 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttributing and Exploiting Safety Vectors through Global Optimization in Large Language Models
Jan 22, 2026While Large Language Models (LLMs) are aligned to mitigate risks, their safety guardrails remain fragile against jailbreak attacks. This reveals limited understanding of components governing safety. Existing methods rely on local, greedy attribution that assumes independent component contributions. However, they overlook the cooperative interactions between different components in LLMs, such as attention heads, which jointly contribute to safety mechanisms. We propose \textbf{G}lobal \textbf{O}ptimization for \textbf{S}afety \textbf{V}ector Extraction (GOSV), a framework that identifies safety-critical attention heads through global optimization over all heads simultaneously. We employ two complementary activation repatching strategies: Harmful Patching and Zero Ablation. These strategies identify two spatially distinct sets of safety vectors with consistently low overlap, termed Malicious Injection Vectors and Safety Suppression Vectors, demonstrating that aligned LLMs maintain separate functional pathways for safety purposes. Through systematic analyses, we find that complete safety breakdown occurs when approximately 30\% of total heads are repatched across all models. Building on these insights, we develop a novel inference-time white-box jailbreak method that exploits the identified safety vectors through activation repatching. Our attack substantially outperforms existing white-box attacks across all test models, providing strong evidence for the effectiveness of the proposed GOSV framework on LLM safety interpretability.
Revisiting Adversarial Perception Attacks and Defense Methods on Autonomous Driving Systems
May 14, 2025Autonomous driving systems (ADS) increasingly rely on deep learning-based perception models, which remain vulnerable to adversarial attacks. In this paper, we revisit adversarial attacks and defense methods, focusing on road sign recognition and lead object detection and prediction (e.g., relative distance). Using a Level-2 production ADS, OpenPilot by Comma.ai, and the widely adopted YOLO model, we systematically examine the impact of adversarial perturbations and assess defense techniques, including adversarial training, image processing, contrastive learning, and diffusion models. Our experiments highlight both the strengths and limitations of these methods in mitigating complex attacks. Through targeted evaluations of model robustness, we aim to provide deeper insights into the vulnerabilities of ADS perception systems and contribute guidance for developing more resilient defense strategies.
Large Language Model-Enhanced Reinforcement Learning for Generic Bus Holding Control Strategies
Oct 14, 2024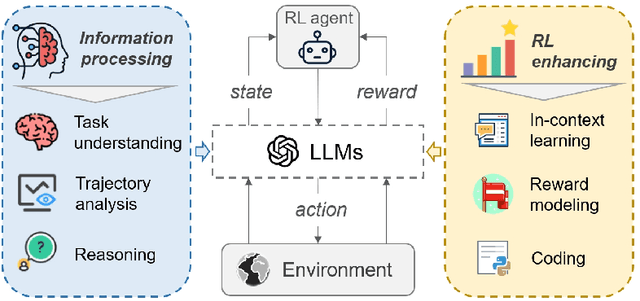
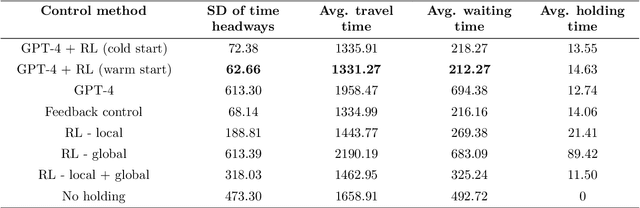
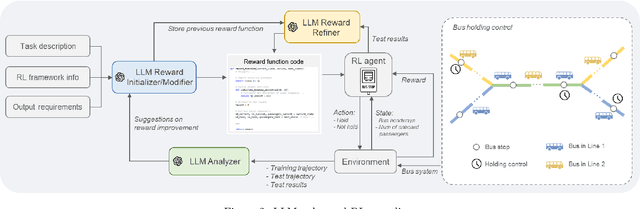
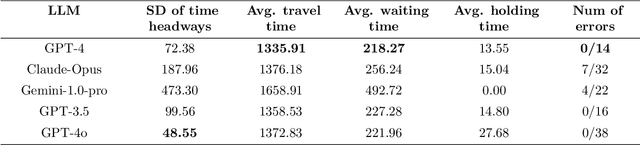
Bus holding control is a widely-adopted strategy for maintaining stability and improving the operational efficiency of bus systems. Traditional model-based methods often face challenges with the low accuracy of bus state prediction and passenger demand estimation. In contrast, Reinforcement Learning (RL), as a data-driven approach, has demonstrated great potential in formulating bus holding strategies. RL determines the optimal control strategies in order to maximize the cumulative reward, which reflects the overall control goals. However, translating sparse and delayed control goals in real-world tasks into dense and real-time rewards for RL is challenging, normally requiring extensive manual trial-and-error. In view of this, this study introduces an automatic reward generation paradigm by leveraging the in-context learning and reasoning capabilities of Large Language Models (LLMs). This new paradigm, termed the LLM-enhanced RL, comprises several LLM-based modules: reward initializer, reward modifier, performance analyzer, and reward refiner. These modules cooperate to initialize and iteratively improve the reward function according to the feedback from training and test results for the specified RL-based task. Ineffective reward functions generated by the LLM are filtered out to ensure the stable evolution of the RL agents' performance over iterations. To evaluate the feasibility of the proposed LLM-enhanced RL paradigm, it is applied to various bus holding control scenarios, including a synthetic single-line system and a real-world multi-line system. The results demonstrate the superiority and robustness of the proposed paradigm compared to vanilla RL strategies, the LLM-based controller, and conventional space headway-based feedback control. This study sheds light on the great potential of utilizing LLMs in various smart mobility applications.
Temporal Perceiver: A General Architecture for Arbitrary Boundary Detection
Mar 01, 2022
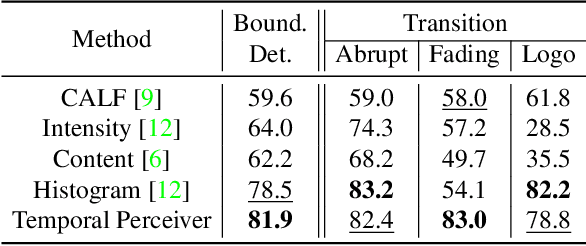
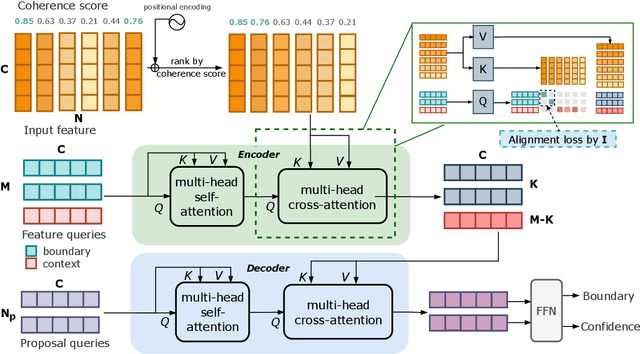
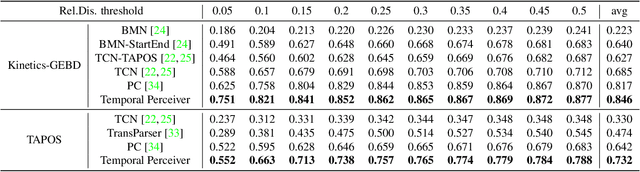
Generic Boundary Detection (GBD) aims at locating general boundaries that divide videos into semantically coherent and taxonomy-free units, and could server as an important pre-processing step for long-form video understanding. Previous research separately handle these different-level generic boundaries with specific designs of complicated deep networks from simple CNN to LSTM. Instead, in this paper, our objective is to develop a general yet simple architecture for arbitrary boundary detection in videos. To this end, we present Temporal Perceiver, a general architecture with Transformers, offering a unified solution to the detection of arbitrary generic boundaries. The core design is to introduce a small set of latent feature queries as anchors to compress the redundant input into fixed dimension via cross-attention blocks. Thanks to this fixed number of latent units, it reduces the quadratic complexity of attention operation to a linear form of input frames. Specifically, to leverage the coherence structure of videos, we construct two types of latent feature queries: boundary queries and context queries, which handle the semantic incoherence and coherence regions accordingly. Moreover, to guide the learning of latent feature queries, we propose an alignment loss on cross-attention to explicitly encourage the boundary queries to attend on the top possible boundaries. Finally, we present a sparse detection head on the compressed representations and directly output the final boundary detection results without any post-processing module. We test our Temporal Perceiver on a variety of detection benchmarks, ranging from shot-level, event-level, to scene-level GBD. Our method surpasses the previous state-of-the-art methods on all benchmarks, demonstrating the generalization ability of our temporal perceiver.