 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM3CoTBench: Benchmark Chain-of-Thought of MLLMs in Medical Image Understanding
Jan 13, 2026Chain-of-Thought (CoT) reasoning has proven effective in enhancing large language models by encouraging step-by-step intermediate reasoning, and recent advances have extended this paradigm to Multimodal Large Language Models (MLLMs). In the medical domain, where diagnostic decisions depend on nuanced visual cues and sequential reasoning, CoT aligns naturally with clinical thinking processes. However, Current benchmarks for medical image understanding generally focus on the final answer while ignoring the reasoning path. An opaque process lacks reliable bases for judgment, making it difficult to assist doctors in diagnosis. To address this gap, we introduce a new M3CoTBench benchmark specifically designed to evaluate the correctness, efficiency, impact, and consistency of CoT reasoning in medical image understanding. M3CoTBench features 1) a diverse, multi-level difficulty dataset covering 24 examination types, 2) 13 varying-difficulty tasks, 3) a suite of CoT-specific evaluation metrics (correctness, efficiency, impact, and consistency) tailored to clinical reasoning, and 4) a performance analysis of multiple MLLMs. M3CoTBench systematically evaluates CoT reasoning across diverse medical imaging tasks, revealing current limitations of MLLMs in generating reliable and clinically interpretable reasoning, and aims to foster the development of transparent, trustworthy, and diagnostically accurate AI systems for healthcare. Project page at https://juntaojianggavin.github.io/projects/M3CoTBench/.
Using Photoplethysmography to Detect Real-time Blood Pressure Changes with a Calibration-free Deep Learning Model
Jul 03, 2024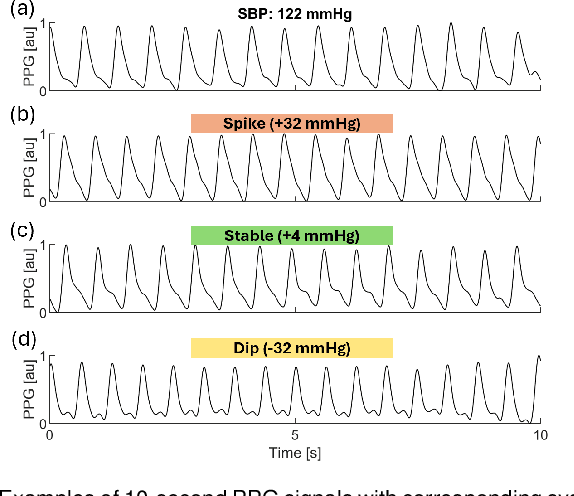
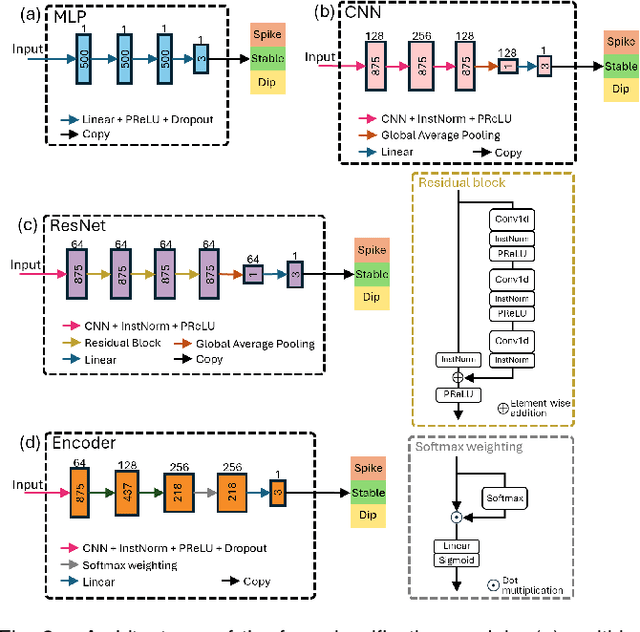


Blood pressure (BP) changes are linked to individual health status in both clinical and non-clinical settings. This study developed a deep learning model to classify systolic (SBP), diastolic (DBP), and mean (MBP) BP changes using photoplethysmography (PPG) waveforms. Data from the Vital Signs Database (VitalDB) comprising 1,005 ICU patients with synchronized PPG and BP recordings was used. BP changes were categorized into three labels: Spike (increase above a threshold), Stable (change within a plus or minus threshold), and Dip (decrease below a threshold). Four time-series classification models were studied: multi-layer perceptron, convolutional neural network, residual network, and Encoder. A subset of 500 patients was randomly selected for training and validation, ensuring a uniform distribution across BP change labels. Two test datasets were compiled: Test-I (n=500) with a uniform distribution selection process, and Test-II (n=5) without. The study also explored the impact of including second-deviation PPG (sdPPG) waveforms as additional input information. The Encoder model with a Softmax weighting process using both PPG and sdPPG waveforms achieved the highest detection accuracy--exceeding 71.3% and 85.4% in Test-I and Test-II, respectively, with thresholds of 30 mmHg for SBP, 15 mmHg for DBP, and 20 mmHg for MBP. Corresponding F1-scores were over 71.8% and 88.5%. These findings confirm that PPG waveforms are effective for real-time monitoring of BP changes in ICU settings and suggest potential for broader applications.
GTNet: Graph Transformer Network for 3D Point Cloud Classification and Semantic Segmentation
May 24, 2023Recently, graph-based and Transformer-based deep learning networks have demonstrated excellent performances on various point cloud tasks. Most of the existing graph methods are based on static graph, which take a fixed input to establish graph relations. Moreover, many graph methods apply maximization and averaging to aggregate neighboring features, so that only a single neighboring point affects the feature of centroid or different neighboring points have the same influence on the centroid's feature, which ignoring the correlation and difference between points. Most Transformer-based methods extract point cloud features based on global attention and lack the feature learning on local neighbors. To solve the problems of these two types of models, we propose a new feature extraction block named Graph Transformer and construct a 3D point point cloud learning network called GTNet to learn features of point clouds on local and global patterns. Graph Transformer integrates the advantages of graph-based and Transformer-based methods, and consists of Local Transformer and Global Transformer modules. Local Transformer uses a dynamic graph to calculate all neighboring point weights by intra-domain cross-attention with dynamically updated graph relations, so that every neighboring point could affect the features of centroid with different weights; Global Transformer enlarges the receptive field of Local Transformer by a global self-attention. In addition, to avoid the disappearance of the gradient caused by the increasing depth of network, we conduct residual connection for centroid features in GTNet; we also adopt the features of centroid and neighbors to generate the local geometric descriptors in Local Transformer to strengthen the local information learning capability of the model. Finally, we use GTNet for shape classification, part segmentation and semantic segmentation tasks in this paper.
VTPNet for 3D deep learning on point cloud
May 10, 2023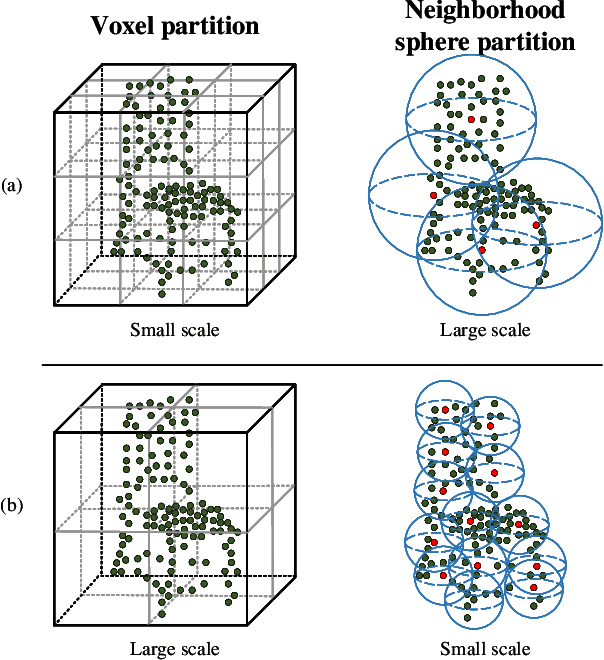
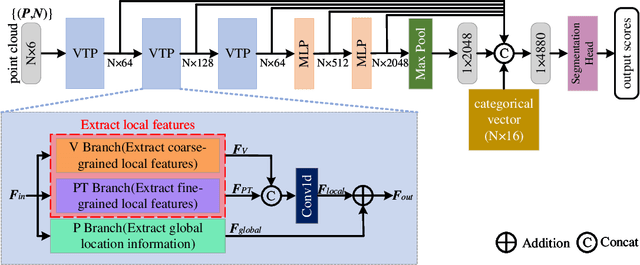
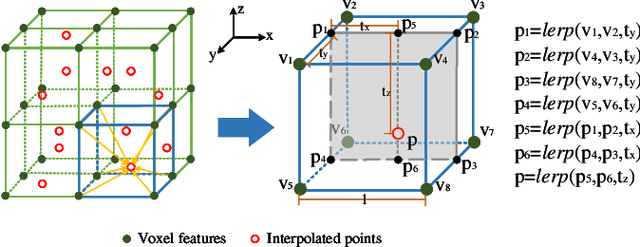

Recently, Transformer-based methods for point cloud learning have achieved good results on various point cloud learning benchmarks. However, since the attention mechanism needs to generate three feature vectors of query, key, and value to calculate attention features, most of the existing Transformer-based point cloud learning methods usually consume a large amount of computational time and memory resources when calculating global attention. To address this problem, we propose a Voxel-Transformer-Point (VTP) Block for extracting local and global features of point clouds. VTP combines the advantages of voxel-based, point-based and Transformer-based methods, which consists of Voxel-Based Branch (V branch), Point-Based Transformer Branch (PT branch) and Point-Based Branch (P branch). The V branch extracts the coarse-grained features of the point cloud through low voxel resolution; the PT branch obtains the fine-grained features of the point cloud by calculating the self-attention in the local neighborhood and the inter-neighborhood cross-attention; the P branch uses a simplified MLP network to generate the global location information of the point cloud. In addition, to enrich the local features of point clouds at different scales, we set the voxel scale in the V branch and the neighborhood sphere scale in the PT branch to one large and one small (large voxel scale \& small neighborhood sphere scale or small voxel scale \& large neighborhood sphere scale). Finally, we use VTP as the feature extraction network to construct a VTPNet for point cloud learning, and performs shape classification, part segmentation, and semantic segmentation tasks on the ModelNet40, ShapeNet Part, and S3DIS datasets. The experimental results indicate that VTPNet has good performance in 3D point cloud learning.