 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGTNet: Graph Transformer Network for 3D Point Cloud Classification and Semantic Segmentation
May 24, 2023Recently, graph-based and Transformer-based deep learning networks have demonstrated excellent performances on various point cloud tasks. Most of the existing graph methods are based on static graph, which take a fixed input to establish graph relations. Moreover, many graph methods apply maximization and averaging to aggregate neighboring features, so that only a single neighboring point affects the feature of centroid or different neighboring points have the same influence on the centroid's feature, which ignoring the correlation and difference between points. Most Transformer-based methods extract point cloud features based on global attention and lack the feature learning on local neighbors. To solve the problems of these two types of models, we propose a new feature extraction block named Graph Transformer and construct a 3D point point cloud learning network called GTNet to learn features of point clouds on local and global patterns. Graph Transformer integrates the advantages of graph-based and Transformer-based methods, and consists of Local Transformer and Global Transformer modules. Local Transformer uses a dynamic graph to calculate all neighboring point weights by intra-domain cross-attention with dynamically updated graph relations, so that every neighboring point could affect the features of centroid with different weights; Global Transformer enlarges the receptive field of Local Transformer by a global self-attention. In addition, to avoid the disappearance of the gradient caused by the increasing depth of network, we conduct residual connection for centroid features in GTNet; we also adopt the features of centroid and neighbors to generate the local geometric descriptors in Local Transformer to strengthen the local information learning capability of the model. Finally, we use GTNet for shape classification, part segmentation and semantic segmentation tasks in this paper.
VTPNet for 3D deep learning on point cloud
May 10, 2023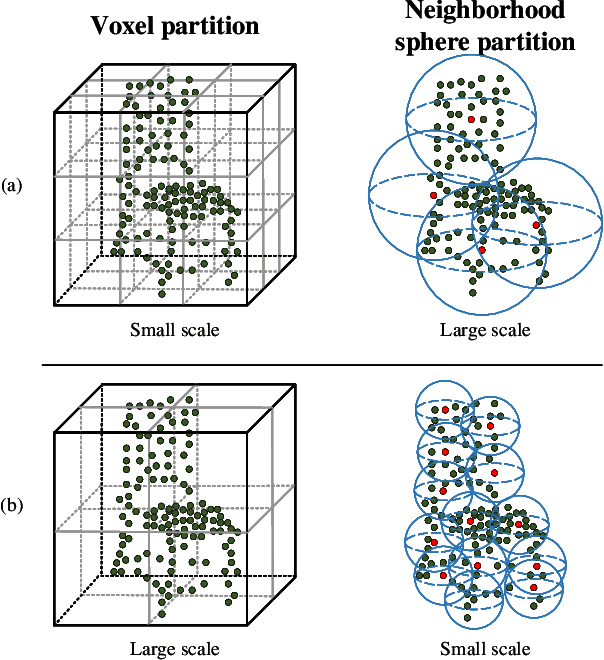
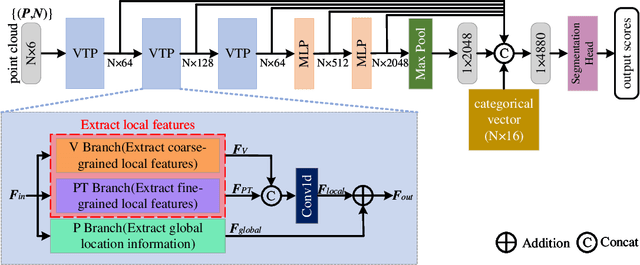
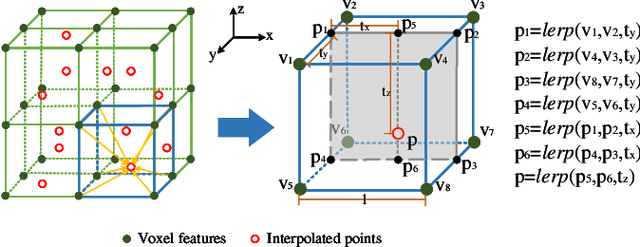

Recently, Transformer-based methods for point cloud learning have achieved good results on various point cloud learning benchmarks. However, since the attention mechanism needs to generate three feature vectors of query, key, and value to calculate attention features, most of the existing Transformer-based point cloud learning methods usually consume a large amount of computational time and memory resources when calculating global attention. To address this problem, we propose a Voxel-Transformer-Point (VTP) Block for extracting local and global features of point clouds. VTP combines the advantages of voxel-based, point-based and Transformer-based methods, which consists of Voxel-Based Branch (V branch), Point-Based Transformer Branch (PT branch) and Point-Based Branch (P branch). The V branch extracts the coarse-grained features of the point cloud through low voxel resolution; the PT branch obtains the fine-grained features of the point cloud by calculating the self-attention in the local neighborhood and the inter-neighborhood cross-attention; the P branch uses a simplified MLP network to generate the global location information of the point cloud. In addition, to enrich the local features of point clouds at different scales, we set the voxel scale in the V branch and the neighborhood sphere scale in the PT branch to one large and one small (large voxel scale \& small neighborhood sphere scale or small voxel scale \& large neighborhood sphere scale). Finally, we use VTP as the feature extraction network to construct a VTPNet for point cloud learning, and performs shape classification, part segmentation, and semantic segmentation tasks on the ModelNet40, ShapeNet Part, and S3DIS datasets. The experimental results indicate that VTPNet has good performance in 3D point cloud learning.
Unsupervised Segmentation for Terracotta Warrior with Seed-Region-Growing CNN(SRG-Net)
Jul 28, 2021
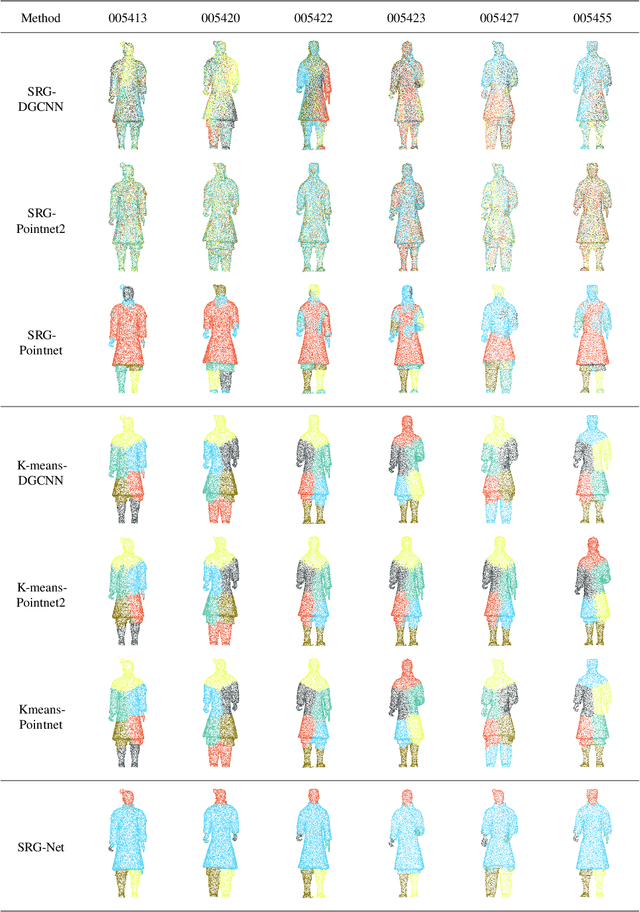
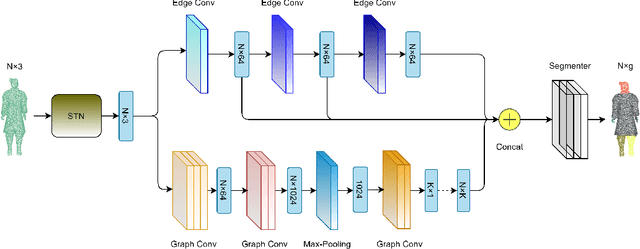
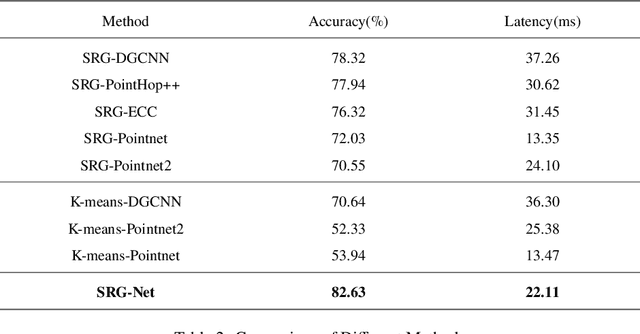
The repairing work of terracotta warriors in Emperor Qinshihuang Mausoleum Site Museum is handcrafted by experts, and the increasing amounts of unearthed pieces of terracotta warriors make the archaeologists too challenging to conduct the restoration of terracotta warriors efficiently. We hope to segment the 3D point cloud data of the terracotta warriors automatically and store the fragment data in the database to assist the archaeologists in matching the actual fragments with the ones in the database, which could result in higher repairing efficiency of terracotta warriors. Moreover, the existing 3D neural network research is mainly focusing on supervised classification, clustering, unsupervised representation, and reconstruction. There are few pieces of researches concentrating on unsupervised point cloud part segmentation. In this paper, we present SRG-Net for 3D point clouds of terracotta warriors to address these problems. Firstly, we adopt a customized seed-region-growing algorithm to segment the point cloud coarsely. Then we present a supervised segmentation and unsupervised reconstruction networks to learn the characteristics of 3D point clouds. Finally, we combine the SRG algorithm with our improved CNN using a refinement method. This pipeline is called SRG-Net, which aims at conducting segmentation tasks on the terracotta warriors. Our proposed SRG-Net is evaluated on the terracotta warriors data and ShapeNet dataset by measuring the accuracy and the latency. The experimental results show that our SRG-Net outperforms the state-of-the-art methods. Our code is shown in Code File 1~\cite{Srgnet_2021}.
Multi Point-Voxel Convolution (MPVConv) for Deep Learning on Point Clouds
Jul 28, 2021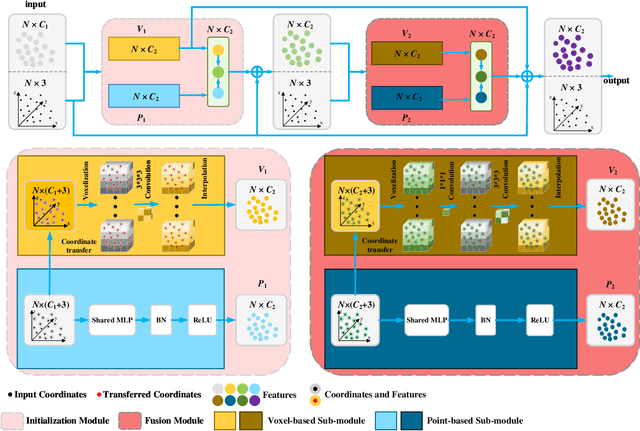



The existing 3D deep learning methods adopt either individual point-based features or local-neighboring voxel-based features, and demonstrate great potential for processing 3D data. However, the point based models are inefficient due to the unordered nature of point clouds and the voxel-based models suffer from large information loss. Motivated by the success of recent point-voxel representation, such as PVCNN, we propose a new convolutional neural network, called Multi Point-Voxel Convolution (MPVConv), for deep learning on point clouds. Integrating both the advantages of voxel and point-based methods, MPVConv can effectively increase the neighboring collection between point-based features and also promote independence among voxel-based features. Moreover, most of the existing approaches aim at solving one specific task, and only a few of them can handle a variety of tasks. Simply replacing the corresponding convolution module with MPVConv, we show that MPVConv can fit in different backbones to solve a wide range of 3D tasks. Extensive experiments on benchmark datasets such as ShapeNet Part, S3DIS and KITTI for various tasks show that MPVConv improves the accuracy of the backbone (PointNet) by up to \textbf{36\%}, and achieves higher accuracy than the voxel-based model with up to \textbf{34}$\times$ speedups. In addition, MPVConv outperforms the state-of-the-art point-based models with up to \textbf{8}$\times$ speedups. Notably, our MPVConv achieves better accuracy than the newest point-voxel-based model PVCNN (a model more efficient than PointNet) with lower latency.
Multi Voxel-Point Neurons Convolution (MVPConv) for Fast and Accurate 3D Deep Learning
Apr 30, 2021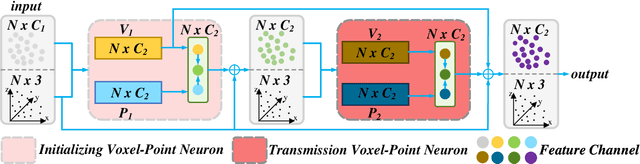
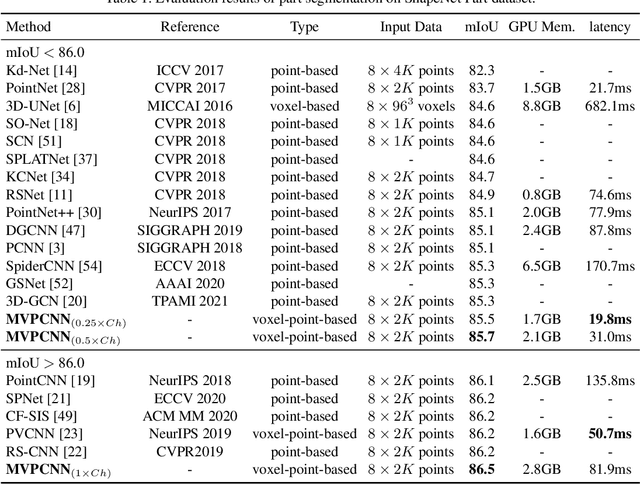
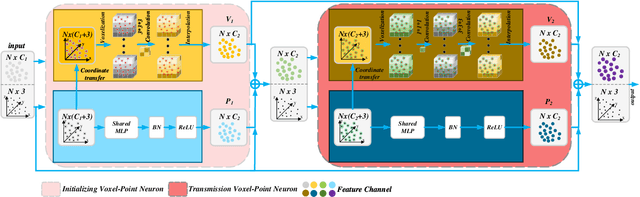
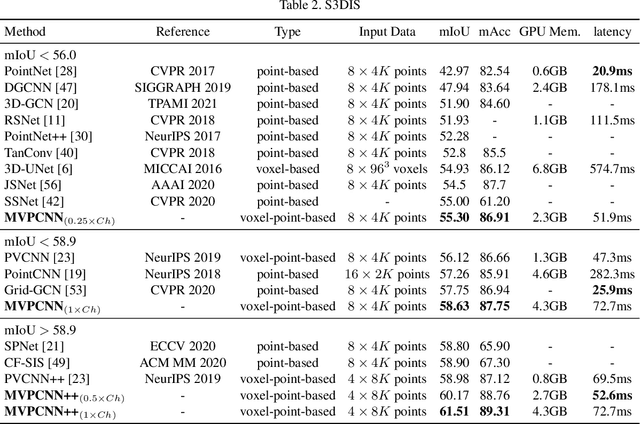
We present a new convolutional neural network, called Multi Voxel-Point Neurons Convolution (MVPConv), for fast and accurate 3D deep learning. The previous works adopt either individual point-based features or local-neighboring voxel-based features to process 3D model, which limits the performance of models due to the inefficient computation. Moreover, most of the existing 3D deep learning frameworks aim at solving one specific task, and only a few of them can handle a variety of tasks. Integrating both the advantages of the voxel and point-based methods, the proposed MVPConv can effectively increase the neighboring collection between point-based features and also promote the independence among voxel-based features. Simply replacing the corresponding convolution module with MVPConv, we show that MVPConv can fit in different backbones to solve a wide range of 3D tasks. Extensive experiments on benchmark datasets such as ShapeNet Part, S3DIS and KITTI for various tasks show that MVPConv improves the accuracy of the backbone (PointNet) by up to 36%, and achieves higher accuracy than the voxel-based model with up to 34 times speedup. In addition, MVPConv also outperforms the state-of-the-art point-based models with up to 8 times speedup. Notably, our MVPConv achieves better accuracy than the newest point-voxel-based model PVCNN (a model more efficient than PointNet) with lower latency.
SRG-Net: Unsupervised Segmentation for Terracotta Warrior Point Cloud with 3D Pointwise CNN methods
Dec 01, 2020
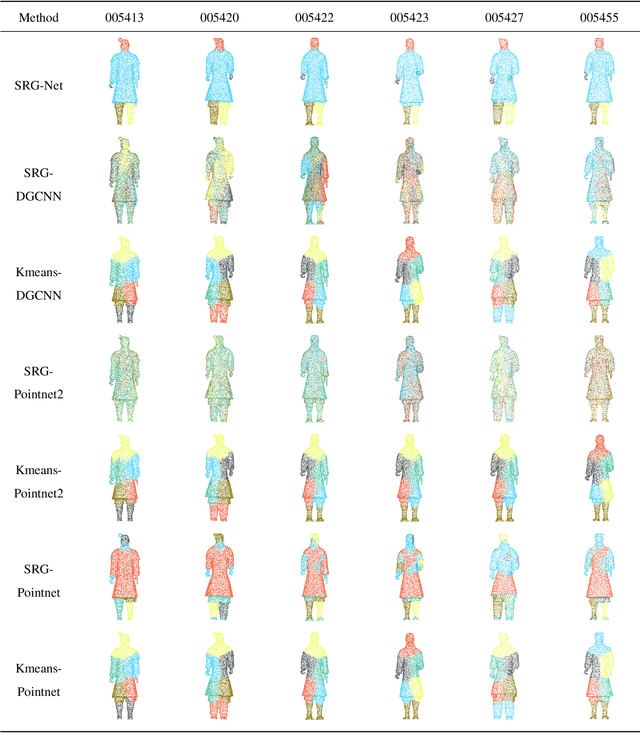
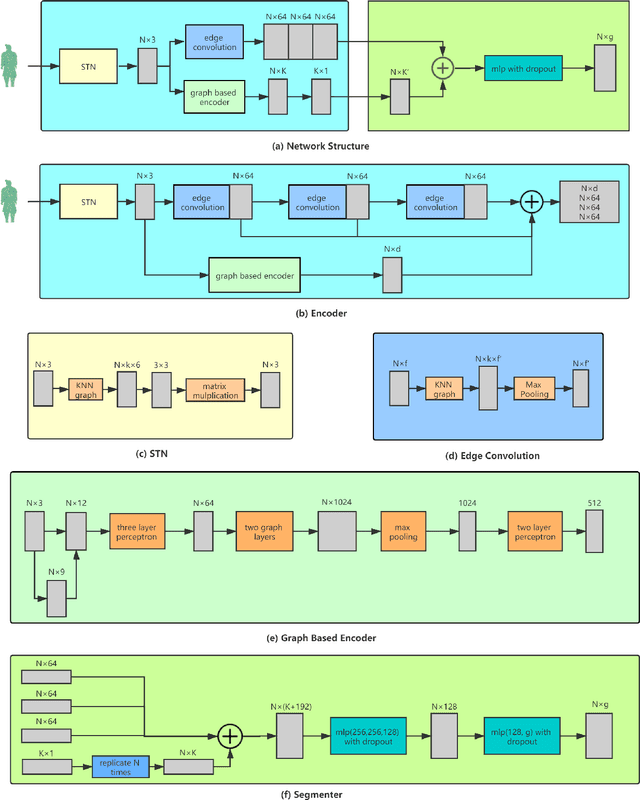
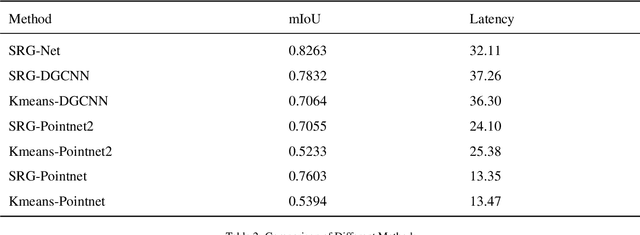
In this paper, we present a seed-region-growing CNN(SRG-Net) for unsupervised part segmentation with 3D point clouds of terracotta warriors. Previous neural network researches in 3D are mainly about supervised classification, clustering, unsupervised representation and reconstruction. There are few researches focusing on unsupervised point cloud part segmentation. To address these problems, we present a seed-region-growing CNN(SRG-Net) for unsupervised part segmentation with 3D point clouds of terracotta warriors. Firstly, we propose our customized seed region growing algorithm to coarsely segment the point cloud. Then we present our supervised segmentation and unsupervised reconstruction networks to better understand the characteristics of 3D point clouds. Finally, we combine the SRG algorithm with our improved CNN using a refinement method called SRG-Net to conduct the segmentation tasks on the terracotta warriors. Our proposed SRG-Net are evaluated on the terracotta warriors data and the benchmark dataset of ShapeNet with measuring mean intersection over union(mIoU) and latency. The experimental results show that our SRG-Net outperforms the state-of-the-art methods. Our code is available at https://github.com/hyoau/SRG-Net.