 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoFormer: Local Frequency Transformer for Image Deblurring
Jul 24, 2024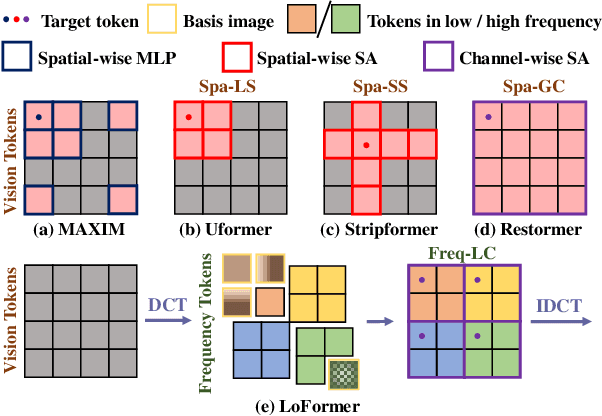
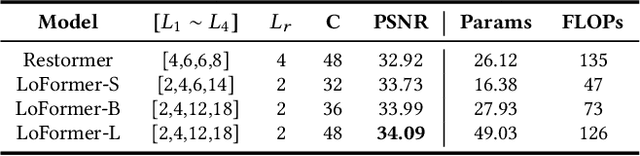
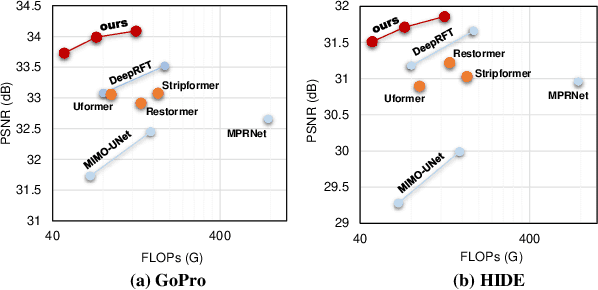
Due to the computational complexity of self-attention (SA), prevalent techniques for image deblurring often resort to either adopting localized SA or employing coarse-grained global SA methods, both of which exhibit drawbacks such as compromising global modeling or lacking fine-grained correlation. In order to address this issue by effectively modeling long-range dependencies without sacrificing fine-grained details, we introduce a novel approach termed Local Frequency Transformer (LoFormer). Within each unit of LoFormer, we incorporate a Local Channel-wise SA in the frequency domain (Freq-LC) to simultaneously capture cross-covariance within low- and high-frequency local windows. These operations offer the advantage of (1) ensuring equitable learning opportunities for both coarse-grained structures and fine-grained details, and (2) exploring a broader range of representational properties compared to coarse-grained global SA methods. Additionally, we introduce an MLP Gating mechanism complementary to Freq-LC, which serves to filter out irrelevant features while enhancing global learning capabilities. Our experiments demonstrate that LoFormer significantly improves performance in the image deblurring task, achieving a PSNR of 34.09 dB on the GoPro dataset with 126G FLOPs. https://github.com/DeepMed-Lab-ECNU/Single-Image-Deblur
AdaRevD: Adaptive Patch Exiting Reversible Decoder Pushes the Limit of Image Deblurring
Jun 13, 2024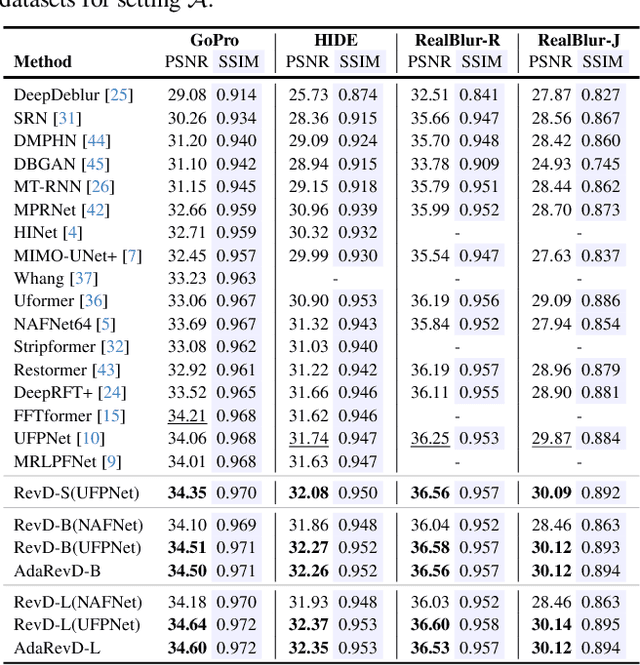

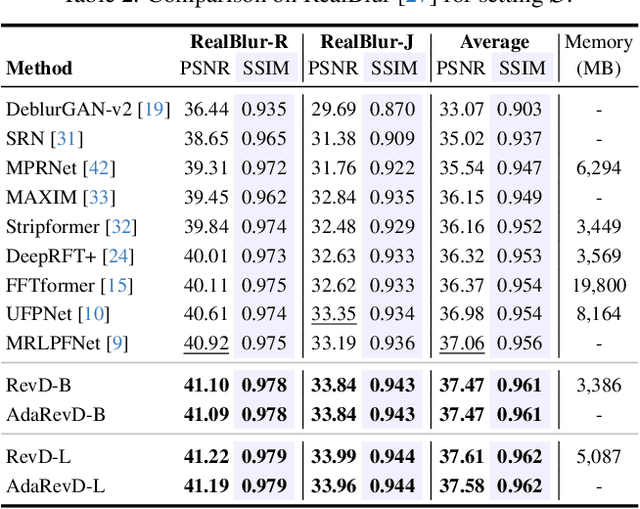

Despite the recent progress in enhancing the efficacy of image deblurring, the limited decoding capability constrains the upper limit of State-Of-The-Art (SOTA) methods. This paper proposes a pioneering work, Adaptive Patch Exiting Reversible Decoder (AdaRevD), to explore their insufficient decoding capability. By inheriting the weights of the well-trained encoder, we refactor a reversible decoder which scales up the single-decoder training to multi-decoder training while remaining GPU memory-friendly. Meanwhile, we show that our reversible structure gradually disentangles high-level degradation degree and low-level blur pattern (residual of the blur image and its sharp counterpart) from compact degradation representation. Besides, due to the spatially-variant motion blur kernels, different blur patches have various deblurring difficulties. We further introduce a classifier to learn the degradation degree of image patches, enabling them to exit at different sub-decoders for speedup. Experiments show that our AdaRevD pushes the limit of image deblurring, e.g., achieving 34.60 dB in PSNR on GoPro dataset.
I$^3$Net: Inter-Intra-slice Interpolation Network for Medical Slice Synthesis
May 05, 2024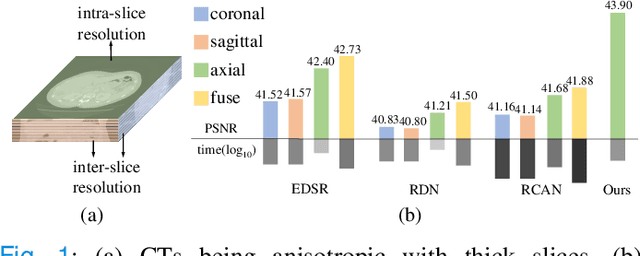

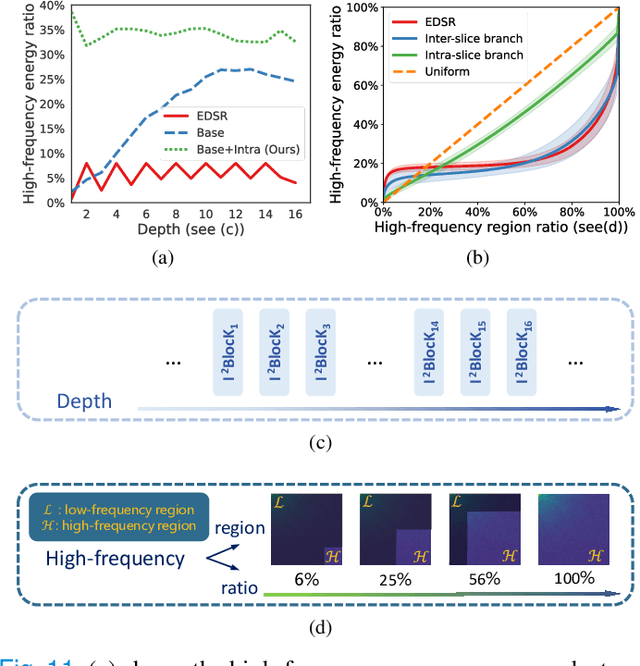
Medical imaging is limited by acquisition time and scanning equipment. CT and MR volumes, reconstructed with thicker slices, are anisotropic with high in-plane resolution and low through-plane resolution. We reveal an intriguing phenomenon that due to the mentioned nature of data, performing slice-wise interpolation from the axial view can yield greater benefits than performing super-resolution from other views. Based on this observation, we propose an Inter-Intra-slice Interpolation Network (I$^3$Net), which fully explores information from high in-plane resolution and compensates for low through-plane resolution. The through-plane branch supplements the limited information contained in low through-plane resolution from high in-plane resolution and enables continual and diverse feature learning. In-plane branch transforms features to the frequency domain and enforces an equal learning opportunity for all frequency bands in a global context learning paradigm. We further propose a cross-view block to take advantage of the information from all three views online. Extensive experiments on two public datasets demonstrate the effectiveness of I$^3$Net, and noticeably outperforms state-of-the-art super-resolution, video frame interpolation and slice interpolation methods by a large margin. We achieve 43.90dB in PSNR, with at least 1.14dB improvement under the upscale factor of $\times$2 on MSD dataset with faster inference. Code is available at https://github.com/DeepMed-Lab-ECNU/Medical-Image-Reconstruction.
Deep Residual Fourier Transformation for Single Image Deblurring
Nov 23, 2021
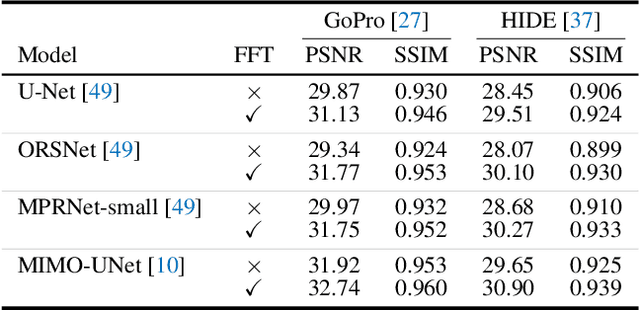
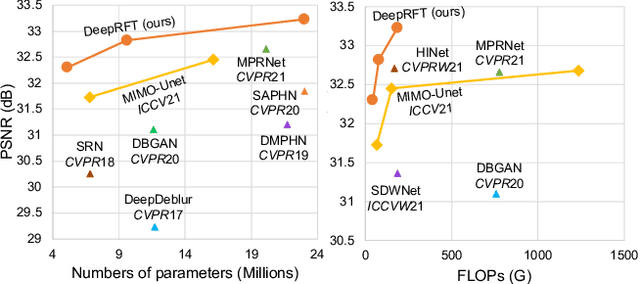
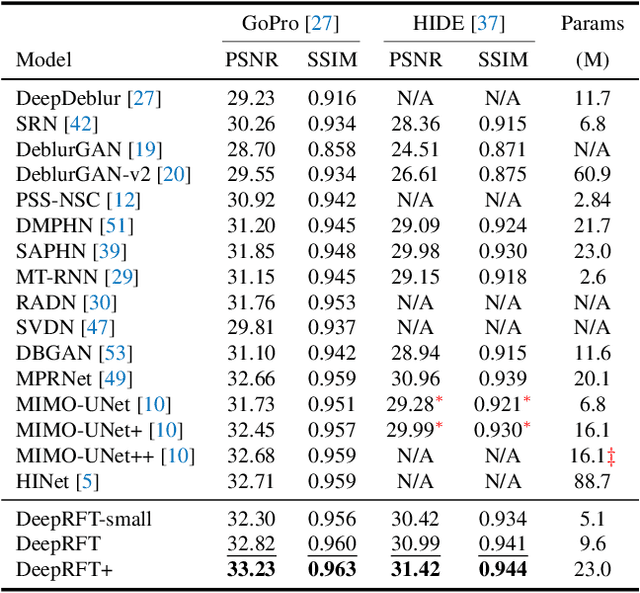
It has been a common practice to adopt the ResBlock, which learns the difference between blurry and sharp image pairs, in end-to-end image deblurring architectures. Reconstructing a sharp image from its blurry counterpart requires changes regarding both low- and high-frequency information. Although conventional ResBlock may have good abilities in capturing the high-frequency components of images, it tends to overlook the low-frequency information. Moreover, ResBlock usually fails to felicitously model the long-distance information which is non-trivial in reconstructing a sharp image from its blurry counterpart. In this paper, we present a Residual Fast Fourier Transform with Convolution Block (Res FFT-Conv Block), capable of capturing both long-term and short-term interactions, while integrating both low- and high-frequency residual information. Res FFT-Conv Block is a conceptually simple yet computationally efficient, and plug-and-play block, leading to remarkable performance gains in different architectures. With Res FFT-Conv Block, we further propose a Deep Residual Fourier Transformation (DeepRFT) framework, based upon MIMO-UNet, achieving state-of-the-art image deblurring performance on GoPro, HIDE, RealBlur and DPDD datasets. Experiments show our DeepRFT can boost image deblurring performance significantly (e.g., with 1.09 dB improvement in PSNR on GoPro dataset compared with MIMO-UNet), and DeepRFT+ even reaches 33.23 dB in PSNR on GoPro dataset.