 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Cross-Lingual Statutory Article Retrieval Dataset for Taiwan Legal Studies
Oct 15, 2024



This paper introduces a cross-lingual statutory article retrieval (SAR) dataset designed to enhance legal information retrieval in multilingual settings. Our dataset features spoken-language-style legal inquiries in English, paired with corresponding Chinese versions and relevant statutes, covering all Taiwanese civil, criminal, and administrative laws. This dataset aims to improve access to legal information for non-native speakers, particularly for foreign nationals in Taiwan. We propose several LLM-based methods as baselines for evaluating retrieval effectiveness, focusing on mitigating translation errors and improving cross-lingual retrieval performance. Our work provides a valuable resource for developing inclusive legal information retrieval systems.
Learning-From-Mistakes Prompting for Indigenous Language Translation
Jul 18, 2024



Using large language models, this paper presents techniques to improve extremely low-resourced indigenous language translations. Our approaches are grounded in the use of (1) the presence of a datastore consisting of a limited number of parallel translation examples, (2) the inherent capabilities of LLMs like GPT-3.5, and (3) a word-level translation dictionary. We harness the potential of LLMs and in-context learning techniques in such a setting for using LLMs as universal translators for extremely low-resourced languages. Our methodology hinges on utilizing LLMs as language compilers for selected language pairs, hypothesizing that they could internalize syntactic structures to facilitate accurate translation. We introduce three techniques: KNNPrompting with Retrieved Prompting Context, Chain-of-Thought Prompting and Learningfrom-Mistakes Prompting, with the last method addressing past errors. The evaluation results suggest that, even with limited corpora, LLMs can effectively translate extremely low-resource languages when paired with proper prompting.
GPT-3-driven pedagogical agents for training children's curious question-asking skills
Dec 08, 2022Students' ability to ask curious questions is a crucial skill that improves their learning processes. To train this skill, previous research has used a conversational agent that propose specific cues to prompt children's curiosity during learning. Despite showing pedagogical efficiency, this method is still limited since it relies on generating the said prompts by hand for each educational resource, which can be a very long and costly process. In this context, we leverage the advances in the natural language processing field and explore using a large language model (GPT-3) to automate the generation of this agent's curiosity-prompting cues to help children ask more and deeper questions. We then used this study to investigate a different curiosity-prompting behavior for the agent. The study was conducted with 75 students aged between 9 and 10. They either interacted with a hand-crafted conversational agent that proposes "closed" manually-extracted cues leading to predefined questions, a GPT-3-driven one that proposes the same type of cues, or a GPT-3-driven one that proposes "open" cues that can lead to several possible questions. Results showed a similar question-asking performance between children who had the two "closed" agents, but a significantly better one for participants with the "open" agent. Our first results suggest the validity of using GPT-3 to facilitate the implementation of curiosity-stimulating learning technologies. In a second step, we also show that GPT-3 can be efficient in proposing the relevant open cues that leave children with more autonomy to express their curiosity.
Selecting Better Samples from Pre-trained LLMs: A Case Study on Question Generation
Sep 22, 2022
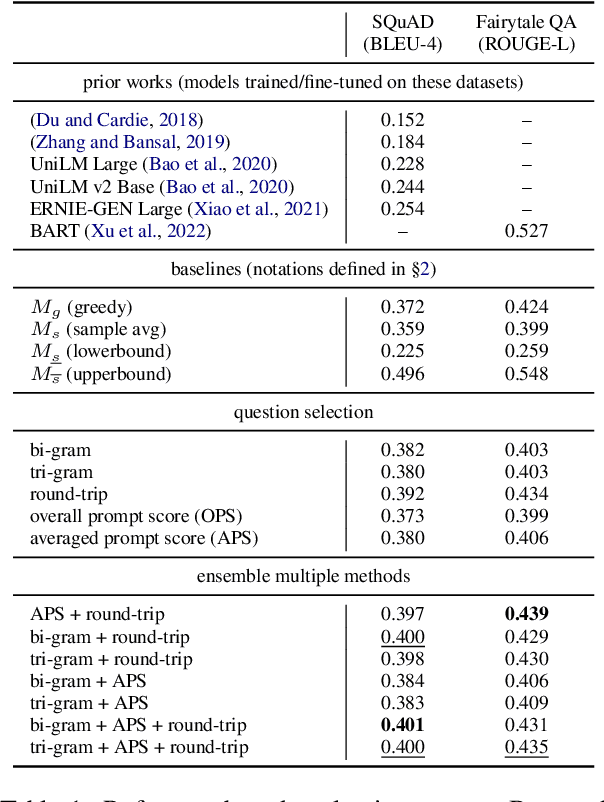
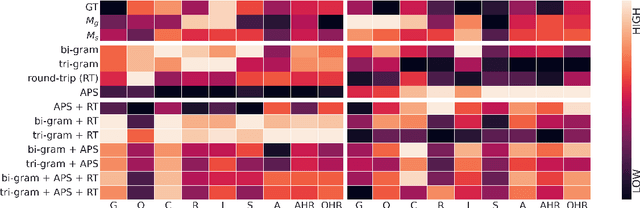
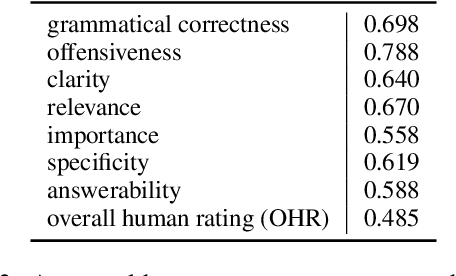
Large Language Models (LLMs) have in recent years demonstrated impressive prowess in natural language generation. A common practice to improve generation diversity is to sample multiple outputs from the model. However, there lacks a simple and robust way of selecting the best output from these stochastic samples. As a case study framed in the context of question generation, we propose two prompt-based approaches to selecting high-quality questions from a set of LLM-generated candidates. Our method works under the constraints of 1) a black-box (non-modifiable) question generation model and 2) lack of access to human-annotated references -- both of which are realistic limitations for real-world deployment of LLMs. With automatic as well as human evaluations, we empirically demonstrate that our approach can effectively select questions of higher qualities than greedy generation.