 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraphlet Count Estimation via Convolutional Neural Networks
Paper and Code
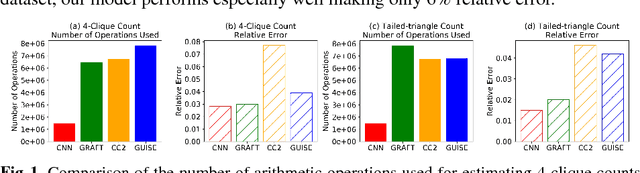
Graphlets are defined as k-node connected induced subgraph patterns. For an undirected graph, 3-node graphlets include close triangle and open triangle. When k = 4, there are six types of graphlets, e.g., tailed-triangle and clique are two possible 4-node graphlets. The number of each graphlet, called graphlet count, is a signature which characterizes the local network structure of a given graph. Graphlet count plays a prominent role in network analysis of many fields, most notably bioinformatics and social science. However, computing exact graphlet count is inherently difficult and computational expensive because the number of graphlets grows exponentially large as the graph size and/or graphlet size k grow. To deal with this difficulty, many sampling methods were proposed to estimate graphlet count with bounded error. Nevertheless, these methods require large number of samples to be statistically reliable, which is still computationally demanding. Moreover, they have to repeat laborious counting procedure even if a new graph is similar or exactly the same as previous studied graphs. Intuitively, learning from historic graphs can make estimation more accurate and avoid many repetitive counting to reduce computational cost. Based on this idea, we propose a convolutional neural network (CNN) framework and two preprocessing techniques to estimate graphlet count. Extensive experiments on two types of random graphs and real world biochemistry graphs show that our framework can offer substantial speedup on estimating graphlet count of new graphs with high accuracy.