 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairness in Monotone $k$-submodular Maximization: Algorithms and Applications
Nov 08, 2024



Submodular optimization has become increasingly prominent in machine learning and fairness has drawn much attention. In this paper, we propose to study the fair $k$-submodular maximization problem and develop a $\frac{1}{3}$-approximation greedy algorithm with a running time of $\mathcal{O}(knB)$. To the best of our knowledge, our work is the first to incorporate fairness in the context of $k$-submodular maximization, and our theoretical guarantee matches the best-known $k$-submodular maximization results without fairness constraints. In addition, we have developed a faster threshold-based algorithm that achieves a $(\frac{1}{3} - \epsilon)$ approximation with $\mathcal{O}(\frac{kn}{\epsilon} \log \frac{B}{\epsilon})$ evaluations of the function $f$. Furthermore, for both algorithms, we provide approximation guarantees when the $k$-submodular function is not accessible but only can be approximately accessed. We have extensively validated our theoretical findings through empirical research and examined the practical implications of fairness. Specifically, we have addressed the question: ``What is the price of fairness?" through case studies on influence maximization with $k$ topics and sensor placement with $k$ types. The experimental results show that the fairness constraints do not significantly undermine the quality of solutions.
A Framework for Adapting Offline Algorithms to Solve Combinatorial Multi-Armed Bandit Problems with Bandit Feedback
Jan 30, 2023


We investigate the problem of stochastic, combinatorial multi-armed bandits where the learner only has access to bandit feedback and the reward function can be non-linear. We provide a general framework for adapting discrete offline approximation algorithms into sublinear $\alpha$-regret methods that only require bandit feedback, achieving $\mathcal{O}\left(T^\frac{2}{3}\log(T)^\frac{1}{3}\right)$ expected cumulative $\alpha$-regret dependence on the horizon $T$. The framework only requires the offline algorithms to be robust to small errors in function evaluation. The adaptation procedure does not even require explicit knowledge of the offline approximation algorithm -- the offline algorithm can be used as black box subroutine. To demonstrate the utility of the proposed framework, the proposed framework is applied to multiple problems in submodular maximization, adapting approximation algorithms for cardinality and for knapsack constraints. The new CMAB algorithms for knapsack constraints outperform a full-bandit method developed for the adversarial setting in experiments with real-world data.
Estimating defection in subscription-type markets: empirical analysis from the scholarly publishing industry
Nov 18, 2022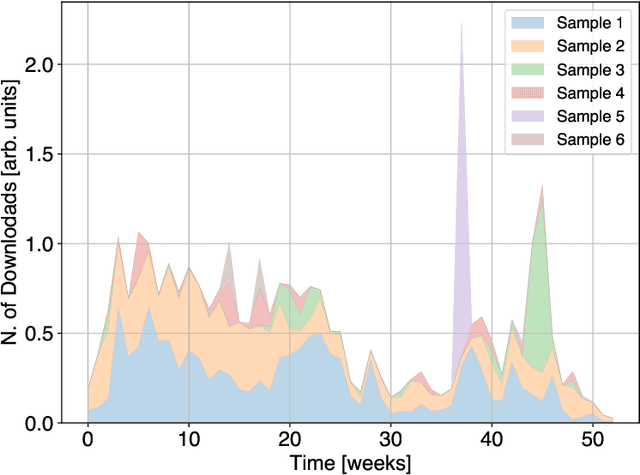
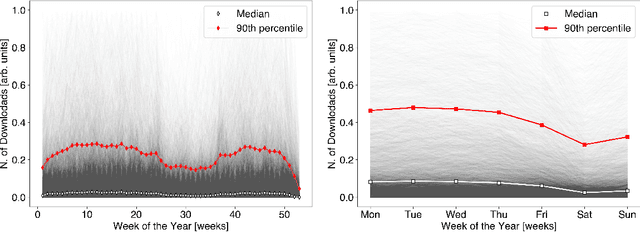
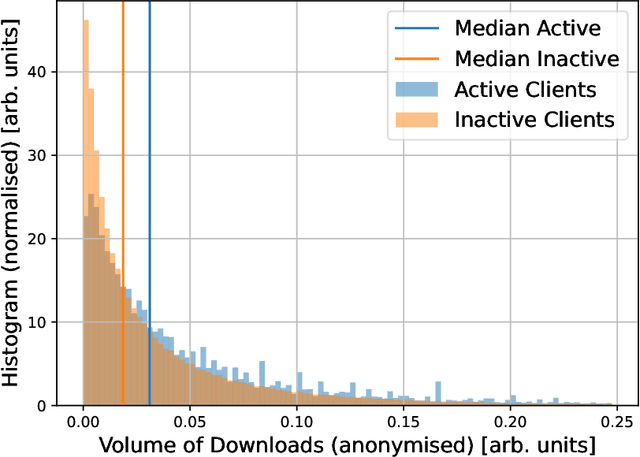
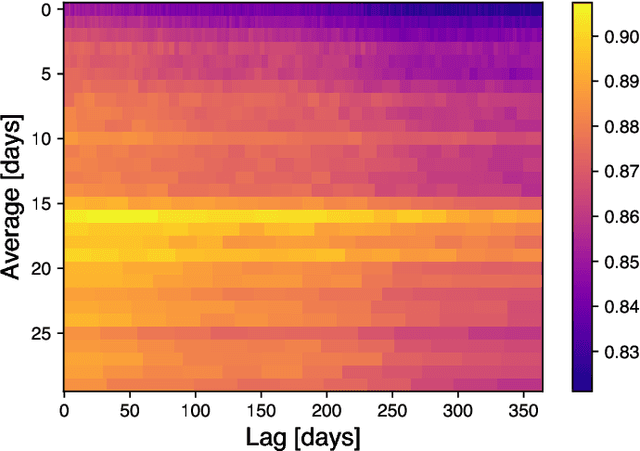
We present the first empirical study on customer churn prediction in the scholarly publishing industry. The study examines our proposed method for prediction on a customer subscription data over a period of 6.5 years, which was provided by a major academic publisher. We explore the subscription-type market within the context of customer defection and modelling, and provide analysis of the business model of such markets, and how these characterise the academic publishing business. The proposed method for prediction attempts to provide inference of customer's likelihood of defection on the basis of their re-sampled use of provider resources -in this context, the volume and frequency of content downloads. We show that this approach can be both accurate as well as uniquely useful in the business-to-business context, with which the scholarly publishing business model shares similarities. The main findings of this work suggest that whilst all predictive models examined, especially ensemble methods of machine learning, achieve substantially accurate prediction of churn, nearly a year ahead, this can be furthermore achieved even when the specific behavioural attributes that can be associated to each customer probability to churn are overlooked. Allowing as such highly accurate inference of churn from minimal possible data. We show that modelling churn on the basis of re-sampling customers' use of resources over subscription time is a better (simplified) approach than when considering the high granularity that can often characterise consumption behaviour.
Prediction of Depression Severity Based on the Prosodic and Semantic Features with Bidirectional LSTM and Time Distributed CNN
Feb 25, 2022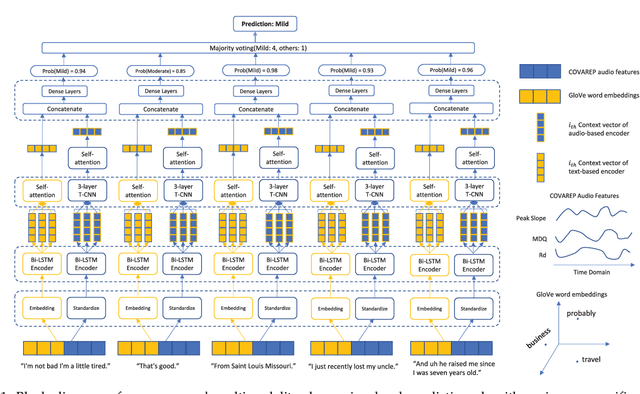

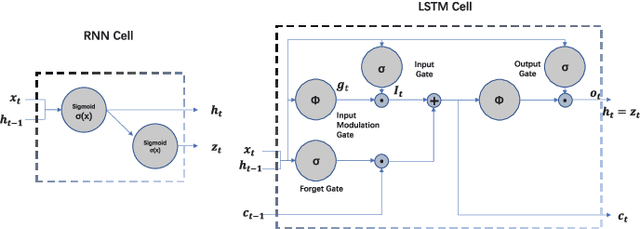
Depression is increasingly impacting individuals both physically and psychologically worldwide. It has become a global major public health problem and attracts attention from various research fields. Traditionally, the diagnosis of depression is formulated through semi-structured interviews and supplementary questionnaires, which makes the diagnosis heavily relying on physicians experience and is subject to bias. Mental health monitoring and cloud-based remote diagnosis can be implemented through an automated depression diagnosis system. In this article, we propose an attention-based multimodality speech and text representation for depression prediction. Our model is trained to estimate the depression severity of participants using the Distress Analysis Interview Corpus-Wizard of Oz (DAIC-WOZ) dataset. For the audio modality, we use the collaborative voice analysis repository (COVAREP) features provided by the dataset and employ a Bidirectional Long Short-Term Memory Network (Bi-LSTM) followed by a Time-distributed Convolutional Neural Network (T-CNN). For the text modality, we use global vectors for word representation (GloVe) to perform word embeddings and the embeddings are fed into the Bi-LSTM network. Results show that both audio and text models perform well on the depression severity estimation task, with best sequence level F1 score of 0.9870 and patient-level F1 score of 0.9074 for the audio model over five classes (healthy, mild, moderate, moderately severe, and severe), as well as sequence level F1 score of 0.9709 and patient-level F1 score of 0.9245 for the text model over five classes. Results are similar for the multimodality fused model, with the highest F1 score of 0.9580 on the patient-level depression detection task over five classes. Experiments show statistically significant improvements over previous works.