 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpsEval: A Comprehensive Task-Oriented AIOps Benchmark for Large Language Models
Oct 12, 2023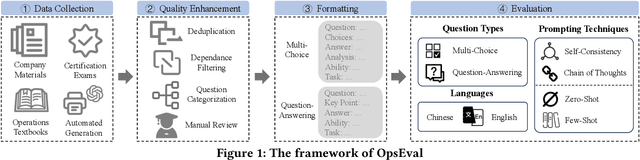
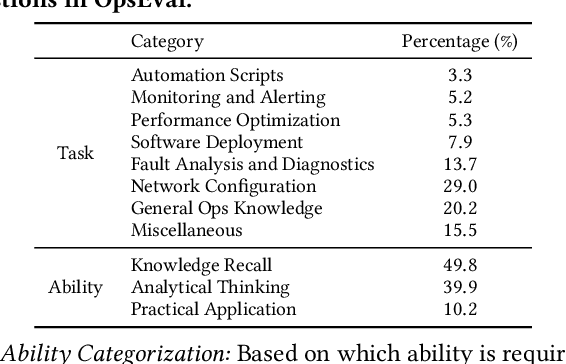

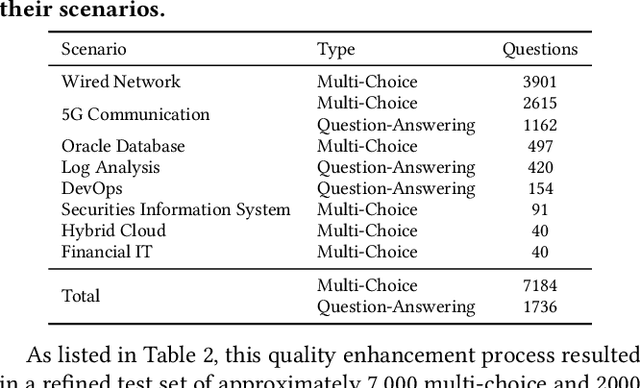
Large language models (LLMs) have exhibited remarkable capabilities in NLP-related tasks such as translation, summarizing, and generation. The application of LLMs in specific areas, notably AIOps (Artificial Intelligence for IT Operations), holds great potential due to their advanced abilities in information summarizing, report analyzing, and ability of API calling. Nevertheless, the performance of current LLMs in AIOps tasks is yet to be determined. Furthermore, a comprehensive benchmark is required to steer the optimization of LLMs tailored for AIOps. Compared with existing benchmarks that focus on evaluating specific fields like network configuration, in this paper, we present \textbf{OpsEval}, a comprehensive task-oriented AIOps benchmark designed for LLMs. For the first time, OpsEval assesses LLMs' proficiency in three crucial scenarios (Wired Network Operation, 5G Communication Operation, and Database Operation) at various ability levels (knowledge recall, analytical thinking, and practical application). The benchmark includes 7,200 questions in both multiple-choice and question-answer (QA) formats, available in English and Chinese. With quantitative and qualitative results, we show how various LLM tricks can affect the performance of AIOps, including zero-shot, chain-of-thought, and few-shot in-context learning. We find that GPT4-score is more consistent with experts than widely used Bleu and Rouge, which can be used to replace automatic metrics for large-scale qualitative evaluations.
Causal Inference-Based Root Cause Analysis for Online Service Systems with Intervention Recognition
Jun 13, 2022

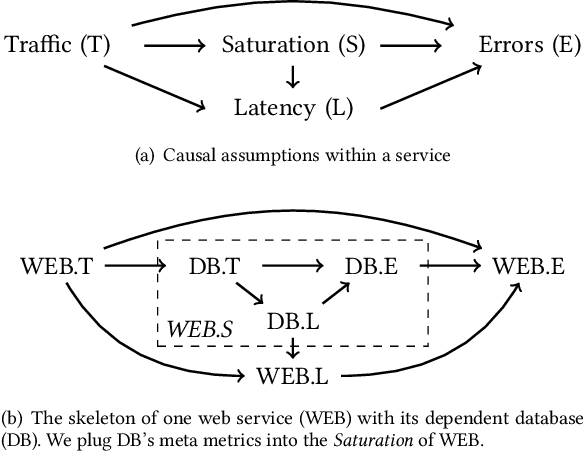
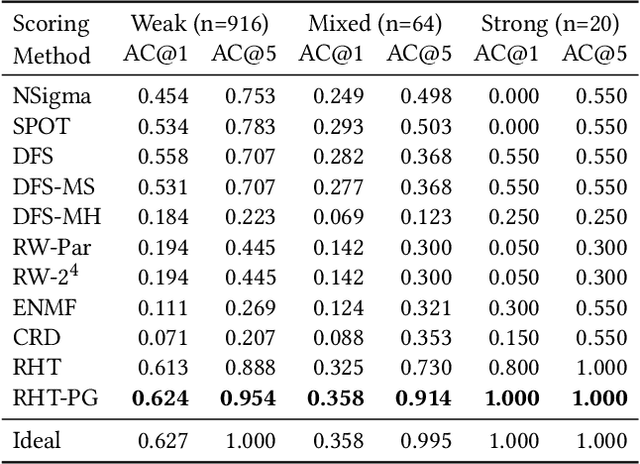
Fault diagnosis is critical in many domains, as faults may lead to safety threats or economic losses. In the field of online service systems, operators rely on enormous monitoring data to detect and mitigate failures. Quickly recognizing a small set of root cause indicators for the underlying fault can save much time for failure mitigation. In this paper, we formulate the root cause analysis problem as a new causal inference task named intervention recognition. We proposed a novel unsupervised causal inference-based method named Causal Inference-based Root Cause Analysis (CIRCA). The core idea is a sufficient condition for a monitoring variable to be a root cause indicator, i.e., the change of probability distribution conditioned on the parents in the Causal Bayesian Network (CBN). Towards the application in online service systems, CIRCA constructs a graph among monitoring metrics based on the knowledge of system architecture and a set of causal assumptions. The simulation study illustrates the theoretical reliability of CIRCA. The performance on a real-world dataset further shows that CIRCA can improve the recall of the top-1 recommendation by 25% over the best baseline method.
DOI: Divergence-based Out-of-Distribution Indicators via Deep Generative Models
Aug 12, 2021

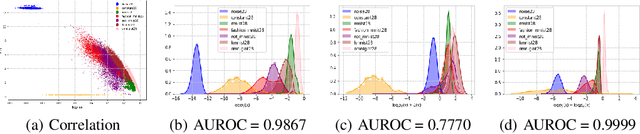

To ensure robust and reliable classification results, OoD (out-of-distribution) indicators based on deep generative models are proposed recently and are shown to work well on small datasets. In this paper, we conduct the first large collection of benchmarks (containing 92 dataset pairs, which is 1 order of magnitude larger than previous ones) for existing OoD indicators and observe that none perform well. We thus advocate that a large collection of benchmarks is mandatory for evaluating OoD indicators. We propose a novel theoretical framework, DOI, for divergence-based Out-of-Distribution indicators (instead of traditional likelihood-based) in deep generative models. Following this framework, we further propose a simple and effective OoD detection algorithm: Single-shot Fine-tune. It significantly outperforms past works by 5~8 in AUROC, and its performance is close to optimal. In recent, the likelihood criterion is shown to be ineffective in detecting OoD. Single-shot Fine-tune proposes a novel fine-tune criterion to detect OoD, by whether the likelihood of the testing sample is improved after fine-tuning a well-trained model on it. Fine-tune criterion is a clear and easy-following criterion, which will lead the OoD domain into a new stage.