 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuickest Change Detection with Confusing Change
May 01, 2024In the problem of quickest change detection (QCD), a change occurs at some unknown time in the distribution of a sequence of independent observations. This work studies a QCD problem where the change is either a bad change, which we aim to detect, or a confusing change, which is not of our interest. Our objective is to detect a bad change as quickly as possible while avoiding raising a false alarm for pre-change or a confusing change. We identify a specific set of pre-change, bad change, and confusing change distributions that pose challenges beyond the capabilities of standard Cumulative Sum (CuSum) procedures. Proposing novel CuSum-based detection procedures, S-CuSum and J-CuSum, leveraging two CuSum statistics, we offer solutions applicable across all kinds of pre-change, bad change, and confusing change distributions. For both S-CuSum and J-CuSum, we provide analytical performance guarantees and validate them by numerical results. Furthermore, both procedures are computationally efficient as they only require simple recursive updates.
On Collaboration in Distributed Parameter Estimation with Resource Constraints
Jul 12, 2023


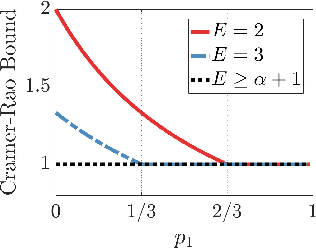
We study sensor/agent data collection and collaboration policies for parameter estimation, accounting for resource constraints and correlation between observations collected by distinct sensors/agents. Specifically, we consider a group of sensors/agents each samples from different variables of a multivariate Gaussian distribution and has different estimation objectives, and we formulate a sensor/agent's data collection and collaboration policy design problem as a Fisher information maximization (or Cramer-Rao bound minimization) problem. When the knowledge of correlation between variables is available, we analytically identify two particular scenarios: (1) where the knowledge of the correlation between samples cannot be leveraged for collaborative estimation purposes and (2) where the optimal data collection policy involves investing scarce resources to collaboratively sample and transfer information that is not of immediate interest and whose statistics are already known, with the sole goal of increasing the confidence on the estimate of the parameter of interest. When the knowledge of certain correlation is unavailable but collaboration may still be worthwhile, we propose novel ways to apply multi-armed bandit algorithms to learn the optimal data collection and collaboration policy in our distributed parameter estimation problem and demonstrate that the proposed algorithms, DOUBLE-F, DOUBLE-Z, UCB-F, UCB-Z, are effective through simulations.
On-Demand Communication for Asynchronous Multi-Agent Bandits
Feb 15, 2023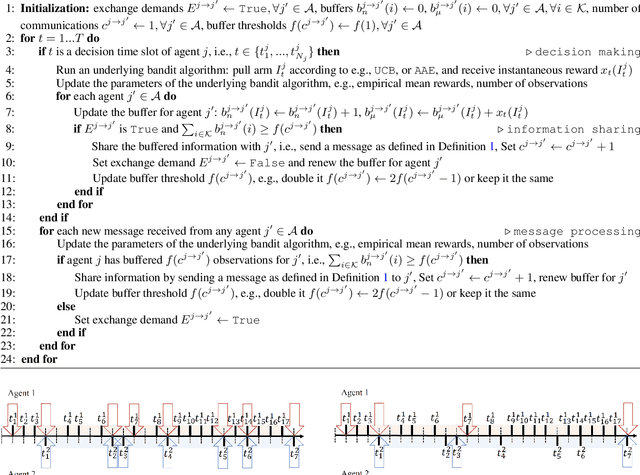


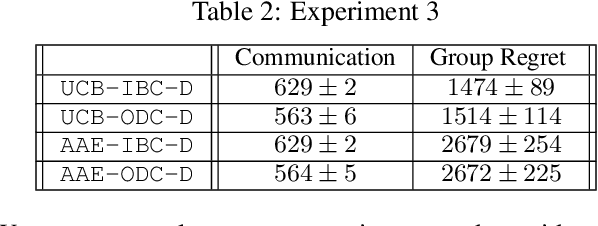
This paper studies a cooperative multi-agent multi-armed stochastic bandit problem where agents operate asynchronously -- agent pull times and rates are unknown, irregular, and heterogeneous -- and face the same instance of a K-armed bandit problem. Agents can share reward information to speed up the learning process at additional communication costs. We propose ODC, an on-demand communication protocol that tailors the communication of each pair of agents based on their empirical pull times. ODC is efficient when the pull times of agents are highly heterogeneous, and its communication complexity depends on the empirical pull times of agents. ODC is a generic protocol that can be integrated into most cooperative bandit algorithms without degrading their performance. We then incorporate ODC into the natural extensions of UCB and AAE algorithms and propose two communication-efficient cooperative algorithms. Our analysis shows that both algorithms are near-optimal in regret.
To Collaborate or Not in Distributed Statistical Estimation with Resource Constraints?
May 31, 2022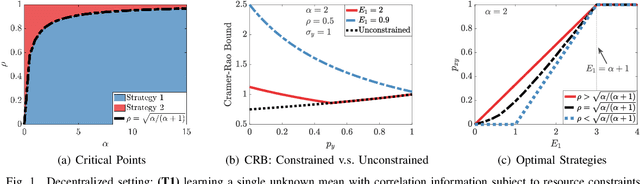
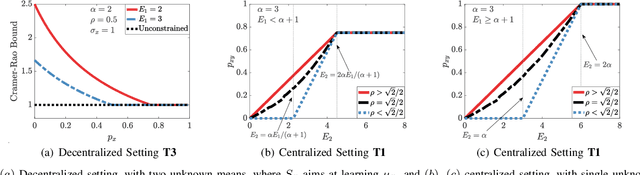

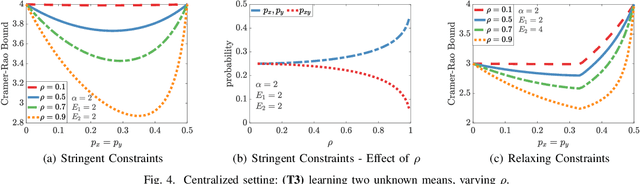
We study how the amount of correlation between observations collected by distinct sensors/learners affects data collection and collaboration strategies by analyzing Fisher information and the Cramer-Rao bound. In particular, we consider a simple setting wherein two sensors sample from a bivariate Gaussian distribution, which already motivates the adoption of various strategies, depending on the correlation between the two variables and resource constraints. We identify two particular scenarios: (1) where the knowledge of the correlation between samples cannot be leveraged for collaborative estimation purposes and (2) where the optimal data collection strategy involves investing scarce resources to collaboratively sample and transfer information that is not of immediate interest and whose statistics are already known, with the sole goal of increasing the confidence on an estimate of the parameter of interest. We discuss two applications, IoT DDoS attack detection and distributed estimation in wireless sensor networks, that may benefit from our results.
Graphlet Count Estimation via Convolutional Neural Networks
Oct 07, 2018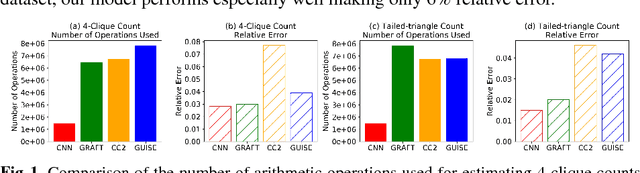
Graphlets are defined as k-node connected induced subgraph patterns. For an undirected graph, 3-node graphlets include close triangle and open triangle. When k = 4, there are six types of graphlets, e.g., tailed-triangle and clique are two possible 4-node graphlets. The number of each graphlet, called graphlet count, is a signature which characterizes the local network structure of a given graph. Graphlet count plays a prominent role in network analysis of many fields, most notably bioinformatics and social science. However, computing exact graphlet count is inherently difficult and computational expensive because the number of graphlets grows exponentially large as the graph size and/or graphlet size k grow. To deal with this difficulty, many sampling methods were proposed to estimate graphlet count with bounded error. Nevertheless, these methods require large number of samples to be statistically reliable, which is still computationally demanding. Moreover, they have to repeat laborious counting procedure even if a new graph is similar or exactly the same as previous studied graphs. Intuitively, learning from historic graphs can make estimation more accurate and avoid many repetitive counting to reduce computational cost. Based on this idea, we propose a convolutional neural network (CNN) framework and two preprocessing techniques to estimate graphlet count. Extensive experiments on two types of random graphs and real world biochemistry graphs show that our framework can offer substantial speedup on estimating graphlet count of new graphs with high accuracy.