 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIM 2022 Challenge on Super-Resolution of Compressed Image and Video: Dataset, Methods and Results
Aug 25, 2022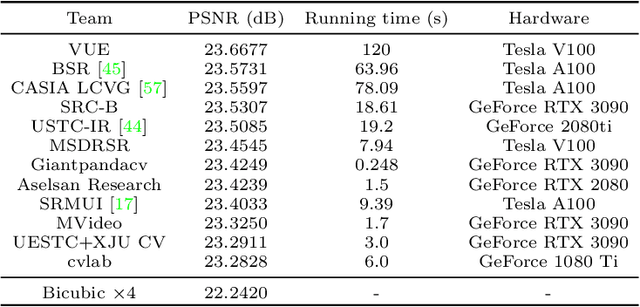
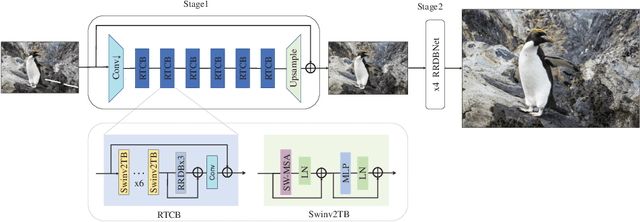

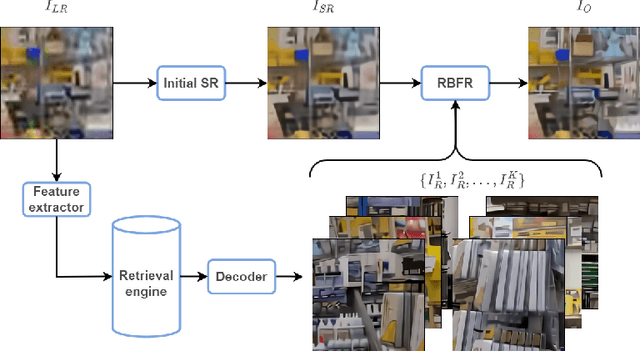
This paper reviews the Challenge on Super-Resolution of Compressed Image and Video at AIM 2022. This challenge includes two tracks. Track 1 aims at the super-resolution of compressed image, and Track~2 targets the super-resolution of compressed video. In Track 1, we use the popular dataset DIV2K as the training, validation and test sets. In Track 2, we propose the LDV 3.0 dataset, which contains 365 videos, including the LDV 2.0 dataset (335 videos) and 30 additional videos. In this challenge, there are 12 teams and 2 teams that submitted the final results to Track 1 and Track 2, respectively. The proposed methods and solutions gauge the state-of-the-art of super-resolution on compressed image and video. The proposed LDV 3.0 dataset is available at https://github.com/RenYang-home/LDV_dataset. The homepage of this challenge is at https://github.com/RenYang-home/AIM22_CompressSR.
Predicting origin-destination ride-sourcing demand with a spatio-temporal encoder-decoder residual multi-graph convolutional network
Oct 17, 2019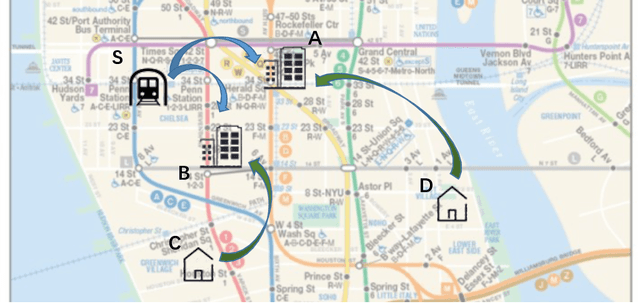
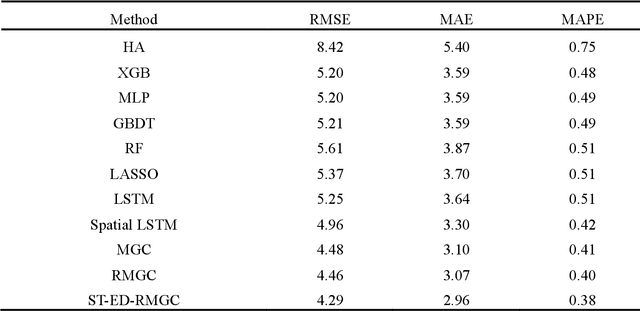

With the rapid development of mobile-internet technologies, on-demand ride-sourcing services have become increasingly popular and largely reshaped the way people travel. Demand prediction is one of the most fundamental components in supply-demand management systems of ride-sourcing platforms. With accurate short-term prediction for origin-destination (OD) demand, the platforms make precise and timely decisions on real-time matching, idle vehicle reallocations and ride-sharing vehicle routing, etc. Compared to zone-based demand prediction that has been examined by many previous studies, OD-based demand prediction is more challenging. This is mainly due to the complicated spatial and temporal dependencies among demand of different OD pairs. To overcome this challenge, we propose the Spatio-Temporal Encoder-Decoder Residual Multi-Graph Convolutional network (ST-ED-RMGC), a novel deep learning model for predicting ride-sourcing demand of various OD pairs. Firstly, the model constructs OD graphs, which utilize adjacent matrices to characterize the non-Euclidean pair-wise geographical and semantic correlations among different OD pairs. Secondly, based on the constructed graphs, a residual multi-graph convolutional (RMGC) network is designed to encode the contextual-aware spatial dependencies, and a long-short term memory (LSTM) network is used to encode the temporal dependencies, into a dense vector space. Finally, we reuse the RMGC networks to decode the compressed vector back to OD graphs and predict the future OD demand. Through extensive experiments on the for-hire-vehicles datasets in Manhattan, New York City, we show that our proposed deep learning framework outperforms the state-of-arts by a significant margin.