 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn LLM-Enabled Frequency-Aware Flow Diffusion Model for Natural-Language-Guided Power System Scenario Generation
Feb 23, 2026Diverse and controllable scenario generation (e.g., wind, solar, load, etc.) is critical for robust power system planning and operation. As AI-based scenario generation methods are becoming the mainstream, existing methods (e.g., Conditional Generative Adversarial Nets) mainly rely on a fixed-length numerical conditioning vector to control the generation results, facing challenges in user conveniency and generation flexibility. In this paper, a natural-language-guided scenario generation framework, named LLM-enabled Frequency-aware Flow Diffusion (LFFD), is proposed to enable users to generate desired scenarios using plain human language. First, a pretrained LLM module is introduced to convert generation requests described by unstructured natural languages into ordered semantic space. Second, instead of using standard diffusion models, a flow diffusion model employing a rectified flow matching objective is introduced to achieve efficient and high-quality scenario generation, taking the LLM output as the model input. During the model training process, a frequency-aware multi-objective optimization algorithm is introduced to mitigate the frequency-bias issue. Meanwhile, a dual-agent framework is designed to create text-scenario training sample pairs as well as to standardize semantic evaluation. Experiments based on large-scale photovoltaic and load datasets demonstrate the effectiveness of the proposed method.
LoFormer: Local Frequency Transformer for Image Deblurring
Jul 24, 2024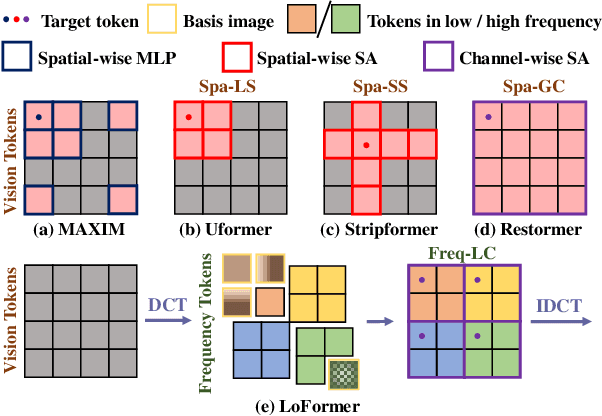
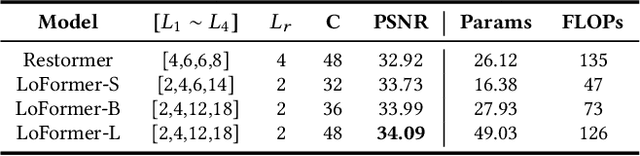
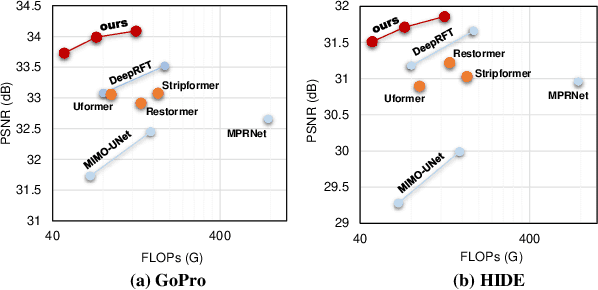
Due to the computational complexity of self-attention (SA), prevalent techniques for image deblurring often resort to either adopting localized SA or employing coarse-grained global SA methods, both of which exhibit drawbacks such as compromising global modeling or lacking fine-grained correlation. In order to address this issue by effectively modeling long-range dependencies without sacrificing fine-grained details, we introduce a novel approach termed Local Frequency Transformer (LoFormer). Within each unit of LoFormer, we incorporate a Local Channel-wise SA in the frequency domain (Freq-LC) to simultaneously capture cross-covariance within low- and high-frequency local windows. These operations offer the advantage of (1) ensuring equitable learning opportunities for both coarse-grained structures and fine-grained details, and (2) exploring a broader range of representational properties compared to coarse-grained global SA methods. Additionally, we introduce an MLP Gating mechanism complementary to Freq-LC, which serves to filter out irrelevant features while enhancing global learning capabilities. Our experiments demonstrate that LoFormer significantly improves performance in the image deblurring task, achieving a PSNR of 34.09 dB on the GoPro dataset with 126G FLOPs. https://github.com/DeepMed-Lab-ECNU/Single-Image-Deblur