 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating defection in subscription-type markets: empirical analysis from the scholarly publishing industry
Nov 18, 2022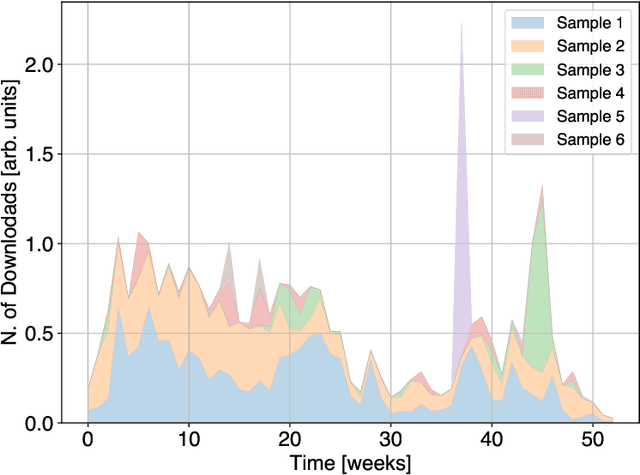
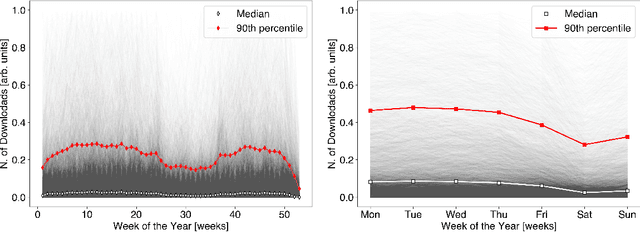
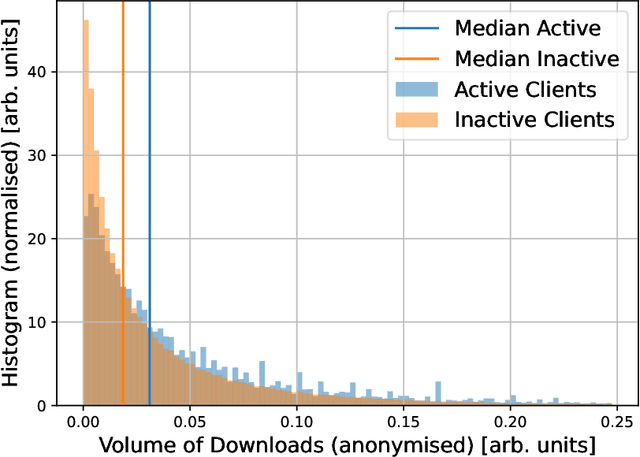
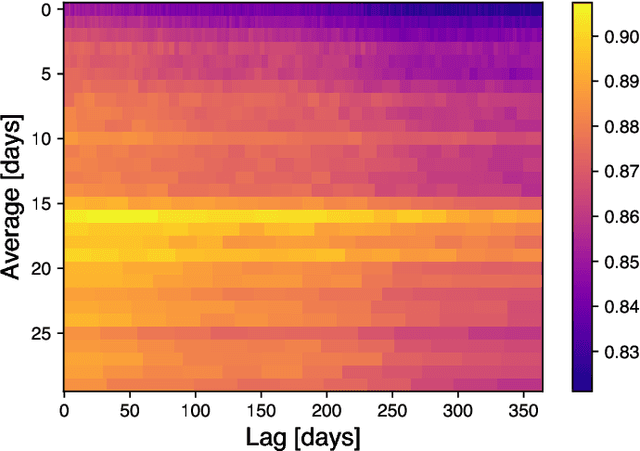
We present the first empirical study on customer churn prediction in the scholarly publishing industry. The study examines our proposed method for prediction on a customer subscription data over a period of 6.5 years, which was provided by a major academic publisher. We explore the subscription-type market within the context of customer defection and modelling, and provide analysis of the business model of such markets, and how these characterise the academic publishing business. The proposed method for prediction attempts to provide inference of customer's likelihood of defection on the basis of their re-sampled use of provider resources -in this context, the volume and frequency of content downloads. We show that this approach can be both accurate as well as uniquely useful in the business-to-business context, with which the scholarly publishing business model shares similarities. The main findings of this work suggest that whilst all predictive models examined, especially ensemble methods of machine learning, achieve substantially accurate prediction of churn, nearly a year ahead, this can be furthermore achieved even when the specific behavioural attributes that can be associated to each customer probability to churn are overlooked. Allowing as such highly accurate inference of churn from minimal possible data. We show that modelling churn on the basis of re-sampling customers' use of resources over subscription time is a better (simplified) approach than when considering the high granularity that can often characterise consumption behaviour.
Analysing the Predictivity of Features to Characterise the Search Space
Sep 11, 2022Exploring search spaces is one of the most unpredictable challenges that has attracted the interest of researchers for decades. One way to handle unpredictability is to characterise the search spaces and take actions accordingly. A well-characterised search space can assist in mapping the problem states to a set of operators for generating new problem states. In this paper, a landscape analysis-based set of features has been analysed using the most renown machine learning approaches to determine the optimal feature set. However, in order to deal with problem complexity and induce commonality for transferring experience across domains, the selection of the most representative features remains crucial. The proposed approach analyses the predictivity of a set of features in order to determine the best categorization.
* Artificial Neural Networks and Machine Learning, ICANN 2022, 31st International Conference on Artificial Neural Networks, Bristol, UK, September, 2022, Proceedings; Part IV (1 13)
Task-oriented Dialogue Systems: performance vs. quality-optima, a review
Dec 21, 2021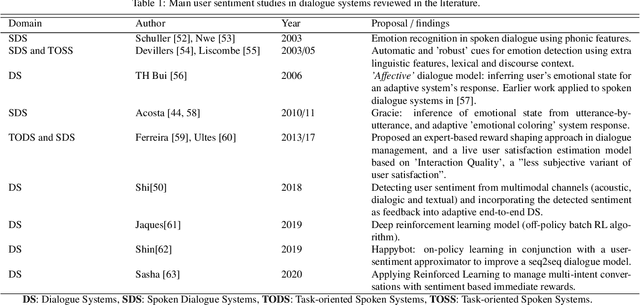

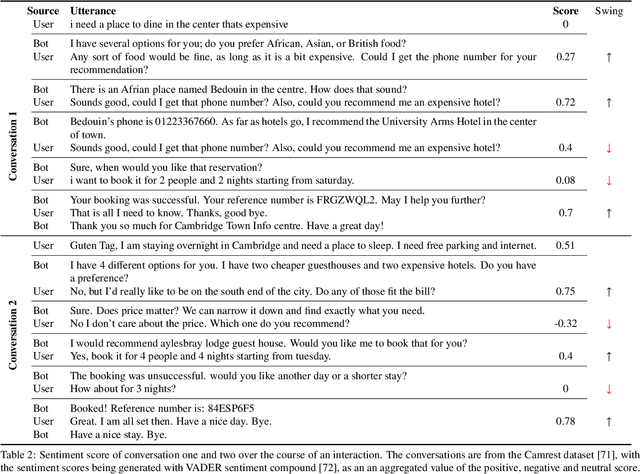

Task-oriented dialogue systems (TODS) are continuing to rise in popularity as various industries find ways to effectively harness their capabilities, saving both time and money. However, even state-of-the-art TODS are not yet reaching their full potential. TODS typically have a primary design focus on completing the task at hand, so the metric of task-resolution should take priority. Other conversational quality attributes that may point to the success, or otherwise, of the dialogue, may be ignored. This can cause interactions between human and dialogue system that leave the user dissatisfied or frustrated. This paper explores the literature on evaluative frameworks of dialogue systems and the role of conversational quality attributes in dialogue systems, looking at if, how, and where they are utilised, and examining their correlation with the performance of the dialogue system.