Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the use of Wasserstein metric in topological clustering of distributional data
Paper and Code
Sep 09, 2021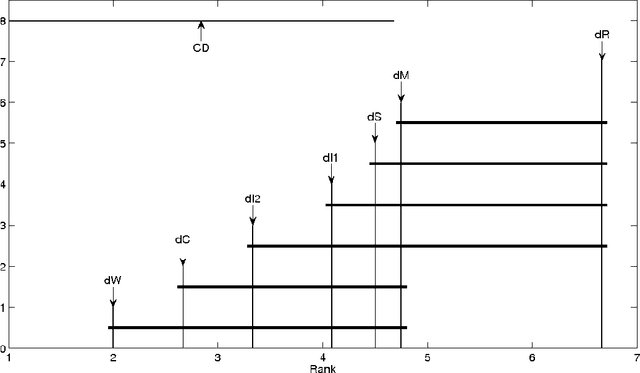
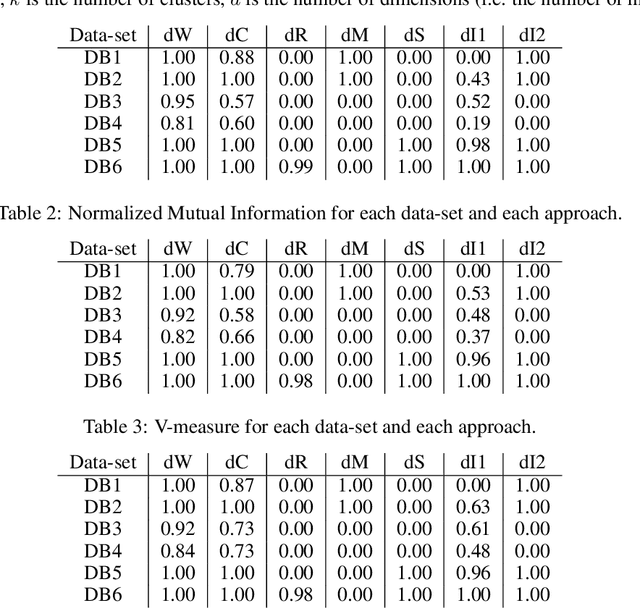
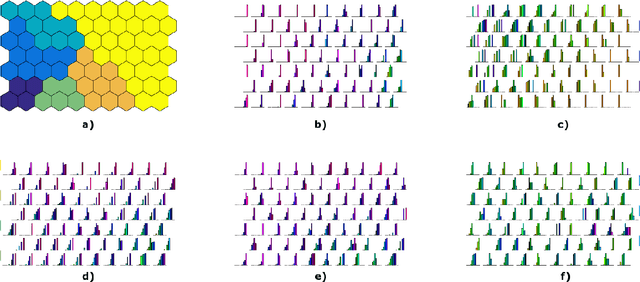
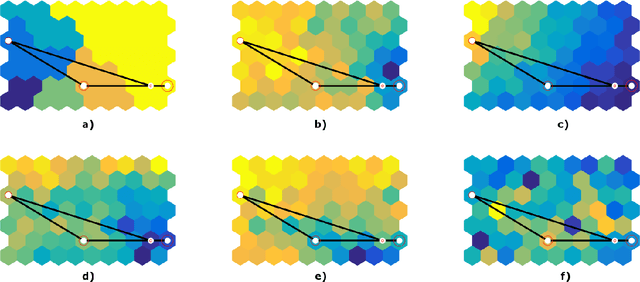
This paper deals with a clustering algorithm for histogram data based on a Self-Organizing Map (SOM) learning. It combines a dimension reduction by SOM and the clustering of the data in a reduced space. Related to the kind of data, a suitable dissimilarity measure between distributions is introduced: the $L_2$ Wasserstein distance. Moreover, the number of clusters is not fixed in advance but it is automatically found according to a local data density estimation in the original space. Applications on synthetic and real data sets corroborate the proposed strategy.
View paper on