 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Model-Enhanced Reinforcement Learning for Generic Bus Holding Control Strategies
Paper and Code
Oct 14, 2024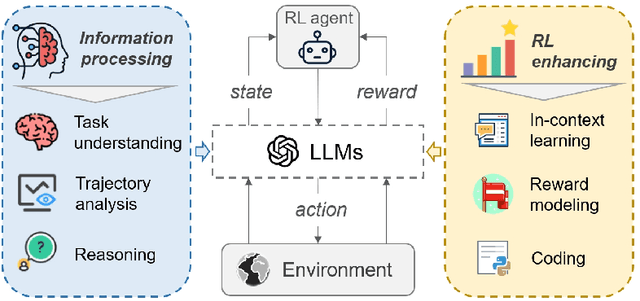
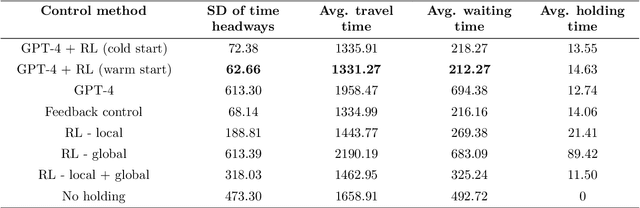
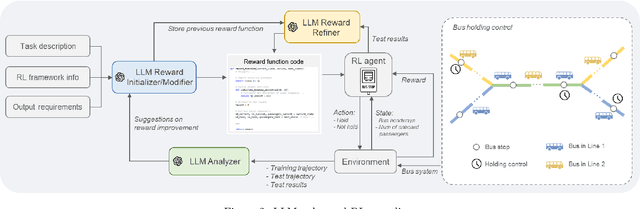
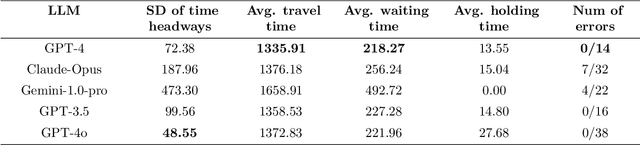
Bus holding control is a widely-adopted strategy for maintaining stability and improving the operational efficiency of bus systems. Traditional model-based methods often face challenges with the low accuracy of bus state prediction and passenger demand estimation. In contrast, Reinforcement Learning (RL), as a data-driven approach, has demonstrated great potential in formulating bus holding strategies. RL determines the optimal control strategies in order to maximize the cumulative reward, which reflects the overall control goals. However, translating sparse and delayed control goals in real-world tasks into dense and real-time rewards for RL is challenging, normally requiring extensive manual trial-and-error. In view of this, this study introduces an automatic reward generation paradigm by leveraging the in-context learning and reasoning capabilities of Large Language Models (LLMs). This new paradigm, termed the LLM-enhanced RL, comprises several LLM-based modules: reward initializer, reward modifier, performance analyzer, and reward refiner. These modules cooperate to initialize and iteratively improve the reward function according to the feedback from training and test results for the specified RL-based task. Ineffective reward functions generated by the LLM are filtered out to ensure the stable evolution of the RL agents' performance over iterations. To evaluate the feasibility of the proposed LLM-enhanced RL paradigm, it is applied to various bus holding control scenarios, including a synthetic single-line system and a real-world multi-line system. The results demonstrate the superiority and robustness of the proposed paradigm compared to vanilla RL strategies, the LLM-based controller, and conventional space headway-based feedback control. This study sheds light on the great potential of utilizing LLMs in various smart mobility applications.