 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePedestrian Attribute Recognition via Hierarchical Cross-Modality HyperGraph Learning
Sep 26, 2025Current Pedestrian Attribute Recognition (PAR) algorithms typically focus on mapping visual features to semantic labels or attempt to enhance learning by fusing visual and attribute information. However, these methods fail to fully exploit attribute knowledge and contextual information for more accurate recognition. Although recent works have started to consider using attribute text as additional input to enhance the association between visual and semantic information, these methods are still in their infancy. To address the above challenges, this paper proposes the construction of a multi-modal knowledge graph, which is utilized to mine the relationships between local visual features and text, as well as the relationships between attributes and extensive visual context samples. Specifically, we propose an effective multi-modal knowledge graph construction method that fully considers the relationships among attributes and the relationships between attributes and vision tokens. To effectively model these relationships, this paper introduces a knowledge graph-guided cross-modal hypergraph learning framework to enhance the standard pedestrian attribute recognition framework. Comprehensive experiments on multiple PAR benchmark datasets have thoroughly demonstrated the effectiveness of our proposed knowledge graph for the PAR task, establishing a strong foundation for knowledge-guided pedestrian attribute recognition. The source code of this paper will be released on https://github.com/Event-AHU/OpenPAR
Beyond Frequency: Seeing Subtle Cues Through the Lens of Spatial Decomposition for Fine-Grained Visual Classification
Aug 09, 2025


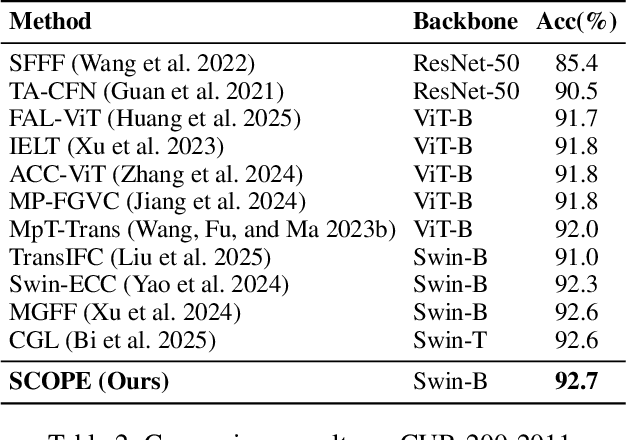
The crux of resolving fine-grained visual classification (FGVC) lies in capturing discriminative and class-specific cues that correspond to subtle visual characteristics. Recently, frequency decomposition/transform based approaches have attracted considerable interests since its appearing discriminative cue mining ability. However, the frequency-domain methods are based on fixed basis functions, lacking adaptability to image content and unable to dynamically adjust feature extraction according to the discriminative requirements of different images. To address this, we propose a novel method for FGVC, named Subtle-Cue Oriented Perception Engine (SCOPE), which adaptively enhances the representational capability of low-level details and high-level semantics in the spatial domain, breaking through the limitations of fixed scales in the frequency domain and improving the flexibility of multi-scale fusion. The core of SCOPE lies in two modules: the Subtle Detail Extractor (SDE), which dynamically enhances subtle details such as edges and textures from shallow features, and the Salient Semantic Refiner (SSR), which learns semantically coherent and structure-aware refinement features from the high-level features guided by the enhanced shallow features. The SDE and SSR are cascaded stage-by-stage to progressively combine local details with global semantics. Extensive experiments demonstrate that our method achieves new state-of-the-art on four popular fine-grained image classification benchmarks.
Information Re-Organization Improves Reasoning in Large Language Models
Apr 22, 2024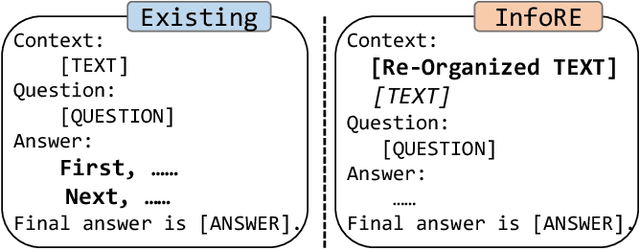
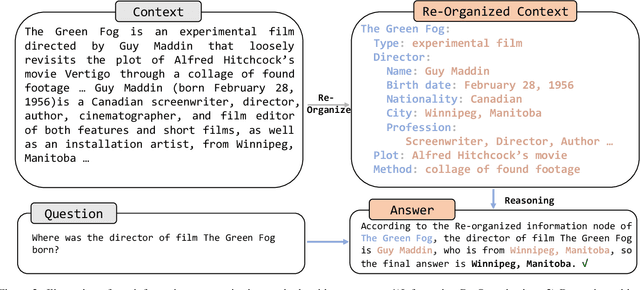
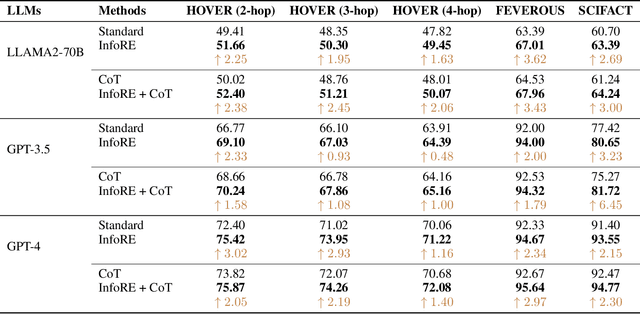
Improving the reasoning capabilities of large language models (LLMs) has attracted considerable interest. Recent approaches primarily focus on improving the reasoning process to yield a more precise final answer. However, in scenarios involving contextually aware reasoning, these methods neglect the importance of first identifying logical relationships from the context before proceeding with the reasoning. This oversight could lead to a superficial understanding and interaction with the context, potentially undermining the quality and reliability of the reasoning outcomes. In this paper, we propose an information re-organization (InfoRE) method before proceeding with the reasoning to enhance the reasoning ability of LLMs. We first perform a re-organization processing of the contextual content, e.g., documents or paragraphs, to obtain logical relationships. Then, we utilize the re-organized information in the reasoning process. This enables LLMs to deeply understand the contextual content by clearly perceiving these logical relationships. To demonstrate the effectiveness of our approach in improving the reasoning ability, we conduct experiments using Llama2-70B, GPT-3.5, and GPT-4 on various contextually aware multi-hop reasoning tasks. Using only a zero-shot setting, our method achieves an average improvement of 3\% across all tasks, highlighting its potential to improve the reasoning performance of LLMs. Our source code is available at https://github.com/hustcxx/InfoRE.
Improving Complex Knowledge Base Question Answering via Question-to-Action and Question-to-Question Alignment
Dec 26, 2022Complex knowledge base question answering can be achieved by converting questions into sequences of predefined actions. However, there is a significant semantic and structural gap between natural language and action sequences, which makes this conversion difficult. In this paper, we introduce an alignment-enhanced complex question answering framework, called ALCQA, which mitigates this gap through question-to-action alignment and question-to-question alignment. We train a question rewriting model to align the question and each action, and utilize a pretrained language model to implicitly align the question and KG artifacts. Moreover, considering that similar questions correspond to similar action sequences, we retrieve top-k similar question-answer pairs at the inference stage through question-to-question alignment and propose a novel reward-guided action sequence selection strategy to select from candidate action sequences. We conduct experiments on CQA and WQSP datasets, and the results show that our approach outperforms state-of-the-art methods and obtains a 9.88\% improvements in the F1 metric on CQA dataset. Our source code is available at https://github.com/TTTTTTTTy/ALCQA.
Query-based Instance Discrimination Network for Relational Triple Extraction
Nov 03, 2022Joint entity and relation extraction has been a core task in the field of information extraction. Recent approaches usually consider the extraction of relational triples from a stereoscopic perspective, either learning a relation-specific tagger or separate classifiers for each relation type. However, they still suffer from error propagation, relation redundancy and lack of high-level connections between triples. To address these issues, we propose a novel query-based approach to construct instance-level representations for relational triples. By metric-based comparison between query embeddings and token embeddings, we can extract all types of triples in one step, thus eliminating the error propagation problem. In addition, we learn the instance-level representation of relational triples via contrastive learning. In this way, relational triples can not only enclose rich class-level semantics but also access to high-order global connections. Experimental results show that our proposed method achieves the state of the art on five widely used benchmarks.