 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFMDA-OT: Federated Multi-source Domain Adaptation Through Optimal Transport
Apr 09, 2024



Multi-source Domain Adaptation (MDA) aims to adapt models trained on multiple labeled source domains to an unlabeled target domain. In this paper, we introduce our approach as a collaborative MDA framework, which comprises two adaptation phases. Firstly, we conduct domain adaptation for each source individually with the target, utilizing optimal transport. Then, in the second phase, which constitutes the final part of the framework, we design the architecture of centralized federated learning to collaborate the N models representing the N sources. This architecture offers the advantage of using the sources without accessing their data, thus resolving data privacy issues inherent in domain adaptation. Additionally, during this phase, the server guides and fine-tunes the adaptation using a small number of pseudo-labeled samples available in the target domain, referred to as the target validation subset of the dataset.
Theoretical Guarantees for Domain Adaptation with Hierarchical Optimal Transport
Oct 24, 2022Domain adaptation arises as an important problem in statistical learning theory when the data-generating processes differ between training and test samples, respectively called source and target domains. Recent theoretical advances show that the success of domain adaptation algorithms heavily relies on their ability to minimize the divergence between the probability distributions of the source and target domains. However, minimizing this divergence cannot be done independently of the minimization of other key ingredients such as the source risk or the combined error of the ideal joint hypothesis. The trade-off between these terms is often ensured by algorithmic solutions that remain implicit and not directly reflected by the theoretical guarantees. To get to the bottom of this issue, we propose in this paper a new theoretical framework for domain adaptation through hierarchical optimal transport. This framework provides more explicit generalization bounds and allows us to consider the natural hierarchical organization of samples in both domains into classes or clusters. Additionally, we provide a new divergence measure between the source and target domains called Hierarchical Wasserstein distance that indicates under mild assumptions, which structures have to be aligned to lead to a successful adaptation.
A quantum learning approach based on Hidden Markov Models for failure scenarios generation
Mar 30, 2022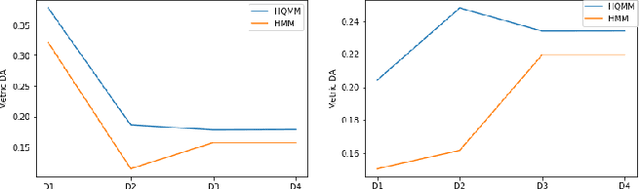
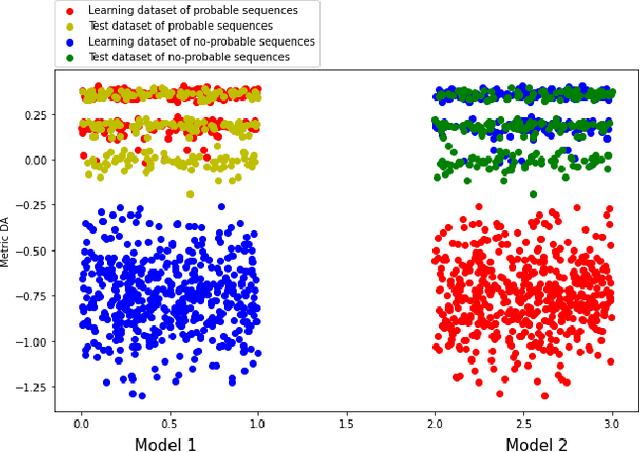

Finding the failure scenarios of a system is a very complex problem in the field of Probabilistic Safety Assessment (PSA). In order to solve this problem we will use the Hidden Quantum Markov Models (HQMMs) to create a generative model. Therefore, in this paper, we will study and compare the results of HQMMs and classical Hidden Markov Models HMM on a real datasets generated from real small systems in the field of PSA. As a quality metric we will use Description accuracy DA and we will show that the quantum approach gives better results compared with the classical approach, and we will give a strategy to identify the probable and no-probable failure scenarios of a system.
Convex Non-negative Matrix Factorization Through Quantum Annealing
Mar 28, 2022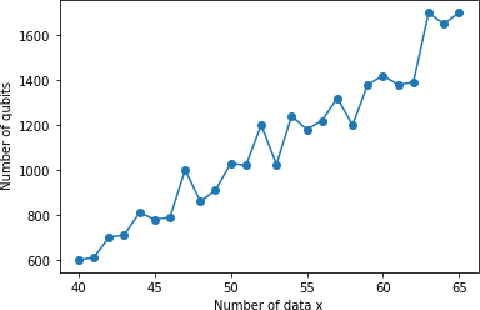

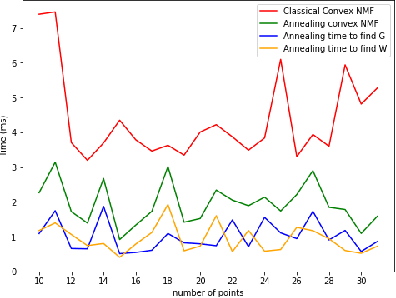
In this paper we provide the quantum version of the Convex Non-negative Matrix Factorization algorithm (Convex-NMF) by using the D-wave quantum annealer. More precisely, we use D-wave 2000Q to find the low rank approximation of a fixed real-valued matrix X by the product of two non-negative matrices factors W and G such that the Frobenius norm of the difference X-XWG is minimized. In order to solve this optimization problem we proceed in two steps. In the first step we transform the global real optimization problem depending on W,G into two quadratic unconstrained binary optimization problems (QUBO) depending on W and G respectively. In the second step we use an alternative strategy between the two QUBO problems corresponding to W and G to find the global solution. The running of these two QUBO problems on D-wave 2000Q need to use an embedding to the chimera graph of D-wave 2000Q, this embedding is limited by the number of qubits of D-wave 2000Q. We perform a study on the maximum number of real data to be used by our approach on D-wave 2000Q. The proposed study is based on the number of qubits used to represent each real variable. We also tested our approach on D-Wave 2000Q with several randomly generated data sets to prove that our approach is faster than the classical approach and also to prove that it gets the best results.
Inductive Semi-supervised Learning Through Optimal Transport
Dec 14, 2021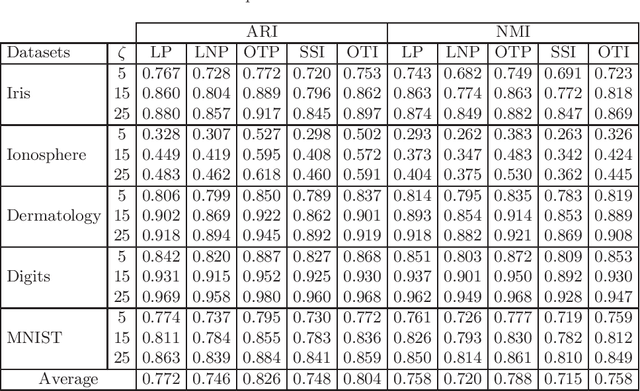
In this paper, we tackle the inductive semi-supervised learning problem that aims to obtain label predictions for out-of-sample data. The proposed approach, called Optimal Transport Induction (OTI), extends efficiently an optimal transport based transductive algorithm (OTP) to inductive tasks for both binary and multi-class settings. A series of experiments are conducted on several datasets in order to compare the proposed approach with state-of-the-art methods. Experiments demonstrate the effectiveness of our approach. We make our code publicly available (Code is available at: https://github.com/MouradElHamri/OTI).
Hierarchical Optimal Transport for Unsupervised Domain Adaptation
Dec 03, 2021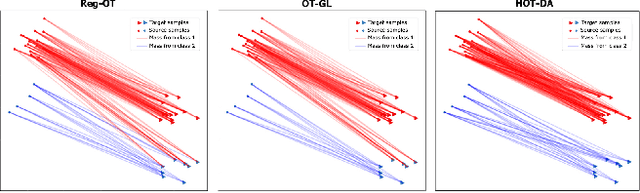
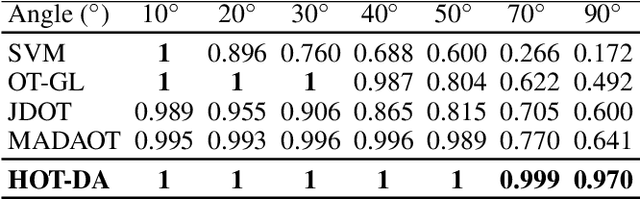
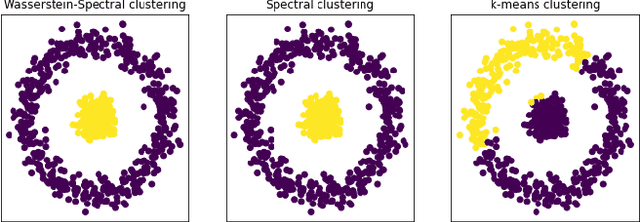
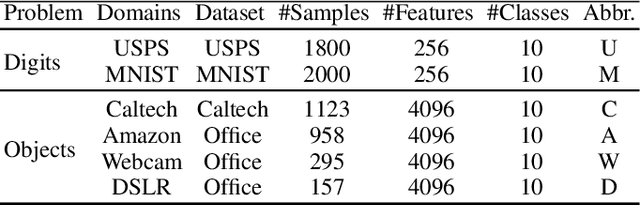
In this paper, we propose a novel approach for unsupervised domain adaptation, that relates notions of optimal transport, learning probability measures and unsupervised learning. The proposed approach, HOT-DA, is based on a hierarchical formulation of optimal transport, that leverages beyond the geometrical information captured by the ground metric, richer structural information in the source and target domains. The additional information in the labeled source domain is formed instinctively by grouping samples into structures according to their class labels. While exploring hidden structures in the unlabeled target domain is reduced to the problem of learning probability measures through Wasserstein barycenter, which we prove to be equivalent to spectral clustering. Experiments on a toy dataset with controllable complexity and two challenging visual adaptation datasets show the superiority of the proposed approach over the state-of-the-art.
Label Propagation Through Optimal Transport
Oct 01, 2021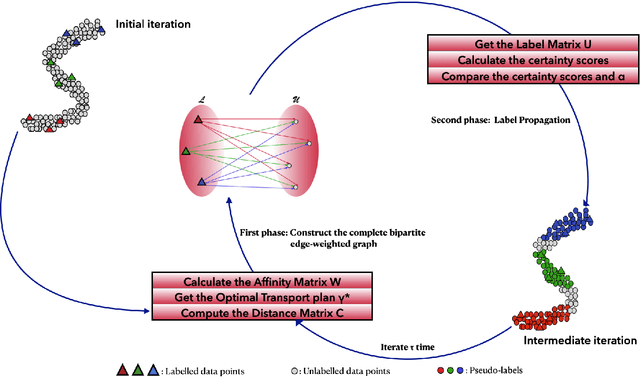


In this paper, we tackle the transductive semi-supervised learning problem that aims to obtain label predictions for the given unlabeled data points according to Vapnik's principle. Our proposed approach is based on optimal transport, a mathematical theory that has been successfully used to address various machine learning problems, and is starting to attract renewed interest in semi-supervised learning community. The proposed approach, Optimal Transport Propagation (OTP), performs in an incremental process, label propagation through the edges of a complete bipartite edge-weighted graph, whose affinity matrix is constructed from the optimal transport plan between empirical measures defined on labeled and unlabeled data. OTP ensures a high degree of predictions certitude by controlling the propagation process using a certainty score based on Shannon's entropy. We also provide a convergence analysis of our algorithm. Experiments task show the superiority of the proposed approach over the state-of-the-art. We make our code publicly available.
* arXiv admin note: text overlap with arXiv:2103.11937
On the use of Wasserstein metric in topological clustering of distributional data
Sep 09, 2021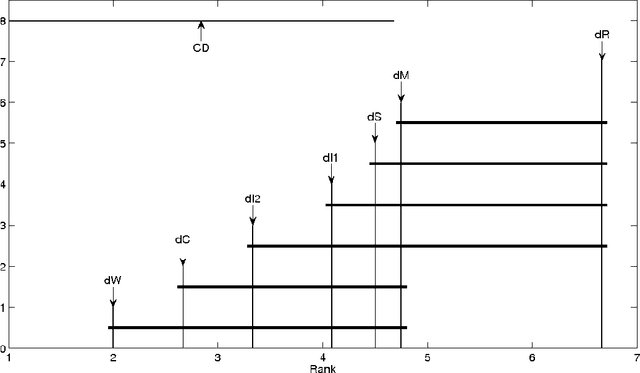
This paper deals with a clustering algorithm for histogram data based on a Self-Organizing Map (SOM) learning. It combines a dimension reduction by SOM and the clustering of the data in a reduced space. Related to the kind of data, a suitable dissimilarity measure between distributions is introduced: the $L_2$ Wasserstein distance. Moreover, the number of clusters is not fixed in advance but it is automatically found according to a local data density estimation in the original space. Applications on synthetic and real data sets corroborate the proposed strategy.
Regularized Optimal Transport for Dynamic Semi-supervised Learning
Mar 25, 2021



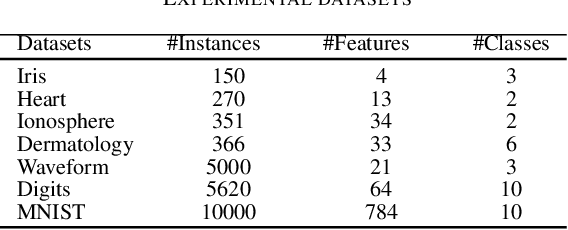
Semi-supervised learning provides an effective paradigm for leveraging unlabeled data to improve a model's performance. Among the many strategies proposed, graph-based methods have shown excellent properties, in particular since they allow to solve directly the transductive tasks according to Vapnik's principle and they can be extended efficiently for inductive tasks. In this paper, we propose a novel approach for the transductive semi-supervised learning, using a complete bipartite edge-weighted graph. The proposed approach uses the regularized optimal transport between empirical measures defined on labelled and unlabelled data points in order to obtain an affinity matrix from the optimal transport plan. This matrix is further used to propagate labels through the vertices of the graph in an incremental process ensuring the certainty of the predictions by incorporating a certainty score based on Shannon's entropy. We also analyze the convergence of our approach and we derive an efficient way to extend it for out-of-sample data. Experimental analysis was used to compare the proposed approach with other label propagation algorithms on 12 benchmark datasets, for which we surpass state-of-the-art results. We release our code.
Selective information exchange in collaborative clustering using regularized Optimal Transport
Mar 25, 2021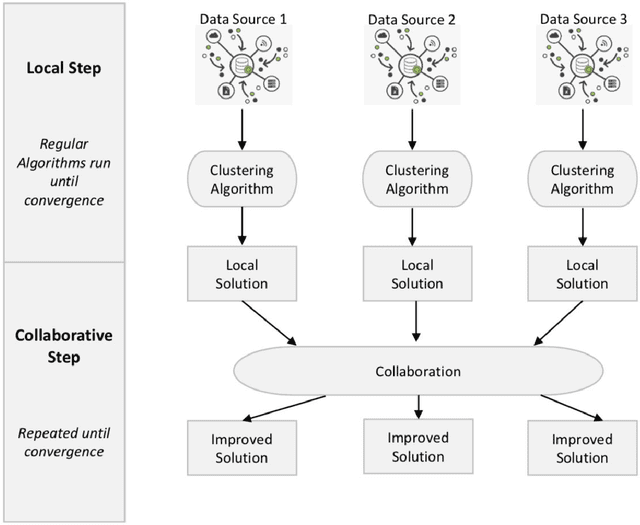
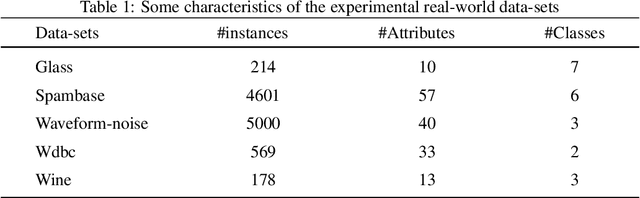
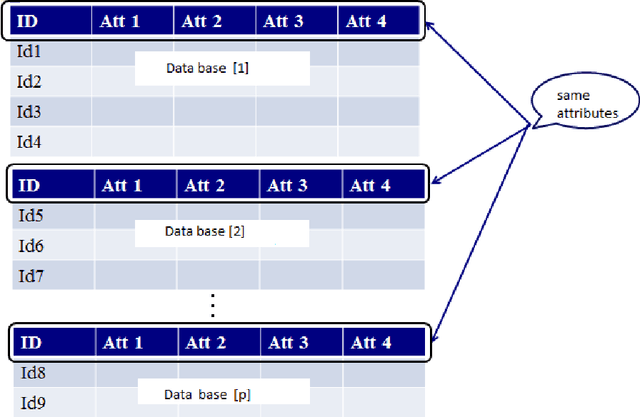
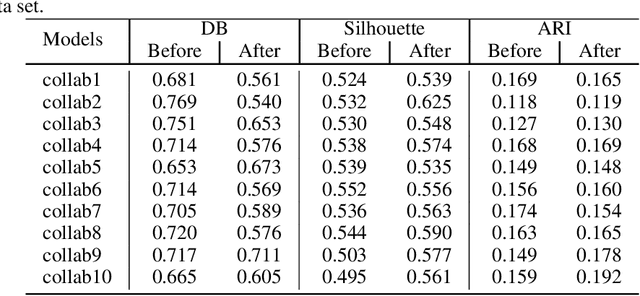
Collaborative learning has recently achieved very significant results. It still suffers, however, from several issues, including the type of information that needs to be exchanged, the criteria for stopping and how to choose the right collaborators. We aim in this paper to improve the quality of the collaboration and to resolve these issues via a novel approach inspired by Optimal Transport theory. More specifically, the objective function for the exchange of information is based on the Wasserstein distance, with a bidirectional transport of information between collaborators. This formulation allows to learns a stopping criterion and provide a criterion to choose the best collaborators. Extensive experiments are conducted on multiple data-sets to evaluate the proposed approach.