 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti Point-Voxel Convolution (MPVConv) for Deep Learning on Point Clouds
Paper and Code
Jul 28, 2021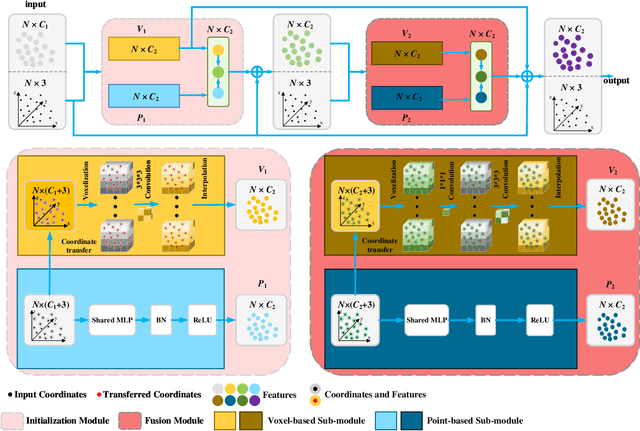



The existing 3D deep learning methods adopt either individual point-based features or local-neighboring voxel-based features, and demonstrate great potential for processing 3D data. However, the point based models are inefficient due to the unordered nature of point clouds and the voxel-based models suffer from large information loss. Motivated by the success of recent point-voxel representation, such as PVCNN, we propose a new convolutional neural network, called Multi Point-Voxel Convolution (MPVConv), for deep learning on point clouds. Integrating both the advantages of voxel and point-based methods, MPVConv can effectively increase the neighboring collection between point-based features and also promote independence among voxel-based features. Moreover, most of the existing approaches aim at solving one specific task, and only a few of them can handle a variety of tasks. Simply replacing the corresponding convolution module with MPVConv, we show that MPVConv can fit in different backbones to solve a wide range of 3D tasks. Extensive experiments on benchmark datasets such as ShapeNet Part, S3DIS and KITTI for various tasks show that MPVConv improves the accuracy of the backbone (PointNet) by up to \textbf{36\%}, and achieves higher accuracy than the voxel-based model with up to \textbf{34}$\times$ speedups. In addition, MPVConv outperforms the state-of-the-art point-based models with up to \textbf{8}$\times$ speedups. Notably, our MPVConv achieves better accuracy than the newest point-voxel-based model PVCNN (a model more efficient than PointNet) with lower latency.