 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCGPT: Cluster-Guided Partial Tables with LLM-Generated Supervision for Table Retrieval
Jan 22, 2026General-purpose embedding models have demonstrated strong performance in text retrieval but remain suboptimal for table retrieval, where highly structured content leads to semantic compression and query-table mismatch. Recent LLM-based retrieval augmentation methods mitigate this issue by generating synthetic queries, yet they often rely on heuristic partial-table selection and seldom leverage these synthetic queries as supervision to improve the embedding model. We introduce CGPT, a training framework that enhances table retrieval through LLM-generated supervision. CGPT constructs semantically diverse partial tables by clustering table instances using K-means and sampling across clusters to broaden semantic coverage. An LLM then generates synthetic queries for these partial tables, which are used in hard-negative contrastive fine-tuning to refine the embedding model. Experiments across four public benchmarks (MimoTable, OTTQA, FetaQA, and E2E-WTQ) show that CGPT consistently outperforms retrieval baselines, including QGpT, with an average R@1 improvement of 16.54 percent. In a unified multi-domain corpus setting, CGPT further demonstrates strong cross-domain generalization and remains effective even when using smaller LLMs for synthetic query generation. These results indicate that semantically guided partial-table construction, combined with contrastive training from LLM-generated supervision, provides an effective and scalable paradigm for large-scale table retrieval. Our code is available at https://github.com/yumeow0122/CGPT.
STAR: Semantic Table Representation with Header-Aware Clustering and Adaptive Weighted Fusion
Jan 22, 2026Table retrieval is the task of retrieving the most relevant tables from large-scale corpora given natural language queries. However, structural and semantic discrepancies between unstructured text and structured tables make embedding alignment particularly challenging. Recent methods such as QGpT attempt to enrich table semantics by generating synthetic queries, yet they still rely on coarse partial-table sampling and simple fusion strategies, which limit semantic diversity and hinder effective query-table alignment. We propose STAR (Semantic Table Representation), a lightweight framework that improves semantic table representation through semantic clustering and weighted fusion. STAR first applies header-aware K-means clustering to group semantically similar rows and selects representative centroid instances to construct a diverse partial table. It then generates cluster-specific synthetic queries to comprehensively cover the table's semantic space. Finally, STAR employs weighted fusion strategies to integrate table and query embeddings, enabling fine-grained semantic alignment. This design enables STAR to capture complementary information from structured and textual sources, improving the expressiveness of table representations. Experiments on five benchmarks show that STAR achieves consistently higher Recall than QGpT on all datasets, demonstrating the effectiveness of semantic clustering and adaptive weighted fusion for robust table representation. Our code is available at https://github.com/adsl135789/STAR.
Improving Table Retrieval with Question Generation from Partial Tables
Aug 08, 2025Recent advances in open-domain question answering over tables have widely adopted large language models (LLMs) under the Retriever-Reader architecture. Prior works have effectively leveraged LLMs to tackle the complex reasoning demands of the Reader component, such as text-to-text, text-to-SQL, and multi hop reasoning. In contrast, the Retriever component has primarily focused on optimizing the query representation-training retrievers to retrieve relevant tables based on questions, or to select keywords from questions for matching table segments. However, little attention has been given to enhancing how tables themselves are represented in embedding space to better align with questions. To address this, we propose QGpT (Question Generation from Partial Tables), a simple yet effective method that uses an LLM to generate synthetic questions based on small portions of a table. These questions are generated to simulate how a user might query the content of the table currently under consideration. The generated questions are then jointly embedded with the partial table segments used for generation, enhancing semantic alignment with user queries. Without the need to embed entire tables, our method significantly improves retrieval performance across multiple benchmarks for both dense and late-interaction retrievers.
A Cross-Lingual Statutory Article Retrieval Dataset for Taiwan Legal Studies
Oct 15, 2024



This paper introduces a cross-lingual statutory article retrieval (SAR) dataset designed to enhance legal information retrieval in multilingual settings. Our dataset features spoken-language-style legal inquiries in English, paired with corresponding Chinese versions and relevant statutes, covering all Taiwanese civil, criminal, and administrative laws. This dataset aims to improve access to legal information for non-native speakers, particularly for foreign nationals in Taiwan. We propose several LLM-based methods as baselines for evaluating retrieval effectiveness, focusing on mitigating translation errors and improving cross-lingual retrieval performance. Our work provides a valuable resource for developing inclusive legal information retrieval systems.
Learning-From-Mistakes Prompting for Indigenous Language Translation
Jul 18, 2024



Using large language models, this paper presents techniques to improve extremely low-resourced indigenous language translations. Our approaches are grounded in the use of (1) the presence of a datastore consisting of a limited number of parallel translation examples, (2) the inherent capabilities of LLMs like GPT-3.5, and (3) a word-level translation dictionary. We harness the potential of LLMs and in-context learning techniques in such a setting for using LLMs as universal translators for extremely low-resourced languages. Our methodology hinges on utilizing LLMs as language compilers for selected language pairs, hypothesizing that they could internalize syntactic structures to facilitate accurate translation. We introduce three techniques: KNNPrompting with Retrieved Prompting Context, Chain-of-Thought Prompting and Learningfrom-Mistakes Prompting, with the last method addressing past errors. The evaluation results suggest that, even with limited corpora, LLMs can effectively translate extremely low-resource languages when paired with proper prompting.
Enhancing Distractor Generation for Multiple-Choice Questions with Retrieval Augmented Pretraining and Knowledge Graph Integration
Jun 19, 2024



In this paper, we tackle the task of distractor generation (DG) for multiple-choice questions. Our study introduces two key designs. First, we propose \textit{retrieval augmented pretraining}, which involves refining the language model pretraining to align it more closely with the downstream task of DG. Second, we explore the integration of knowledge graphs to enhance the performance of DG. Through experiments with benchmarking datasets, we show that our models significantly outperform the state-of-the-art results. Our best-performing model advances the F1@3 score from 14.80 to 16.47 in MCQ dataset and from 15.92 to 16.50 in Sciq dataset.
CDGP: Automatic Cloze Distractor Generation based on Pre-trained Language Model
Mar 15, 2024



Manually designing cloze test consumes enormous time and efforts. The major challenge lies in wrong option (distractor) selection. Having carefully-design distractors improves the effectiveness of learner ability assessment. As a result, the idea of automatically generating cloze distractor is motivated. In this paper, we investigate cloze distractor generation by exploring the employment of pre-trained language models (PLMs) as an alternative for candidate distractor generation. Experiments show that the PLM-enhanced model brings a substantial performance improvement. Our best performing model advances the state-of-the-art result from 14.94 to 34.17 (NDCG@10 score). Our code and dataset is available at https://github.com/AndyChiangSH/CDGP.
* Findings of short paper, EMNLP 2022
Improving Controllability of Educational Question Generation by Keyword Provision
Dec 02, 2021
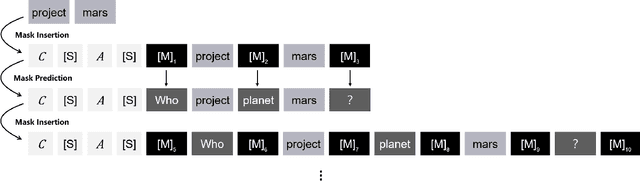

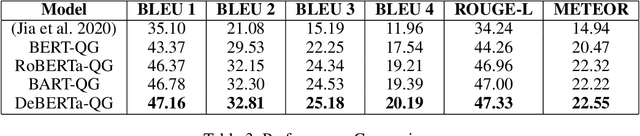
Question Generation (QG) receives increasing research attention in NLP community. One motivation for QG is that QG significantly facilitates the preparation of educational reading practice and assessments. While the significant advancement of QG techniques was reported, current QG results are not ideal for educational reading practice assessment in terms of \textit{controllability} and \textit{question difficulty}. This paper reports our results toward the two issues. First, we report a state-of-the-art exam-like QG model by advancing the current best model from 11.96 to 20.19 (in terms of BLEU 4 score). Second, we propose to investigate a variant of QG setting by allowing users to provide keywords for guiding QG direction. We also present a simple but effective model toward the QG controllability task. Experiments are also performed and the results demonstrate the feasibility and potentials of improving QG diversity and controllability by the proposed keyword provision QG model.
Exploring the Long Short-Term Dependencies to Infer Shot Influence in Badminton Matches
Sep 14, 2021
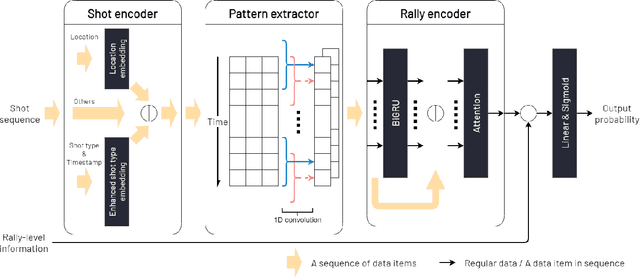
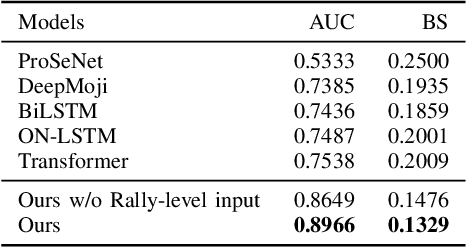

Identifying significant shots in a rally is important for evaluating players' performance in badminton matches. While there are several studies that have quantified player performance in other sports, analyzing badminton data is remained untouched. In this paper, we introduce a badminton language to fully describe the process of the shot and propose a deep learning model composed of a novel short-term extractor and a long-term encoder for capturing a shot-by-shot sequence in a badminton rally by framing the problem as predicting a rally result. Our model incorporates an attention mechanism to enable the transparency of the action sequence to the rally result, which is essential for badminton experts to gain interpretable predictions. Experimental evaluation based on a real-world dataset demonstrates that our proposed model outperforms the strong baselines. The source code is publicly available at https://github.com/yao0510/Shot-Influence.
A BERT-based Distractor Generation Scheme with Multi-tasking and Negative Answer Training Strategies
Oct 12, 2020


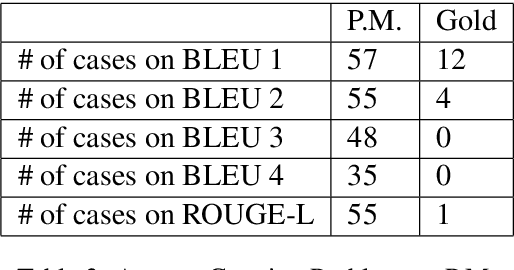
In this paper, we investigate the following two limitations for the existing distractor generation (DG) methods. First, the quality of the existing DG methods are still far from practical use. There is still room for DG quality improvement. Second, the existing DG designs are mainly for single distractor generation. However, for practical MCQ preparation, multiple distractors are desired. Aiming at these goals, in this paper, we present a new distractor generation scheme with multi-tasking and negative answer training strategies for effectively generating \textit{multiple} distractors. The experimental results show that (1) our model advances the state-of-the-art result from 28.65 to 39.81 (BLEU 1 score) and (2) the generated multiple distractors are diverse and show strong distracting power for multiple choice question.