 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Model-Enhanced Reinforcement Learning for Generic Bus Holding Control Strategies
Oct 14, 2024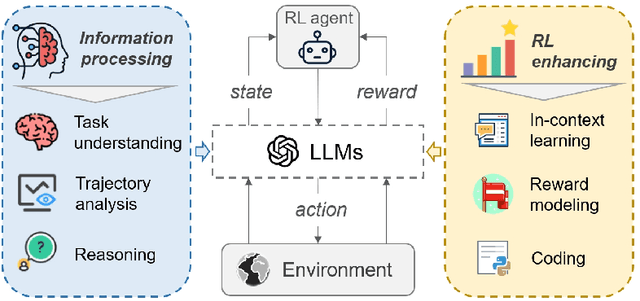
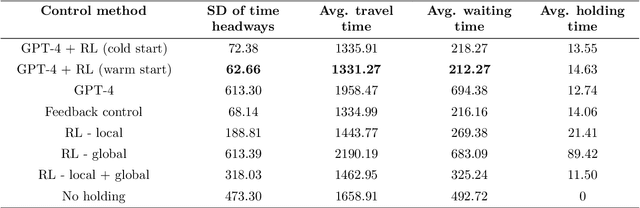
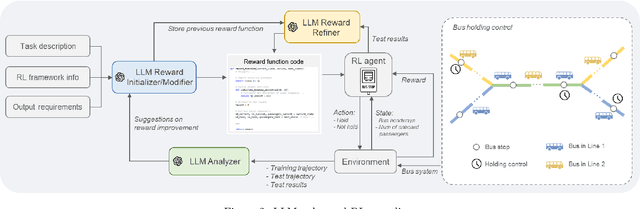
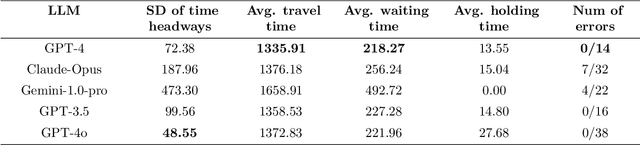
Bus holding control is a widely-adopted strategy for maintaining stability and improving the operational efficiency of bus systems. Traditional model-based methods often face challenges with the low accuracy of bus state prediction and passenger demand estimation. In contrast, Reinforcement Learning (RL), as a data-driven approach, has demonstrated great potential in formulating bus holding strategies. RL determines the optimal control strategies in order to maximize the cumulative reward, which reflects the overall control goals. However, translating sparse and delayed control goals in real-world tasks into dense and real-time rewards for RL is challenging, normally requiring extensive manual trial-and-error. In view of this, this study introduces an automatic reward generation paradigm by leveraging the in-context learning and reasoning capabilities of Large Language Models (LLMs). This new paradigm, termed the LLM-enhanced RL, comprises several LLM-based modules: reward initializer, reward modifier, performance analyzer, and reward refiner. These modules cooperate to initialize and iteratively improve the reward function according to the feedback from training and test results for the specified RL-based task. Ineffective reward functions generated by the LLM are filtered out to ensure the stable evolution of the RL agents' performance over iterations. To evaluate the feasibility of the proposed LLM-enhanced RL paradigm, it is applied to various bus holding control scenarios, including a synthetic single-line system and a real-world multi-line system. The results demonstrate the superiority and robustness of the proposed paradigm compared to vanilla RL strategies, the LLM-based controller, and conventional space headway-based feedback control. This study sheds light on the great potential of utilizing LLMs in various smart mobility applications.
Perimeter Control with Heterogeneous Cordon Signal Behaviors: A Semi-Model Dependent Reinforcement Learning Approach
Aug 24, 2023



Perimeter Control (PC) strategies have been proposed to address urban road network control in oversaturated situations by monitoring transfer flows of the Protected Network (PN). The uniform metering rate for cordon signals in existing studies ignores the variety of local traffic states at the intersection level, which may cause severe local traffic congestion and ruin the network stability. This paper introduces a semi-model dependent Multi-Agent Reinforcement Learning (MARL) framework to conduct PC with heterogeneous cordon signal behaviors. The proposed strategy integrates the MARL-based signal control method with centralized feedback PC policy and is applied to cordon signals of the PN. It operates as a two-stage system, with the feedback PC strategy detecting the overall traffic state within the PN and then distributing local instructions to cordon signals controlled by agents in the MARL framework. Each cordon signal acts independently and differently, creating a slack and distributed PC for the PN. The combination of the model-free and model-based methods is achieved by reconstructing the action-value function of the local agents with PC feedback reward without violating the integrity of the local signal control policy learned from the RL training process. Through numerical tests with different demand patterns in a microscopic traffic environment, the proposed PC strategy (a) is shown robustness, scalability, and transferability, (b) outperforms state-of-the-art model-based PC strategies in increasing network throughput, reducing cordon queue and carbon emission.
A Heuristic Autonomous Exploration Method Based on Environmental Information Gain During Quadrotor Flight
Feb 21, 2023



Autonomous exploration is a widely studied fundamental application in the field of quadrotors, which requires them to automatically explore unknown space to obtain complete information about the environment. The frontier-based method, which is one of the representative works on autonomous exploration, drives autonomous determination by the definition of frontier information, so that complete information about the environment is available to the quadrotor. However, existing frontier-based methods are able to accomplish the task but still suffer from inefficient exploration. How to improve the efficiency of autonomous exploration is the focus of current research. Typical problems include slow frontier generation, which affects real-time viewpoint determination, and insufficient determination methods that affect the quality of viewpoints. Therefore, to overcome these problems, this paper proposes a two-level viewpoint determination method for frontier-based autonomous exploration. Firstly, a sampling-based frontier detection method is presented for faster frontier generation, which improves the immediacy of environmental representation compared to traditional traversal-based methods. Secondly, we consider the access to environmental information during flight for the first time and design an innovative heuristic evaluation function to decide on a high-quality viewpoint as the next local navigation target in each exploration iteration. We conducted extensive benchmark and real-world tests to validate our method. The results confirm that our method optimizes the frontier search time by 85%, the exploration time by around 20-30%, and the exploration path by 25-35%.