 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Legibility in Multiagent Reinforcement Learning
Oct 28, 2024



A multiagent sequential decision problem has been seen in many critical applications including urban transportation, autonomous driving cars, military operations, etc. Its widely known solution, namely multiagent reinforcement learning, has evolved tremendously in recent years. Among them, the solution paradigm of modeling other agents attracts our interest, which is different from traditional value decomposition or communication mechanisms. It enables agents to understand and anticipate others' behaviors and facilitates their collaboration. Inspired by recent research on the legibility that allows agents to reveal their intentions through their behavior, we propose a multiagent active legibility framework to improve their performance. The legibility-oriented framework allows agents to conduct legible actions so as to help others optimise their behaviors. In addition, we design a series of problem domains that emulate a common scenario and best characterize the legibility in multiagent reinforcement learning. The experimental results demonstrate that the new framework is more efficient and costs less training time compared to several multiagent reinforcement learning algorithms.
Inducing Individual Students' Learning Strategies through Homomorphic POMDPs
Mar 16, 2024Optimizing students' learning strategies is a crucial component in intelligent tutoring systems. Previous research has demonstrated the effectiveness of devising personalized learning strategies for students by modelling their learning processes through partially observable Markov decision process (POMDP). However, the research holds the assumption that the student population adheres to a uniform cognitive pattern. While this assumption simplifies the POMDP modelling process, it evidently deviates from a real-world scenario, thus reducing the precision of inducing individual students' learning strategies. In this article, we propose the homomorphic POMDP (H-POMDP) model to accommodate multiple cognitive patterns and present the parameter learning approach to automatically construct the H-POMDP model. Based on the H-POMDP model, we are able to represent different cognitive patterns from the data and induce more personalized learning strategies for individual students. We conduct experiments to show that, in comparison to the general POMDP approach, the H-POMDP model demonstrates better precision when modelling mixed data from multiple cognitive patterns. Moreover, the learning strategies derived from H-POMDPs exhibit better personalization in the performance evaluation.
Diversifying Agent's Behaviors in Interactive Decision Models
Mar 06, 2022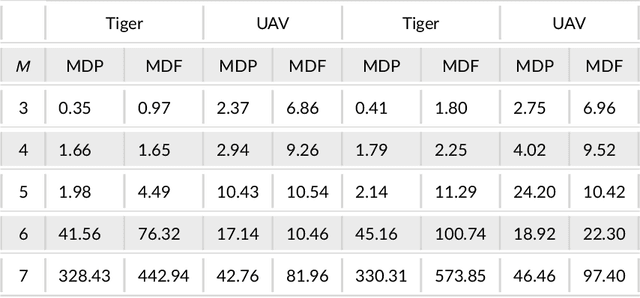
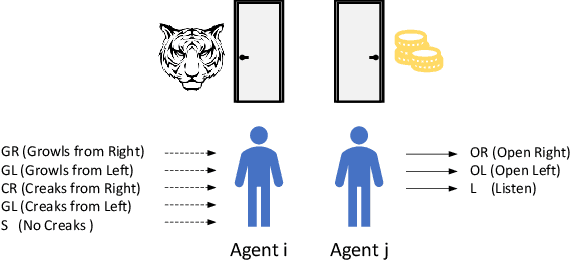
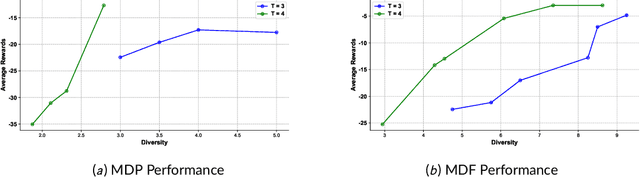
Modelling other agents' behaviors plays an important role in decision models for interactions among multiple agents. To optimise its own decisions, a subject agent needs to model what other agents act simultaneously in an uncertain environment. However, modelling insufficiency occurs when the agents are competitive and the subject agent can not get full knowledge about other agents. Even when the agents are collaborative, they may not share their true behaviors due to their privacy concerns. In this article, we investigate into diversifying behaviors of other agents in the subject agent's decision model prior to their interactions. Starting with prior knowledge about other agents' behaviors, we use a linear reduction technique to extract representative behavioral features from the known behaviors. We subsequently generate their new behaviors by expanding the features and propose two diversity measurements to select top-K behaviors. We demonstrate the performance of the new techniques in two well-studied problem domains. This research will contribute to intelligent systems dealing with unknown unknowns in an open artificial intelligence world.
Intention Recognition for Multiple Agents
Dec 05, 2021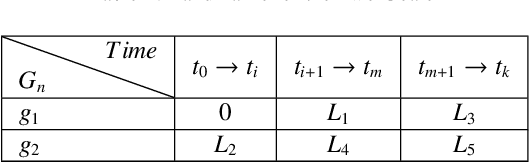
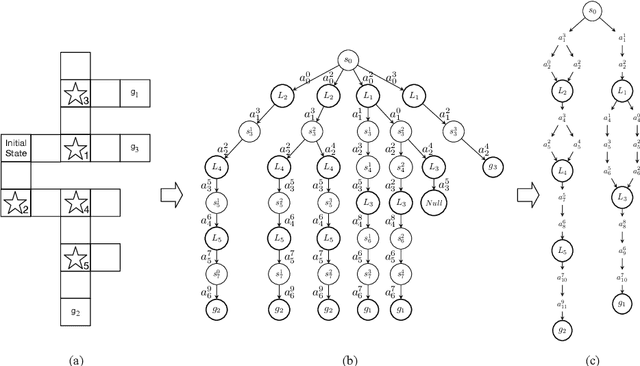
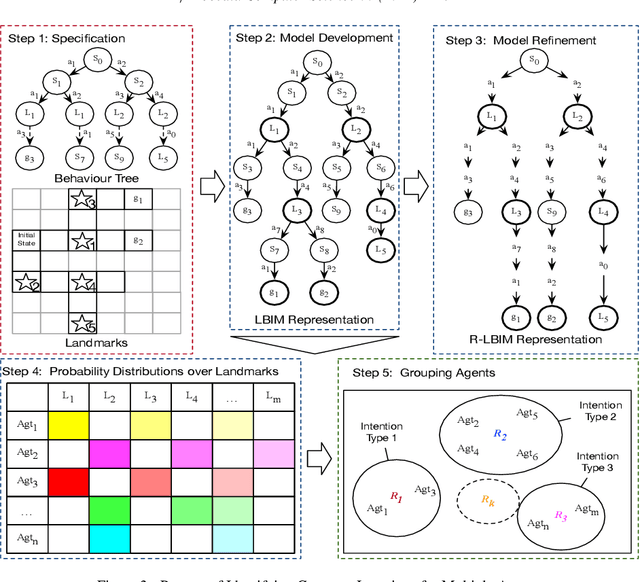
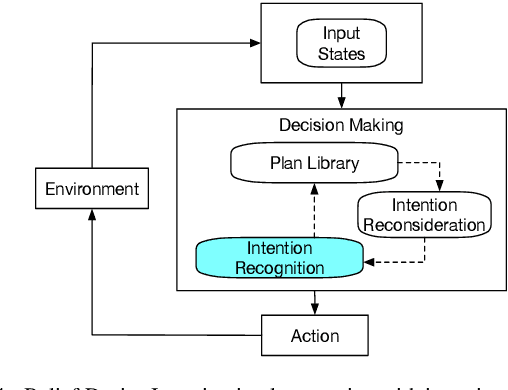
Intention recognition is an important step to facilitate collaboration in multi-agent systems. Existing work mainly focuses on intention recognition in a single-agent setting and uses a descriptive model, e.g. Bayesian networks, in the recognition process. In this paper, we resort to a prescriptive approach to model agents' behaviour where which their intentions are hidden in implementing their plans. We introduce landmarks into the behavioural model therefore enhancing informative features for identifying common intentions for multiple agents. We further refine the model by focusing only action sequences in their plan and provide a light model for identifying and comparing their intentions. The new models provide a simple approach of grouping agents' common intentions upon partial plans observed in agents' interactions. We provide experimental results in support.
Tensor Decomposition for Multi-agent Predictive State Representation
May 27, 2020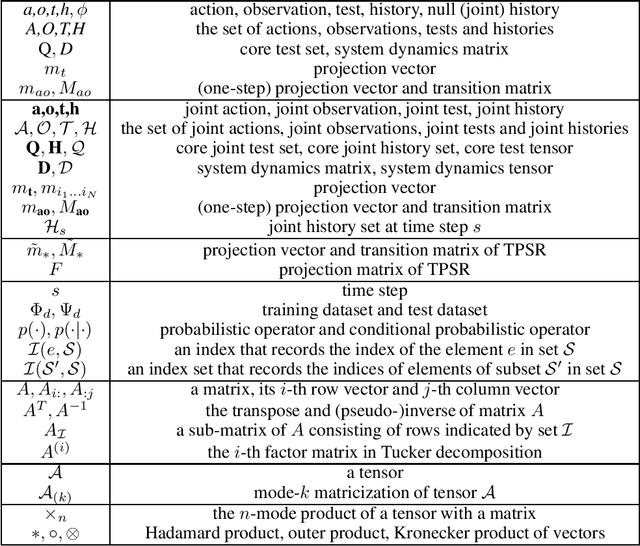
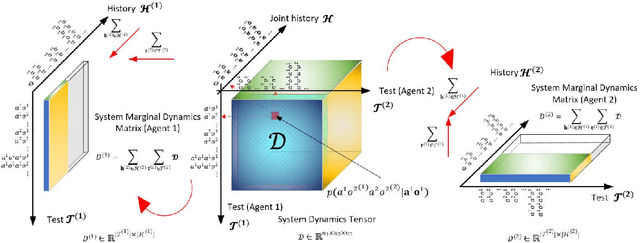
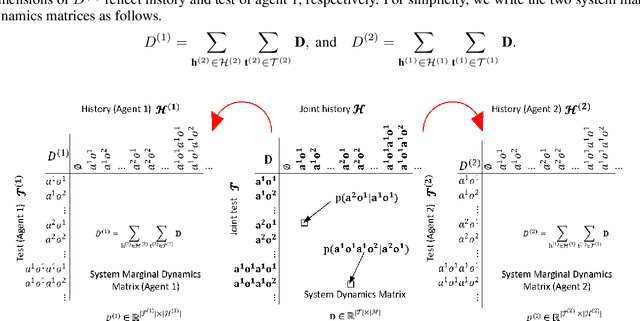

Predictive state representation~(PSR) uses a vector of action-observation sequence to represent the system dynamics and subsequently predicts the probability of future events. It is a concise knowledge representation that is well studied in a single-agent planning problem domain. To the best of our knowledge, there is no existing work on using PSR to solve multi-agent planning problems. Learning a multi-agent PSR model is quite difficult especially with the increasing number of agents, not to mention the complexity of a problem domain. In this paper, we resort to tensor techniques to tackle the challenging task of multi-agent PSR model development problems. By first focusing on a two-agent setting, we construct the system dynamics matrix as a high order tensor for a PSR model, learn the prediction parameters and deduce state vectors directly through two different tensor decomposition methods respectively, and derive the transition parameters via linear regression. Subsequently, we generalize the PSR learning approaches in a multi-agent setting. Experimental results show that our methods can effectively solve multi-agent PSR modelling problems in multiple problem domains.
Team Behavior in Interactive Dynamic Influence Diagrams with Applications to Ad Hoc Teams
Sep 01, 2014

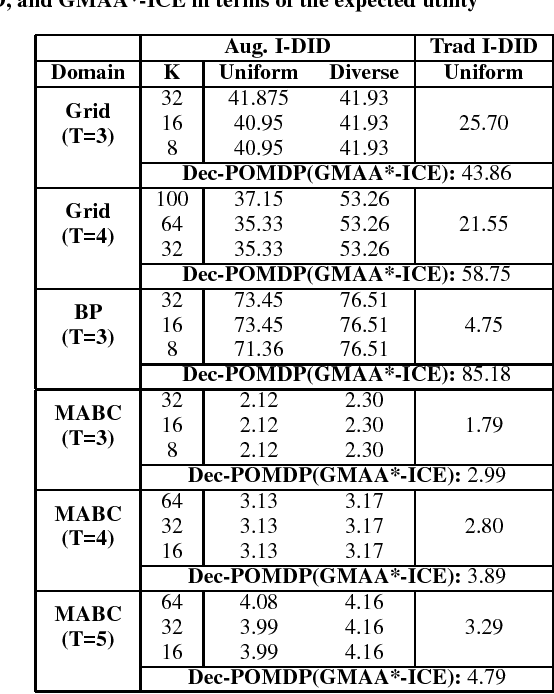
Planning for ad hoc teamwork is challenging because it involves agents collaborating without any prior coordination or communication. The focus is on principled methods for a single agent to cooperate with others. This motivates investigating the ad hoc teamwork problem in the context of individual decision making frameworks. However, individual decision making in multiagent settings faces the task of having to reason about other agents' actions, which in turn involves reasoning about others. An established approximation that operationalizes this approach is to bound the infinite nesting from below by introducing level 0 models. We show that a consequence of the finitely-nested modeling is that we may not obtain optimal team solutions in cooperative settings. We address this limitation by including models at level 0 whose solutions involve learning. We demonstrate that the learning integrated into planning in the context of interactive dynamic influence diagrams facilitates optimal team behavior, and is applicable to ad hoc teamwork.
Exploiting Model Equivalences for Solving Interactive Dynamic Influence Diagrams
Jan 18, 2014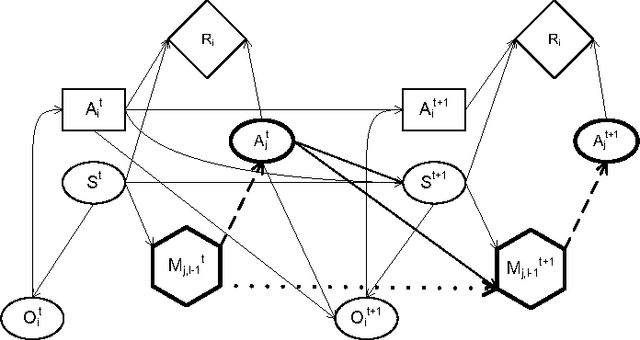
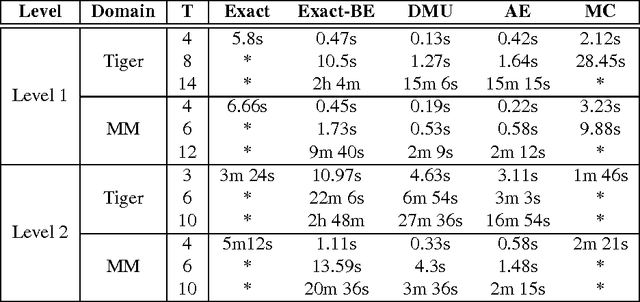
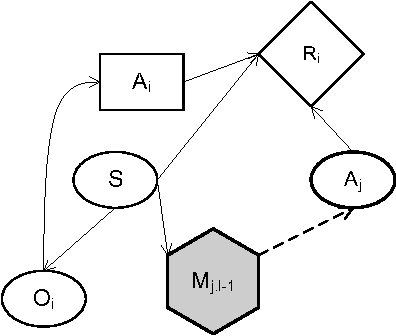
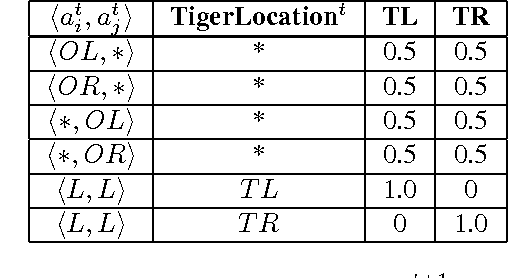
We focus on the problem of sequential decision making in partially observable environments shared with other agents of uncertain types having similar or conflicting objectives. This problem has been previously formalized by multiple frameworks one of which is the interactive dynamic influence diagram (I-DID), which generalizes the well-known influence diagram to the multiagent setting. I-DIDs are graphical models and may be used to compute the policy of an agent given its belief over the physical state and others models, which changes as the agent acts and observes in the multiagent setting. As we may expect, solving I-DIDs is computationally hard. This is predominantly due to the large space of candidate models ascribed to the other agents and its exponential growth over time. We present two methods for reducing the size of the model space and stemming its exponential growth. Both these methods involve aggregating individual models into equivalence classes. Our first method groups together behaviorally equivalent models and selects only those models for updating which will result in predictive behaviors that are distinct from others in the updated model space. The second method further compacts the model space by focusing on portions of the behavioral predictions. Specifically, we cluster actionally equivalent models that prescribe identical actions at a single time step. Exactly identifying the equivalences would require us to solve all models in the initial set. We avoid this by selectively solving some of the models, thereby introducing an approximation. We discuss the error introduced by the approximation, and empirically demonstrate the improved efficiency in solving I-DIDs due to the equivalences.