 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Submodular Function Maximization
May 15, 2023Submodular functions have many real-world applications, such as document summarization, sensor placement, and image segmentation. For all these applications, the key building block is how to compute the maximum value of a submodular function efficiently. We consider both the online and offline versions of the problem: in each iteration, the data set changes incrementally or is not changed, and a user can issue a query to maximize the function on a given subset of the data. The user can be malicious, issuing queries based on previous query results to break the competitive ratio for the online algorithm. Today, the best-known algorithm for online submodular function maximization has a running time of $O(n k d^2)$ where $n$ is the total number of elements, $d$ is the feature dimension and $k$ is the number of elements to be selected. We propose a new method based on a novel search tree data structure. Our algorithm only takes $\widetilde{O}(nk + kd^2 + nd)$ time.
A Unified Framework of Policy Learning for Contextual Bandit with Confounding Bias and Missing Observations
Mar 20, 2023We study the offline contextual bandit problem, where we aim to acquire an optimal policy using observational data. However, this data usually contains two deficiencies: (i) some variables that confound actions are not observed, and (ii) missing observations exist in the collected data. Unobserved confounders lead to a confounding bias and missing observations cause bias and inefficiency problems. To overcome these challenges and learn the optimal policy from the observed dataset, we present a new algorithm called Causal-Adjusted Pessimistic (CAP) policy learning, which forms the reward function as the solution of an integral equation system, builds a confidence set, and greedily takes action with pessimism. With mild assumptions on the data, we develop an upper bound to the suboptimality of CAP for the offline contextual bandit problem.
Sketching for First Order Method: Efficient Algorithm for Low-Bandwidth Channel and Vulnerability
Oct 15, 2022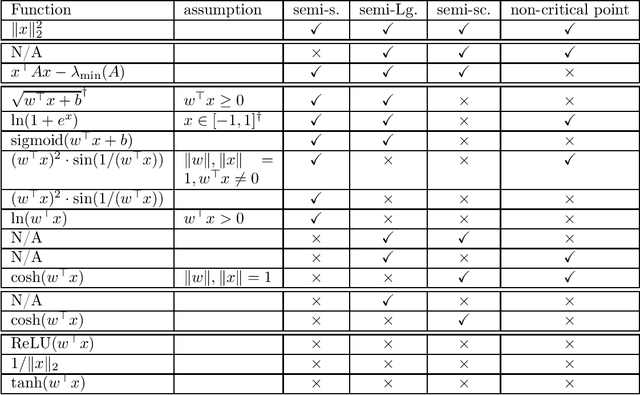
Sketching is one of the most fundamental tools in large-scale machine learning. It enables runtime and memory saving via randomly compressing the original large problem onto lower dimensions. In this paper, we propose a novel sketching scheme for the first order method in large-scale distributed learning setting, such that the communication costs between distributed agents are saved while the convergence of the algorithms is still guaranteed. Given gradient information in a high dimension $d$, the agent passes the compressed information processed by a sketching matrix $R\in \R^{s\times d}$ with $s\ll d$, and the receiver de-compressed via the de-sketching matrix $R^\top$ to ``recover'' the information in original dimension. Using such a framework, we develop algorithms for federated learning with lower communication costs. However, such random sketching does not protect the privacy of local data directly. We show that the gradient leakage problem still exists after applying the sketching technique by showing a specific gradient attack method. As a remedy, we prove rigorously that the algorithm will be differentially private by adding additional random noises in gradient information, which results in a both communication-efficient and differentially private first order approach for federated learning tasks. Our sketching scheme can be further generalized to other learning settings and might be of independent interest itself.
A Sublinear Adversarial Training Algorithm
Aug 10, 2022Adversarial training is a widely used strategy for making neural networks resistant to adversarial perturbations. For a neural network of width $m$, $n$ input training data in $d$ dimension, it takes $\Omega(mnd)$ time cost per training iteration for the forward and backward computation. In this paper we analyze the convergence guarantee of adversarial training procedure on a two-layer neural network with shifted ReLU activation, and shows that only $o(m)$ neurons will be activated for each input data per iteration. Furthermore, we develop an algorithm for adversarial training with time cost $o(m n d)$ per iteration by applying half-space reporting data structure.
Interpolatron: Interpolation or Extrapolation Schemes to Accelerate Optimization for Deep Neural Networks
May 17, 2018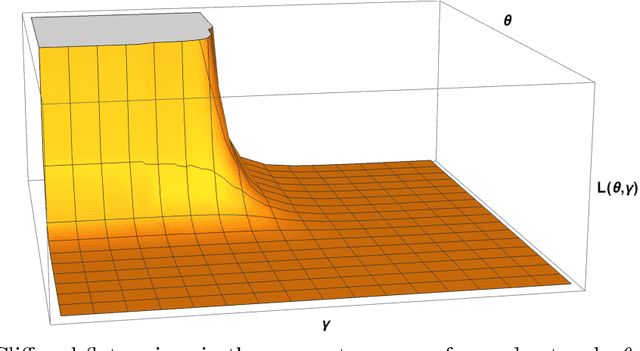
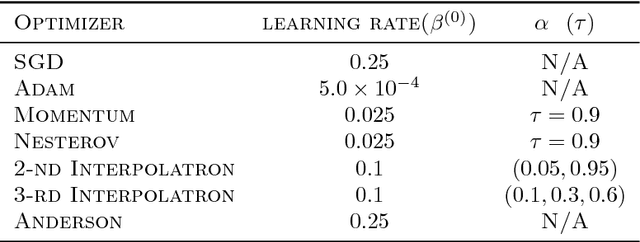
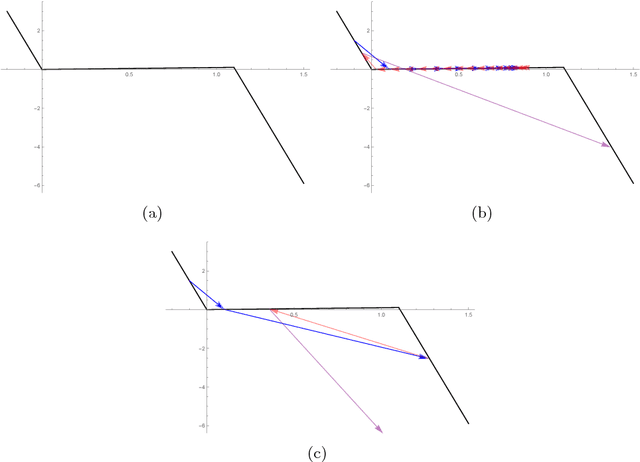
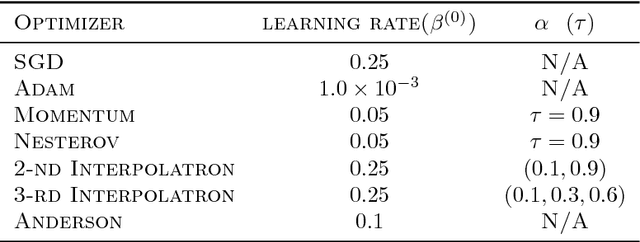
In this paper we explore acceleration techniques for large scale nonconvex optimization problems with special focuses on deep neural networks. The extrapolation scheme is a classical approach for accelerating stochastic gradient descent for convex optimization, but it does not work well for nonconvex optimization typically. Alternatively, we propose an interpolation scheme to accelerate nonconvex optimization and call the method Interpolatron. We explain motivation behind Interpolatron and conduct a thorough empirical analysis. Empirical results on DNNs of great depths (e.g., 98-layer ResNet and 200-layer ResNet) on CIFAR-10 and ImageNet show that Interpolatron can converge much faster than the state-of-the-art methods such as the SGD with momentum and Adam. Furthermore, Anderson's acceleration, in which mixing coefficients are computed by least-squares estimation, can also be used to improve the performance. Both Interpolatron and Anderson's acceleration are easy to implement and tune. We also show that Interpolatron has linear convergence rate under certain regularity assumptions.