 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating defection in subscription-type markets: empirical analysis from the scholarly publishing industry
Paper and Code
Nov 18, 2022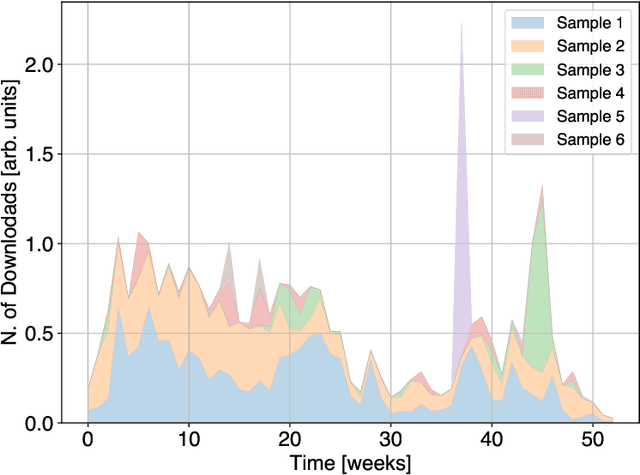
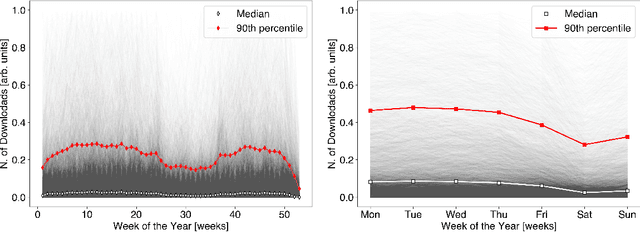
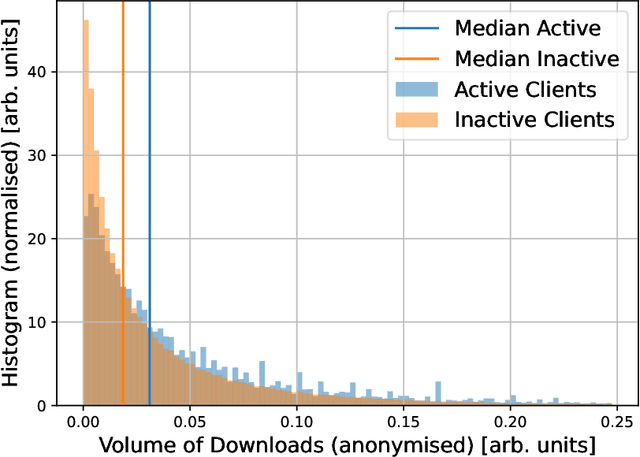
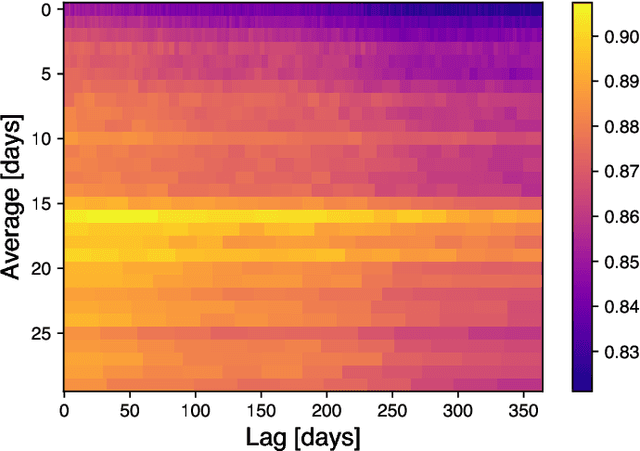
We present the first empirical study on customer churn prediction in the scholarly publishing industry. The study examines our proposed method for prediction on a customer subscription data over a period of 6.5 years, which was provided by a major academic publisher. We explore the subscription-type market within the context of customer defection and modelling, and provide analysis of the business model of such markets, and how these characterise the academic publishing business. The proposed method for prediction attempts to provide inference of customer's likelihood of defection on the basis of their re-sampled use of provider resources -in this context, the volume and frequency of content downloads. We show that this approach can be both accurate as well as uniquely useful in the business-to-business context, with which the scholarly publishing business model shares similarities. The main findings of this work suggest that whilst all predictive models examined, especially ensemble methods of machine learning, achieve substantially accurate prediction of churn, nearly a year ahead, this can be furthermore achieved even when the specific behavioural attributes that can be associated to each customer probability to churn are overlooked. Allowing as such highly accurate inference of churn from minimal possible data. We show that modelling churn on the basis of re-sampling customers' use of resources over subscription time is a better (simplified) approach than when considering the high granularity that can often characterise consumption behaviour.