 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVTPNet for 3D deep learning on point cloud
Paper and Code
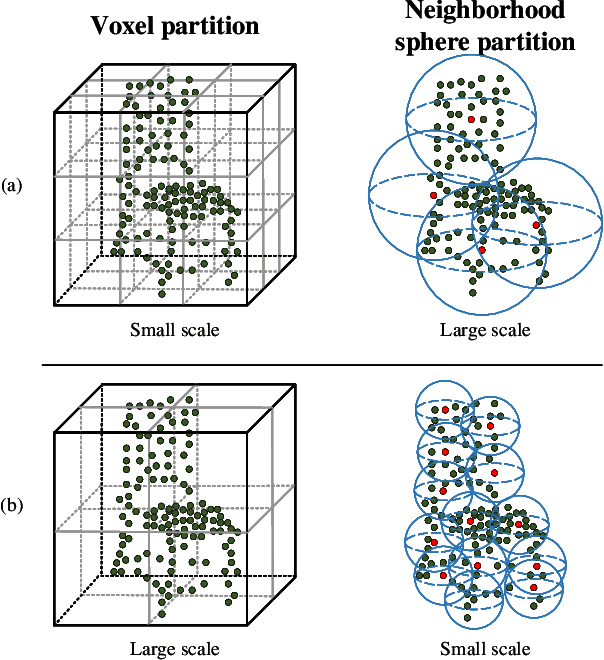
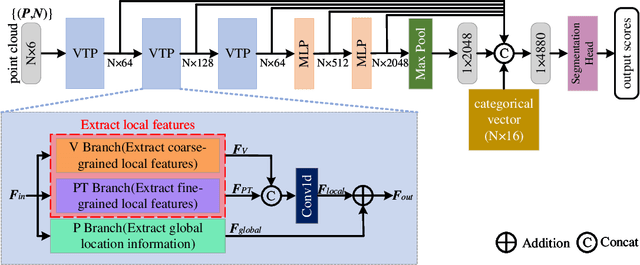
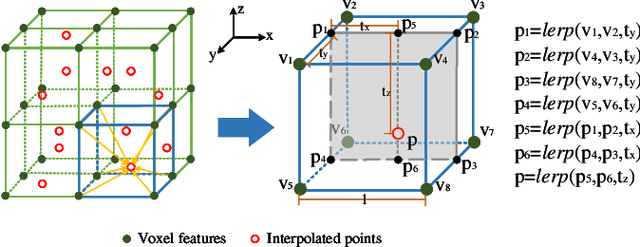

Recently, Transformer-based methods for point cloud learning have achieved good results on various point cloud learning benchmarks. However, since the attention mechanism needs to generate three feature vectors of query, key, and value to calculate attention features, most of the existing Transformer-based point cloud learning methods usually consume a large amount of computational time and memory resources when calculating global attention. To address this problem, we propose a Voxel-Transformer-Point (VTP) Block for extracting local and global features of point clouds. VTP combines the advantages of voxel-based, point-based and Transformer-based methods, which consists of Voxel-Based Branch (V branch), Point-Based Transformer Branch (PT branch) and Point-Based Branch (P branch). The V branch extracts the coarse-grained features of the point cloud through low voxel resolution; the PT branch obtains the fine-grained features of the point cloud by calculating the self-attention in the local neighborhood and the inter-neighborhood cross-attention; the P branch uses a simplified MLP network to generate the global location information of the point cloud. In addition, to enrich the local features of point clouds at different scales, we set the voxel scale in the V branch and the neighborhood sphere scale in the PT branch to one large and one small (large voxel scale \& small neighborhood sphere scale or small voxel scale \& large neighborhood sphere scale). Finally, we use VTP as the feature extraction network to construct a VTPNet for point cloud learning, and performs shape classification, part segmentation, and semantic segmentation tasks on the ModelNet40, ShapeNet Part, and S3DIS datasets. The experimental results indicate that VTPNet has good performance in 3D point cloud learning.