 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWAIR-D: Wireless AI Research Dataset
Dec 05, 2022
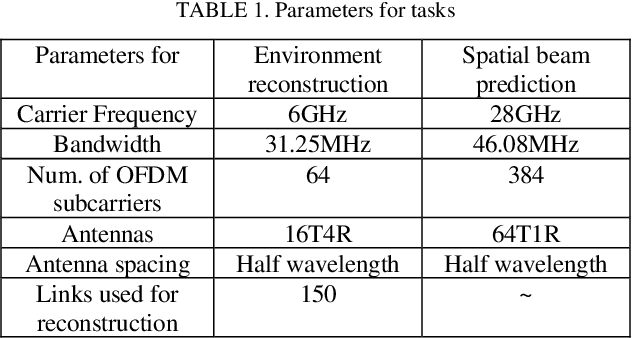


It is a common sense that datasets with high-quality data samples play an important role in artificial intelligence (AI), machine learning (ML) and related studies. However, although AI/ML has been introduced in wireless researches long time ago, few datasets are commonly used in the research community. Without a common dataset, AI-based methods proposed for wireless systems are hard to compare with both the traditional baselines and even each other. The existing wireless AI researches usually rely on datasets generated based on statistical models or ray-tracing simulations with limited environments. The statistical data hinder the trained AI models from further fine-tuning for a specific scenario, and ray-tracing data with limited environments lower down the generalization capability of the trained AI models. In this paper, we present the Wireless AI Research Dataset (WAIR-D)1, which consists of two scenarios. Scenario 1 contains 10,000 environments with sparsely dropped user equipments (UEs), and Scenario 2 contains 100 environments with densely dropped UEs. The environments are randomly picked up from more than 40 cities in the real world map. The large volume of the data guarantees that the trained AI models enjoy good generalization capability, while fine-tuning can be easily carried out on a specific chosen environment. Moreover, both the wireless channels and the corresponding environmental information are provided in WAIR-D, so that extra-information-aided communication mechanism can be designed and evaluated. WAIR-D provides the researchers benchmarks to compare their different designs or reproduce results of others. In this paper, we show the detailed construction of this dataset and examples of using it.
Distributed Learning for Time-varying Networks: A Scalable Design
Jul 31, 2021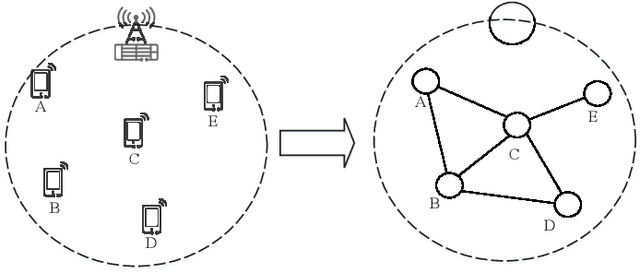
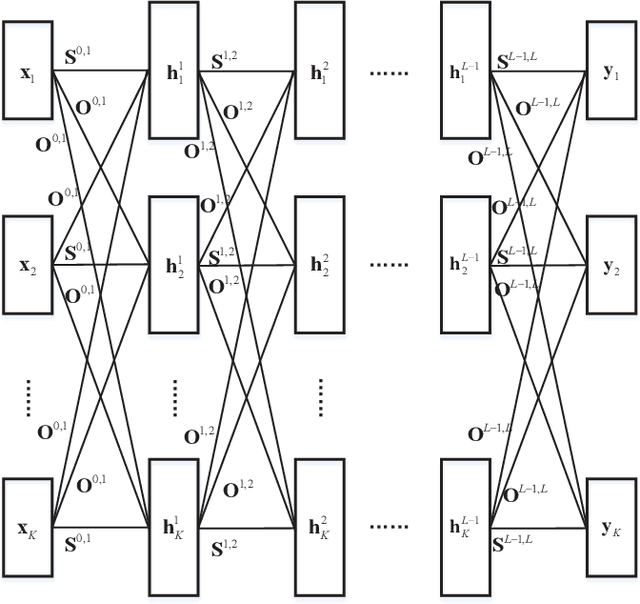
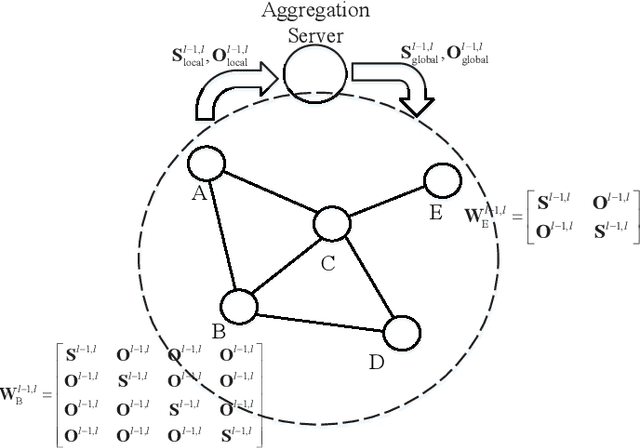
The wireless network is undergoing a trend from "onnection of things" to "connection of intelligence". With data spread over the communication networks and computing capability enhanced on the devices, distributed learning becomes a hot topic in both industrial and academic communities. Many frameworks, such as federated learning and federated distillation, have been proposed. However, few of them takes good care of obstacles such as the time-varying topology resulted by the characteristics of wireless networks. In this paper, we propose a distributed learning framework based on a scalable deep neural network (DNN) design. By exploiting the permutation equivalence and invariance properties of the learning tasks, the DNNs with different scales for different clients can be built up based on two basic parameter sub-matrices. Further, model aggregation can also be conducted based on these two sub-matrices to improve the learning convergence and performance. Finally, simulation results verify the benefits of the proposed framework by compared with some baselines.
Buffer-aware Wireless Scheduling based on Deep Reinforcement Learning
Nov 13, 2019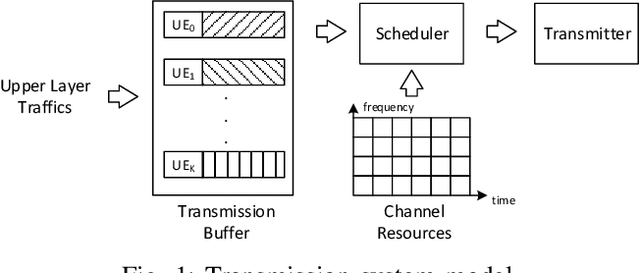
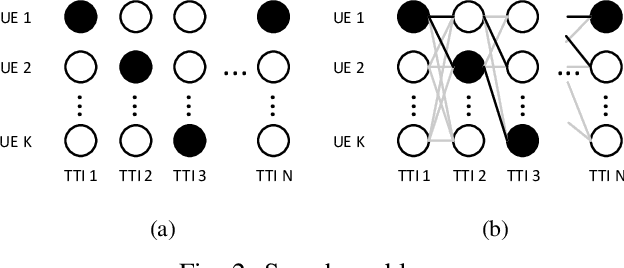
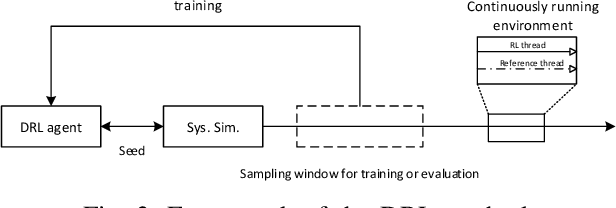
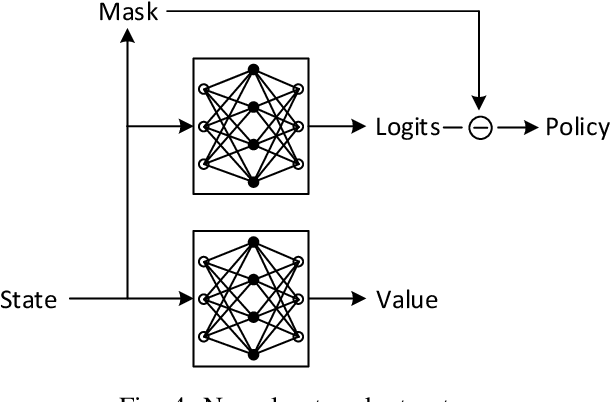
In this paper, the downlink packet scheduling problem for cellular networks is modeled, which jointly optimizes throughput, fairness and packet drop rate. Two genie-aided heuristic search methods are employed to explore the solution space. A deep reinforcement learning (DRL) framework with A2C algorithm is proposed for the optimization problem. Several methods have been utilized in the framework to improve the sampling and training efficiency and to adapt the algorithm to a specific scheduling problem. Numerical results show that DRL outperforms the baseline algorithm and achieves similar performance as genie-aided methods without using the future information.
Realistic Channel Models Pre-training
Jul 22, 2019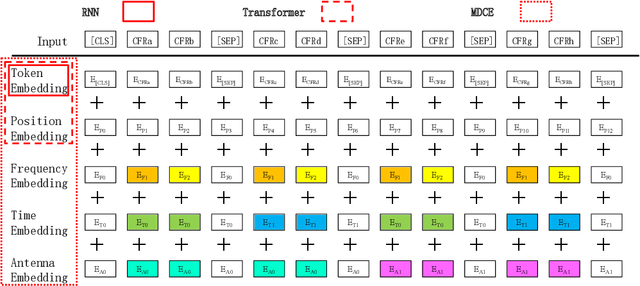
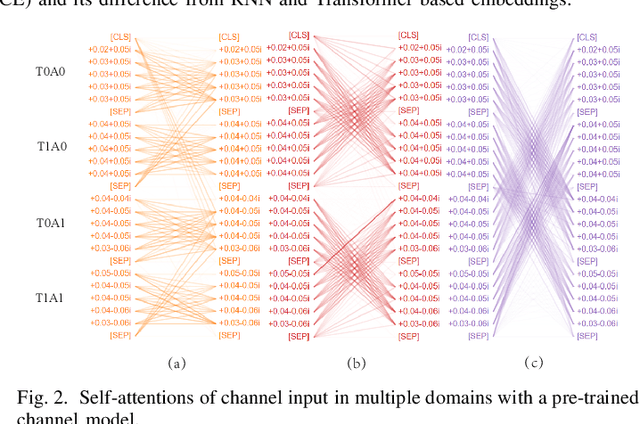
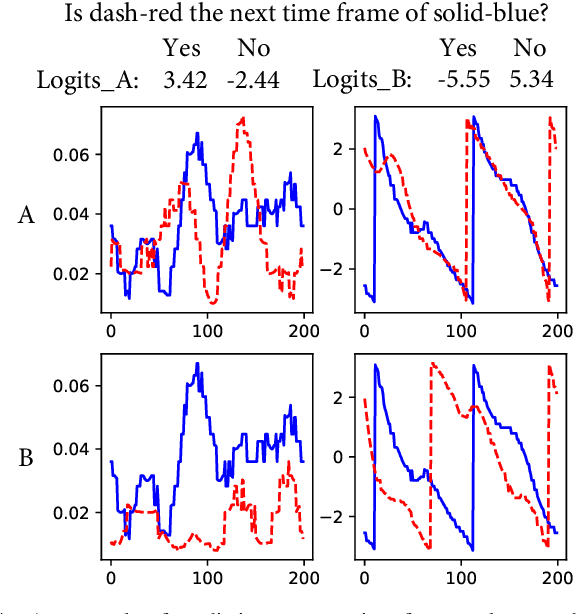
In this paper, we propose a neural-network-based realistic channel model with both the similar accuracy as deterministic channel models and uniformity as stochastic channel models. To facilitate this realistic channel modeling, a multi-domain channel embedding method combined with self-attention mechanism is proposed to extract channel features from multiple domains simultaneously. This 'one model to fit them all' solution employs available wireless channel data as the only data set for self-supervised pre-training. With the permission of users, network operators or other organizations can make use of some available user specific data to fine-tune this pre-trained realistic channel model for applications on channel-related downstream tasks. Moreover, even without fine-tuning, we show that the pre-trained realistic channel model itself is a great tool with its understanding of wireless channel.
Deep Reinforcement Learning for Scheduling in Cellular Networks
May 15, 2019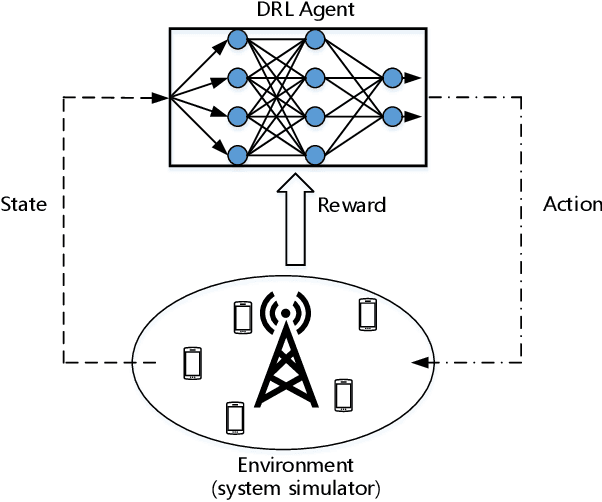
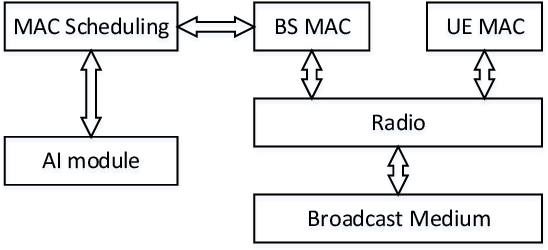
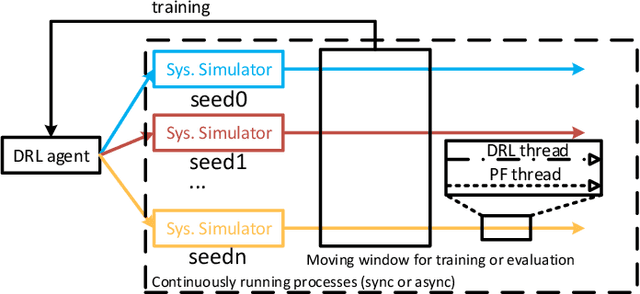
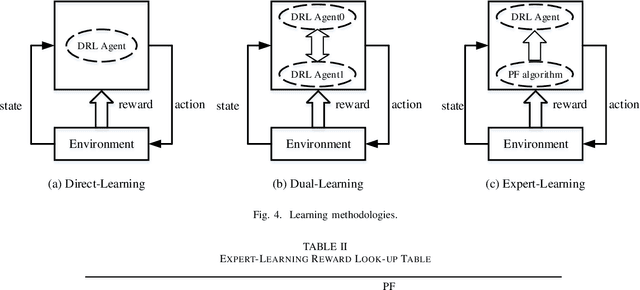
Integrating artificial intelligence (AI) into wireless networks has drawn significant interest in both industry and academia. A common solution is to replace partial or even all modules in the conventional systems, which is often lack of efficiency and robustness due to their ignoring of expert knowledge. In this paper, we take deep reinforcement learning (DRL) based scheduling as an example to investigate how expert knowledge can help with AI module in cellular networks. A simulation platform, which has considered link adaption, feedback and other practical mechanisms, is developed to facilitate the investigation. Besides the traditional way, which is learning directly from the environment, for training DRL agent, we propose two novel methods, i.e., learning from a dual AI module and learning from the expert solution. The results show that, for the considering scheduling problem, DRL training procedure can be improved on both performance and convergence speed by involving the expert knowledge. Hence, instead of replacing conventional scheduling module in the system, adding a newly introduced AI module, which is capable to interact with the conventional module and provide more flexibility, is a more feasible solution.
Learning to Flip Successive Cancellation Decoding of Polar Codes with LSTM Networks
Feb 25, 2019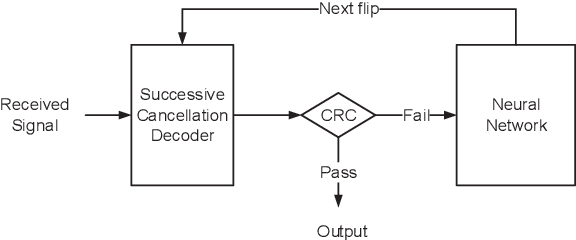
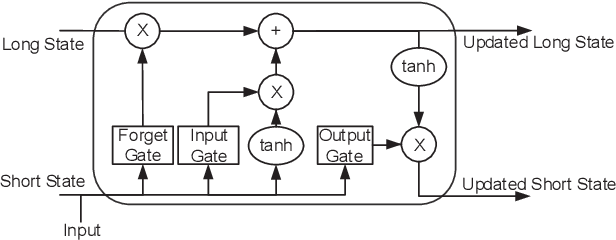
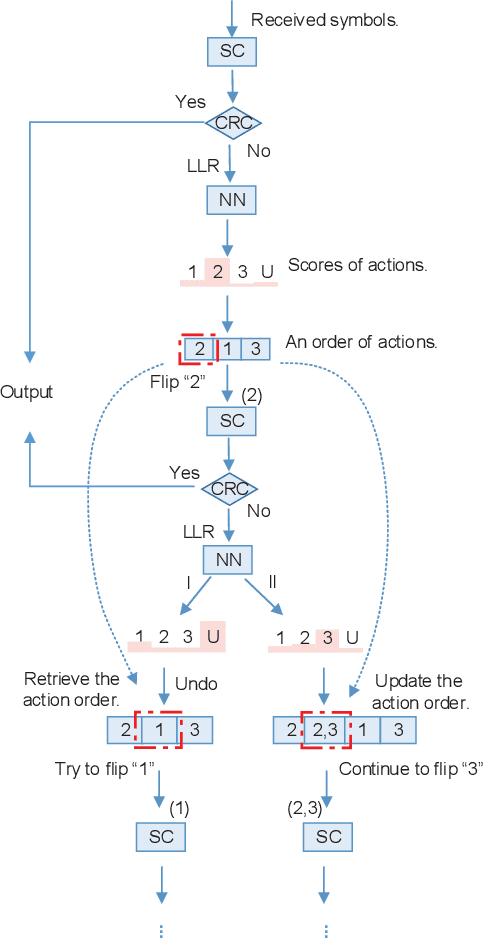
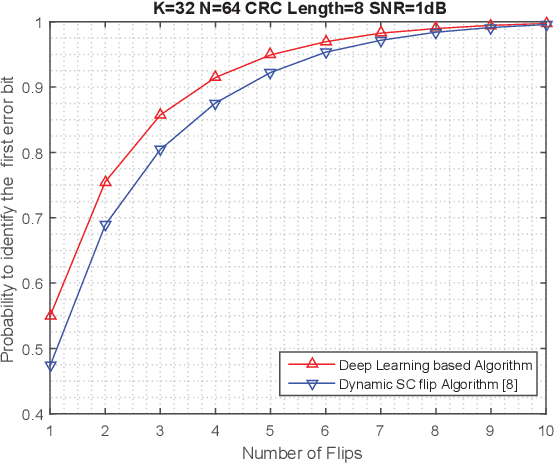
The key to successive cancellation (SC) flip decoding of polar codes is to accurately identify the first error bit. The optimal flipping strategy is considered difficult due to lack of an analytical solution. Alternatively, we propose a deep learning aided SC flip algorithm. Specifically, before each SC decoding attempt, a long short-term memory (LSTM) network is exploited to either (i) locate the first error bit, or (ii) undo a previous `wrong' flip. In each SC attempt, the sequence of log likelihood ratios (LLRs) derived in the previous SC attempt is exploited to decide which action to take. Accordingly, a two-stage training method of the LSTM network is proposed, i.e., learn to locate first error bits in the first stage, and then to undo `wrong' flips in the second stage. Simulation results show that the proposed approach identifies error bits more accurately and achieves better performance than the state-of-the-art SC flip algorithms.