 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning for Nested Polar Code Construction
Apr 16, 2019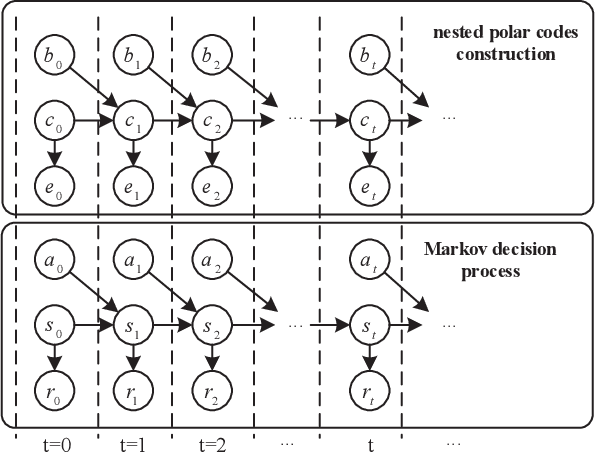
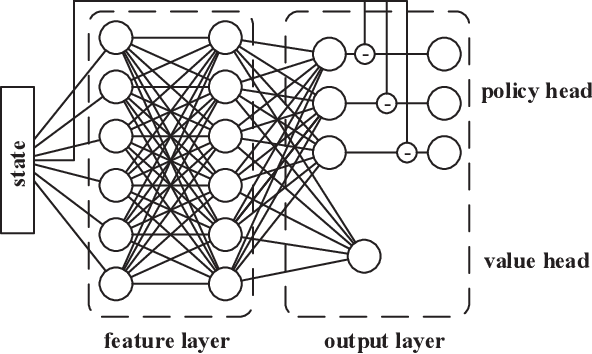
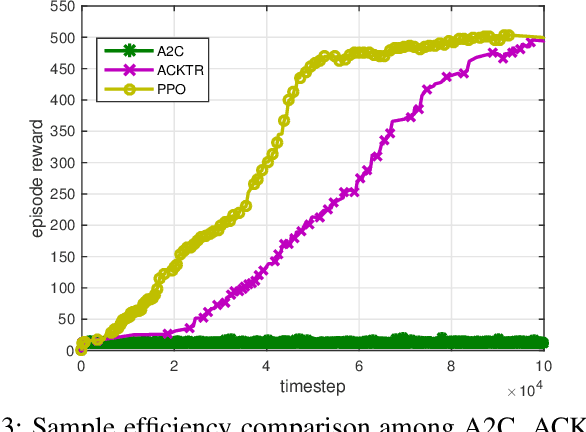
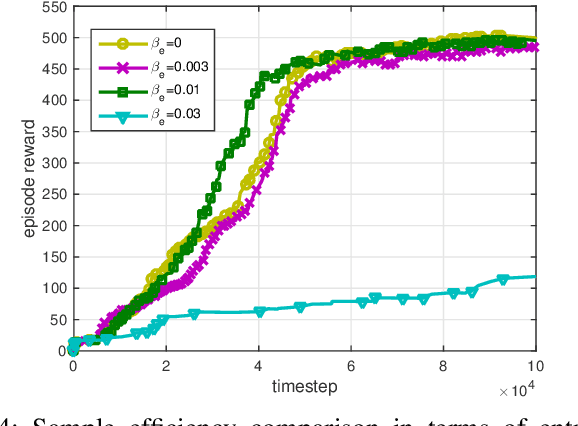
In this paper, we model nested polar code construction as a Markov decision process (MDP), and tackle it with advanced reinforcement learning (RL) techniques. First, an MDP environment with state, action, and reward is defined in the context of polar coding. Specifically, a state represents the construction of an $(N,K)$ polar code, an action specifies its reduction to an $(N,K-1)$ subcode, and reward is the decoding performance. A neural network architecture consisting of both policy and value networks is proposed to generate actions based on the observed states, aiming at maximizing the overall rewards. A loss function is defined to trade off between exploitation and exploration. To further improve learning efficiency and quality, an `integrated learning' paradigm is proposed. It first employs a genetic algorithm to generate a population of (sub-)optimal polar codes for each $(N,K)$, and then uses them as prior knowledge to refine the policy in RL. Such a paradigm is shown to accelerate the training process, and converge at better performances. Simulation results show that the proposed learning-based polar constructions achieve comparable, or even better, performances than the state of the art under successive cancellation list (SCL) decoders. Last but not least, this is achieved without exploiting any expert knowledge from polar coding theory in the learning algorithms.
Learning to Flip Successive Cancellation Decoding of Polar Codes with LSTM Networks
Feb 25, 2019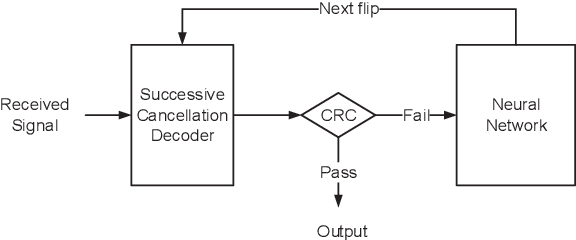
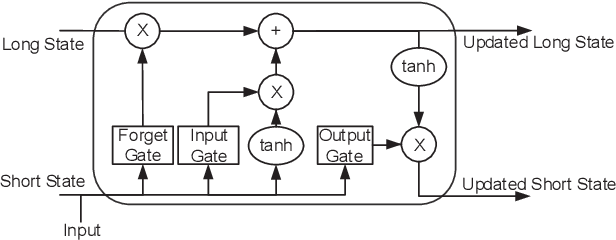
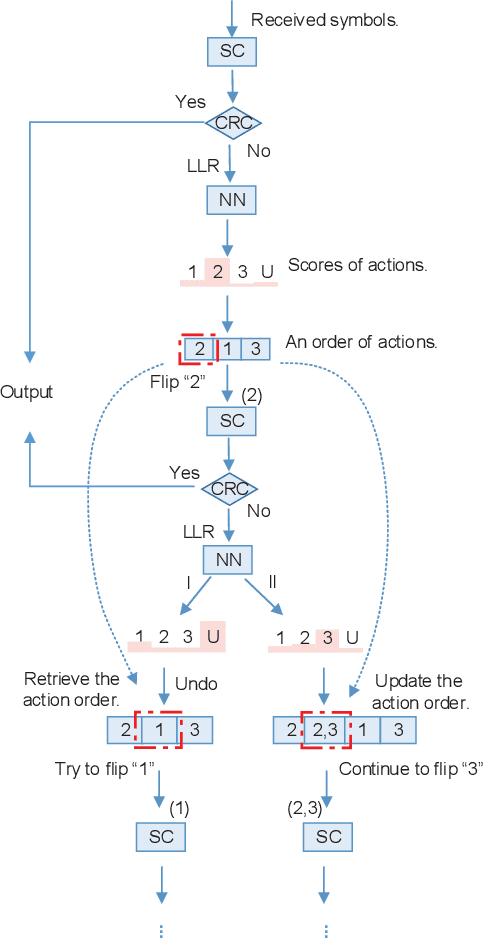
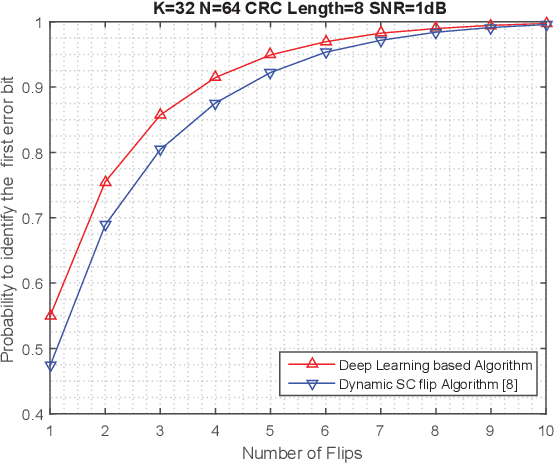
The key to successive cancellation (SC) flip decoding of polar codes is to accurately identify the first error bit. The optimal flipping strategy is considered difficult due to lack of an analytical solution. Alternatively, we propose a deep learning aided SC flip algorithm. Specifically, before each SC decoding attempt, a long short-term memory (LSTM) network is exploited to either (i) locate the first error bit, or (ii) undo a previous `wrong' flip. In each SC attempt, the sequence of log likelihood ratios (LLRs) derived in the previous SC attempt is exploited to decide which action to take. Accordingly, a two-stage training method of the LSTM network is proposed, i.e., learn to locate first error bits in the first stage, and then to undo `wrong' flips in the second stage. Simulation results show that the proposed approach identifies error bits more accurately and achieves better performance than the state-of-the-art SC flip algorithms.