 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupporting Qualitative Analysis with Large Language Models: Combining Codebook with GPT-3 for Deductive Coding
Apr 17, 2023Qualitative analysis of textual contents unpacks rich and valuable information by assigning labels to the data. However, this process is often labor-intensive, particularly when working with large datasets. While recent AI-based tools demonstrate utility, researchers may not have readily available AI resources and expertise, let alone be challenged by the limited generalizability of those task-specific models. In this study, we explored the use of large language models (LLMs) in supporting deductive coding, a major category of qualitative analysis where researchers use pre-determined codebooks to label the data into a fixed set of codes. Instead of training task-specific models, a pre-trained LLM could be used directly for various tasks without fine-tuning through prompt learning. Using a curiosity-driven questions coding task as a case study, we found, by combining GPT-3 with expert-drafted codebooks, our proposed approach achieved fair to substantial agreements with expert-coded results. We lay out challenges and opportunities in using LLMs to support qualitative coding and beyond.
GPT-3-driven pedagogical agents for training children's curious question-asking skills
Dec 08, 2022Students' ability to ask curious questions is a crucial skill that improves their learning processes. To train this skill, previous research has used a conversational agent that propose specific cues to prompt children's curiosity during learning. Despite showing pedagogical efficiency, this method is still limited since it relies on generating the said prompts by hand for each educational resource, which can be a very long and costly process. In this context, we leverage the advances in the natural language processing field and explore using a large language model (GPT-3) to automate the generation of this agent's curiosity-prompting cues to help children ask more and deeper questions. We then used this study to investigate a different curiosity-prompting behavior for the agent. The study was conducted with 75 students aged between 9 and 10. They either interacted with a hand-crafted conversational agent that proposes "closed" manually-extracted cues leading to predefined questions, a GPT-3-driven one that proposes the same type of cues, or a GPT-3-driven one that proposes "open" cues that can lead to several possible questions. Results showed a similar question-asking performance between children who had the two "closed" agents, but a significantly better one for participants with the "open" agent. Our first results suggest the validity of using GPT-3 to facilitate the implementation of curiosity-stimulating learning technologies. In a second step, we also show that GPT-3 can be efficient in proposing the relevant open cues that leave children with more autonomy to express their curiosity.
Selecting Better Samples from Pre-trained LLMs: A Case Study on Question Generation
Sep 22, 2022
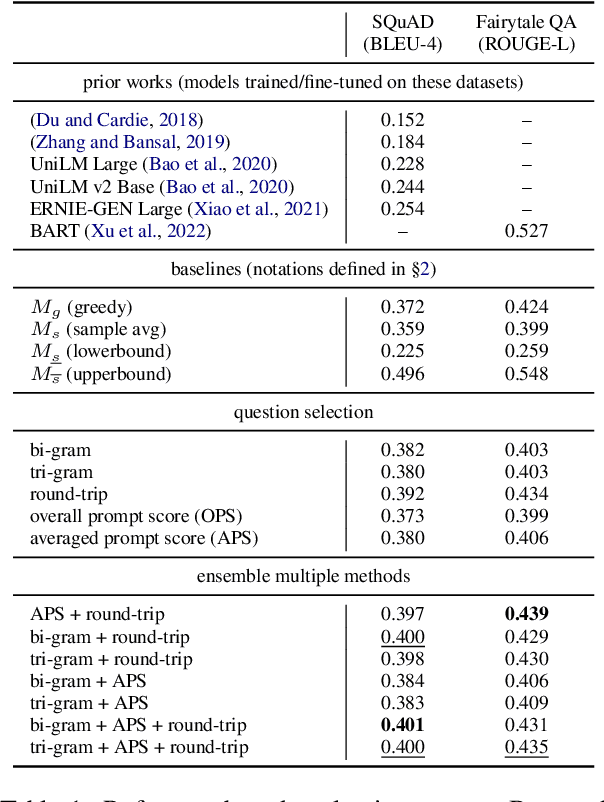
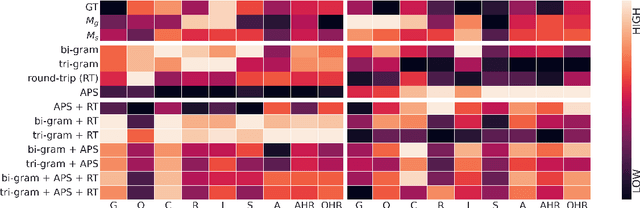
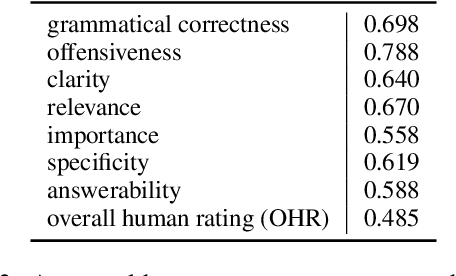
Large Language Models (LLMs) have in recent years demonstrated impressive prowess in natural language generation. A common practice to improve generation diversity is to sample multiple outputs from the model. However, there lacks a simple and robust way of selecting the best output from these stochastic samples. As a case study framed in the context of question generation, we propose two prompt-based approaches to selecting high-quality questions from a set of LLM-generated candidates. Our method works under the constraints of 1) a black-box (non-modifiable) question generation model and 2) lack of access to human-annotated references -- both of which are realistic limitations for real-world deployment of LLMs. With automatic as well as human evaluations, we empirically demonstrate that our approach can effectively select questions of higher qualities than greedy generation.