 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepTaxon: An Interpretable Retrieval-Augmented Multimodal Framework for Unified Species Identification and Discovery
Apr 27, 2026Identifying species in biology among tens of thousands of visually similar taxa while discovering unknown species in open-world environments remains a fundamental challenge in biodiversity research. Current methods treat identification and discovery as separate problems, with classification models assuming closed sets and discovery relying on threshold-based rejection. Here we present DeepTaxon, a retrieval-augmented multimodal framework that unifies species identification and discovery through interpretable reasoning over retrieved visual evidence. Given a query image, DeepTaxon retrieves the top-$k$ candidate species with $n$ exemplar images each from a retrieval index and performs chain-of-thought comparative reasoning. Critically, we redefine discovery as an explicit, retrieval-based decision problem rather than an implicit parametric memory problem. A sample is novel if and only if the retrieval index lacks sufficient evidence for identification, so each retrieval naturally yields a classification or discovery label without manual annotation, thereby providing automatic supervision for both tasks. We train the framework via supervised fine-tuning on synthetic retrieval-augmented data, followed by reinforcement learning on hard samples, converting high-recall retrieval into high-precision decisions that scale to massive taxonomic vocabularies. Extensive experiments on a large-scale in-distribution benchmark and six out-of-distribution datasets demonstrate consistent improvements in both identification and discovery. Ablation studies further reveal effective test-time scaling with candidate count $k$ and exemplar count $n$, strong zero-shot transfer to unseen domains, and consistent performance across retrieval encoders, establishing an interpretable solution for biodiversity research.
Situation-Dependent Causal Influence-Based Cooperative Multi-agent Reinforcement Learning
Dec 15, 2023



Learning to collaborate has witnessed significant progress in multi-agent reinforcement learning (MARL). However, promoting coordination among agents and enhancing exploration capabilities remain challenges. In multi-agent environments, interactions between agents are limited in specific situations. Effective collaboration between agents thus requires a nuanced understanding of when and how agents' actions influence others. To this end, in this paper, we propose a novel MARL algorithm named Situation-Dependent Causal Influence-Based Cooperative Multi-agent Reinforcement Learning (SCIC), which incorporates a novel Intrinsic reward mechanism based on a new cooperation criterion measured by situation-dependent causal influence among agents. Our approach aims to detect inter-agent causal influences in specific situations based on the criterion using causal intervention and conditional mutual information. This effectively assists agents in exploring states that can positively impact other agents, thus promoting cooperation between agents. The resulting update links coordinated exploration and intrinsic reward distribution, which enhance overall collaboration and performance. Experimental results on various MARL benchmarks demonstrate the superiority of our method compared to state-of-the-art approaches.
Multi-task Joint Strategies of Self-supervised Representation Learning on Biomedical Networks for Drug Discovery
Jan 12, 2022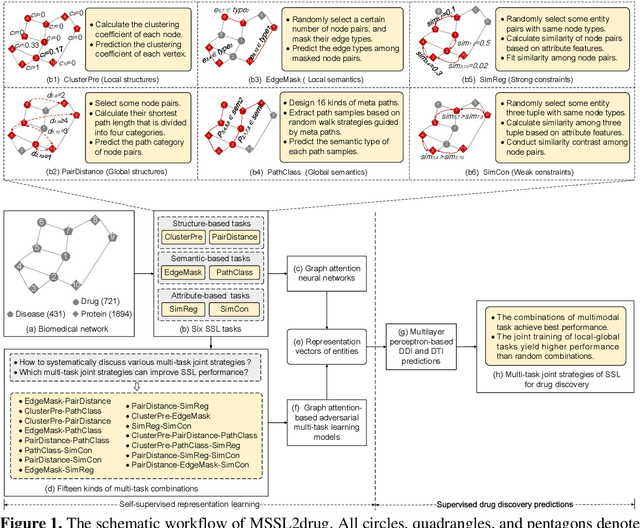
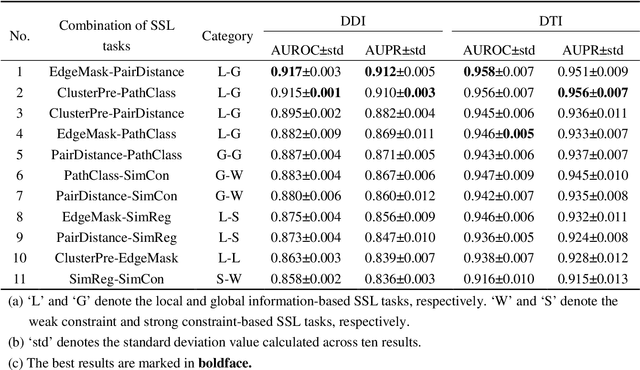
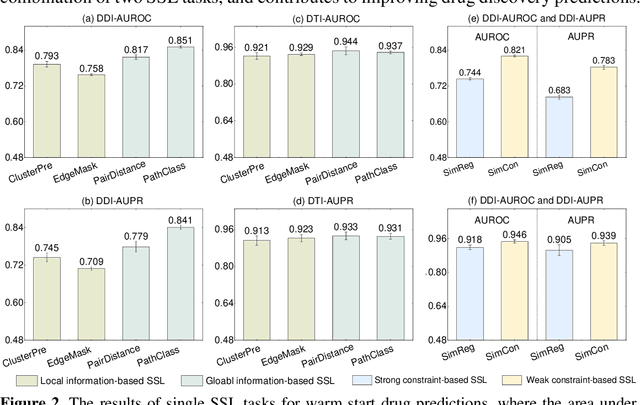
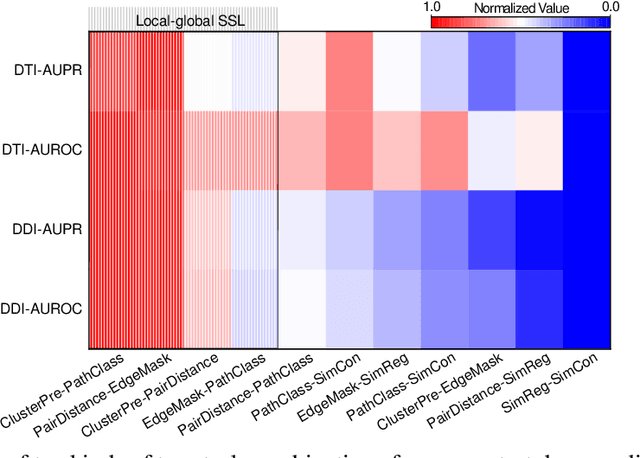
Self-supervised representation learning (SSL) on biomedical networks provides new opportunities for drug discovery which is lack of available biological or clinic phenotype. However, how to effectively combine multiple SSL models is challenging and rarely explored. Therefore, we propose multi-task joint strategies of self-supervised representation learning on biomedical networks for drug discovery, named MSSL2drug. We design six basic SSL tasks that are inspired by various modality features including structures, semantics, and attributes in biomedical heterogeneous networks. In addition, fifteen combinations of multiple tasks are evaluated by a graph attention-based adversarial multi-task learning framework in two drug discovery scenarios. The results suggest two important findings. (1) The combinations of multimodal tasks achieve the best performance compared to other multi-task joint strategies. (2) The joint training of local and global SSL tasks yields higher performance than random task combinations. Therefore, we conjecture that the multimodal and local-global combination strategies can be regarded as a guideline for multi-task SSL to drug discovery.