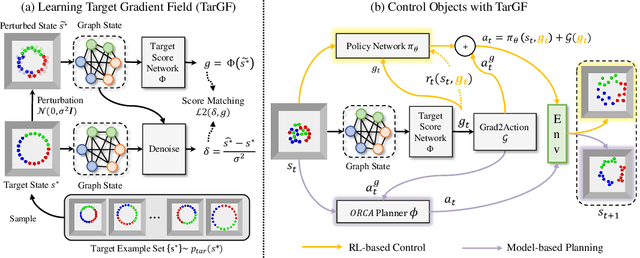
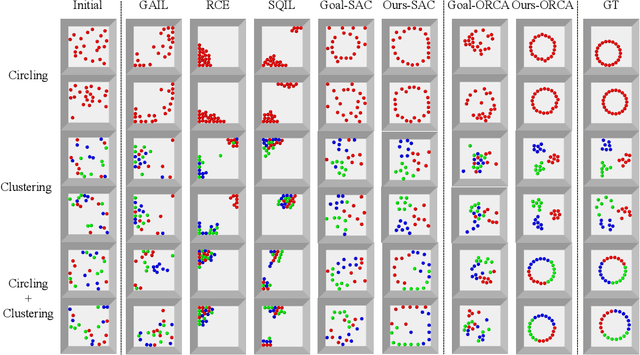
Object Rearrangement is to move objects from an initial state to a goal state. Here, we focus on a more practical setting in object rearrangement, i.e., rearranging objects from shuffled layouts to a normative target distribution without explicit goal specification. However, it remains challenging for AI agents, as it is hard to describe the target distribution (goal specification) for reward engineering or collect expert trajectories as demonstrations. Hence, it is infeasible to directly employ reinforcement learning or imitation learning algorithms to address the task. This paper aims to search for a policy only with a set of examples from a target distribution instead of a handcrafted reward function. We employ the score-matching objective to train a Target Gradient Field (TarGF), indicating a direction on each object to increase the likelihood of the target distribution. For object rearrangement, the TarGF can be used in two ways: 1) For model-based planning, we can cast the target gradient into a reference control and output actions with a distributed path planner; 2) For model-free reinforcement learning, the TarGF is not only used for estimating the likelihood-change as a reward but also provides suggested actions in residual policy learning. Experimental results in ball rearrangement and room rearrangement demonstrate that our method significantly outperforms the state-of-the-art methods in the quality of the terminal state, the efficiency of the control process, and scalability. The code and demo videos are on our project website.