 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraphCC: A Practical Graph Learning-based Approach to Congestion Control in Datacenters
Aug 09, 2023



Congestion Control (CC) plays a fundamental role in optimizing traffic in Data Center Networks (DCN). Currently, DCNs mainly implement two main CC protocols: DCTCP and DCQCN. Both protocols -- and their main variants -- are based on Explicit Congestion Notification (ECN), where intermediate switches mark packets when they detect congestion. The ECN configuration is thus a crucial aspect on the performance of CC protocols. Nowadays, network experts set static ECN parameters carefully selected to optimize the average network performance. However, today's high-speed DCNs experience quick and abrupt changes that severely change the network state (e.g., dynamic traffic workloads, incast events, failures). This leads to under-utilization and sub-optimal performance. This paper presents GraphCC, a novel Machine Learning-based framework for in-network CC optimization. Our distributed solution relies on a novel combination of Multi-agent Reinforcement Learning (MARL) and Graph Neural Networks (GNN), and it is compatible with widely deployed ECN-based CC protocols. GraphCC deploys distributed agents on switches that communicate with their neighbors to cooperate and optimize the global ECN configuration. In our evaluation, we test the performance of GraphCC under a wide variety of scenarios, focusing on the capability of this solution to adapt to new scenarios unseen during training (e.g., new traffic workloads, failures, upgrades). We compare GraphCC with a state-of-the-art MARL-based solution for ECN tuning -- ACC -- and observe that our proposed solution outperforms the state-of-the-art baseline in all of the evaluation scenarios, showing improvements up to $20\%$ in Flow Completion Time as well as significant reductions in buffer occupancy ($38.0-85.7\%$).
Neural Quantile Optimization for Edge-Cloud Computing
Jul 11, 2023



We seek the best traffic allocation scheme for the edge-cloud computing network that satisfies constraints and minimizes the cost based on burstable billing. First, for a fixed network topology, we formulate a family of integer programming problems with random parameters describing the various traffic demands. Then, to overcome the difficulty caused by the discrete feature of the problem, we generalize the Gumbel-softmax reparameterization method to induce an unconstrained continuous optimization problem as a regularized continuation of the discrete problem. Finally, we introduce the Gumbel-softmax sampling network to solve the optimization problems via unsupervised learning. The network structure reflects the edge-cloud computing topology and is trained to minimize the expectation of the cost function for unconstrained continuous optimization problems. The trained network works as an efficient traffic allocation scheme sampler, remarkably outperforming the random strategy in feasibility and cost function value. Besides testing the quality of the output allocation scheme, we examine the generalization property of the network by increasing the time steps and the number of users. We also feed the solution to existing integer optimization solvers as initial conditions and verify the warm-starts can accelerate the short-time iteration process. The framework is general with solid performance, and the decoupled feature of the random neural networks is adequate for practical implementations.
MAGNNETO: A Graph Neural Network-based Multi-Agent system for Traffic Engineering
Mar 31, 2023



Current trends in networking propose the use of Machine Learning (ML) for a wide variety of network optimization tasks. As such, many efforts have been made to produce ML-based solutions for Traffic Engineering (TE), which is a fundamental problem in ISP networks. Nowadays, state-of-the-art TE optimizers rely on traditional optimization techniques, such as Local search, Constraint Programming, or Linear programming. In this paper, we present MAGNNETO, a distributed ML-based framework that leverages Multi-Agent Reinforcement Learning and Graph Neural Networks for distributed TE optimization. MAGNNETO deploys a set of agents across the network that learn and communicate in a distributed fashion via message exchanges between neighboring agents. Particularly, we apply this framework to optimize link weights in OSPF, with the goal of minimizing network congestion. In our evaluation, we compare MAGNNETO against several state-of-the-art TE optimizers in more than 75 topologies (up to 153 nodes and 354 links), including realistic traffic loads. Our experimental results show that, thanks to its distributed nature, MAGNNETO achieves comparable performance to state-of-the-art TE optimizers with significantly lower execution times. Moreover, our ML-based solution demonstrates a strong generalization capability to successfully operate in new networks unseen during training.
RouteNet-Fermi: Network Modeling with Graph Neural Networks
Dec 22, 2022



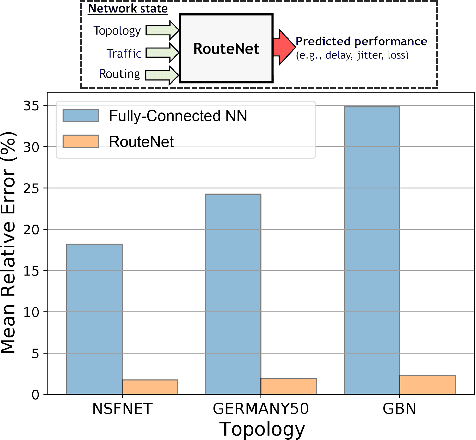
Network models are an essential block of modern networks. For example, they are widely used in network planning and optimization. However, as networks increase in scale and complexity, some models present limitations, such as the assumption of markovian traffic in queuing theory models, or the high computational cost of network simulators. Recent advances in machine learning, such as Graph Neural Networks (GNN), are enabling a new generation of network models that are data-driven and can learn complex non-linear behaviors. In this paper, we present RouteNet-Fermi, a custom GNN model that shares the same goals as queuing theory, while being considerably more accurate in the presence of realistic traffic models. The proposed model predicts accurately the delay, jitter, and loss in networks. We have tested RouteNet-Fermi in networks of increasing size (up to 300 nodes), including samples with mixed traffic profiles -- e.g., with complex non-markovian models -- and arbitrary routing and queue scheduling configurations. Our experimental results show that RouteNet-Fermi achieves similar accuracy as computationally-expensive packet-level simulators and it is able to accurately scale to large networks. For example, the model produces delay estimates with a mean relative error of 6.24% when applied to a test dataset with 1,000 samples, including network topologies one order of magnitude larger than those seen during training.
RouteNet-Erlang: A Graph Neural Network for Network Performance Evaluation
Feb 28, 2022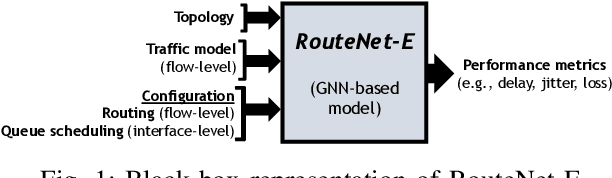
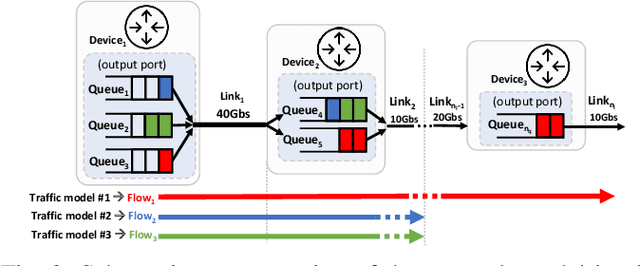
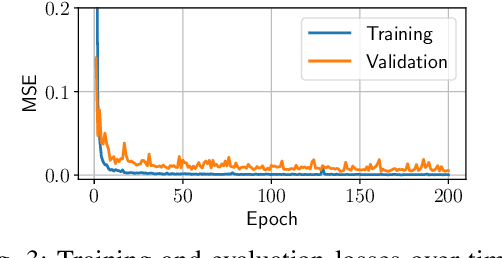
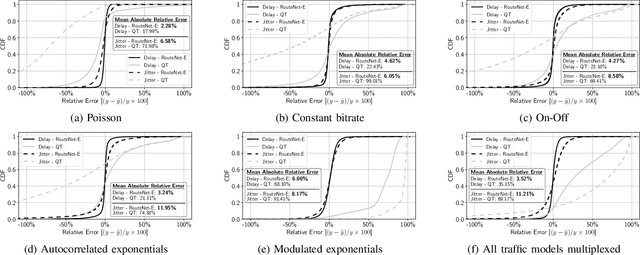
Network modeling is a fundamental tool in network research, design, and operation. Arguably the most popular method for modeling is Queuing Theory (QT). Its main limitation is that it imposes strong assumptions on the packet arrival process, which typically do not hold in real networks. In the field of Deep Learning, Graph Neural Networks (GNN) have emerged as a new technique to build data-driven models that can learn complex and non-linear behavior. In this paper, we present \emph{RouteNet-Erlang}, a pioneering GNN architecture designed to model computer networks. RouteNet-Erlang supports complex traffic models, multi-queue scheduling policies, routing policies and can provide accurate estimates in networks not seen in the training phase. We benchmark RouteNet-Erlang against a state-of-the-art QT model, and our results show that it outperforms QT in all the network scenarios.
Accelerating Deep Reinforcement Learning for Digital Twin Network Optimization with Evolutionary Strategies
Feb 01, 2022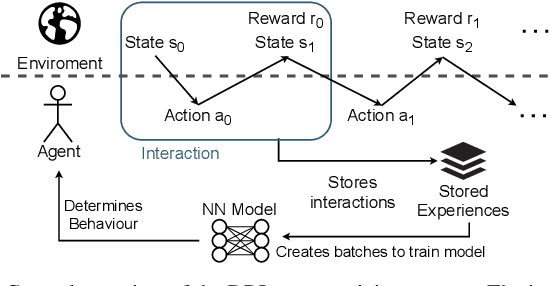
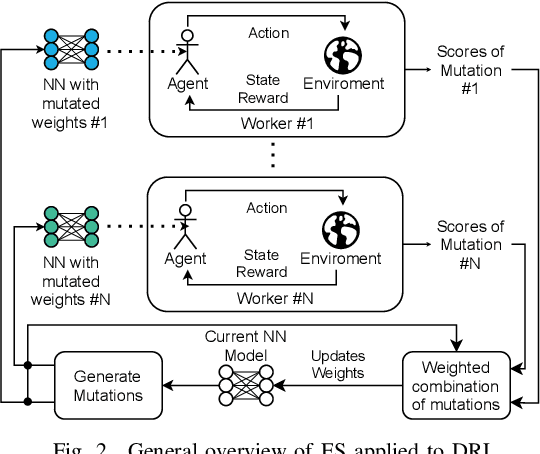
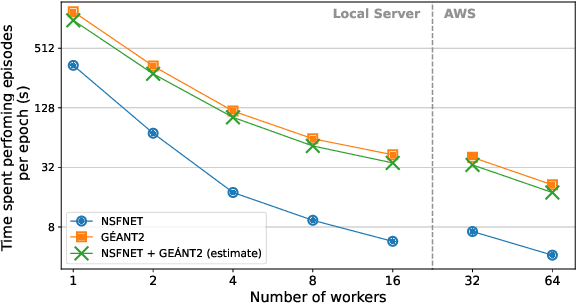
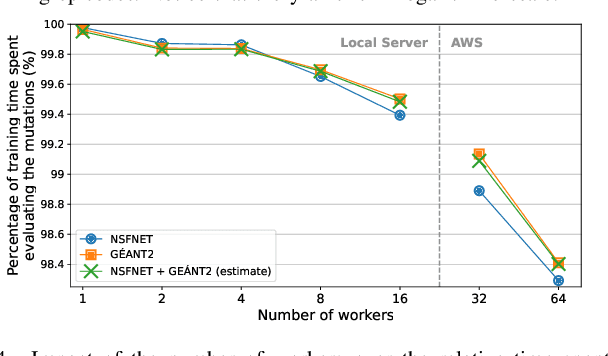
The recent growth of emergent network applications (e.g., satellite networks, vehicular networks) is increasing the complexity of managing modern communication networks. As a result, the community proposed the Digital Twin Networks (DTN) as a key enabler of efficient network management. Network operators can leverage the DTN to perform different optimization tasks (e.g., Traffic Engineering, Network Planning). Deep Reinforcement Learning (DRL) showed a high performance when applied to solve network optimization problems. In the context of DTN, DRL can be leveraged to solve optimization problems without directly impacting the real-world network behavior. However, DRL scales poorly with the problem size and complexity. In this paper, we explore the use of Evolutionary Strategies (ES) to train DRL agents for solving a routing optimization problem. The experimental results show that ES achieved a training time speed-up of 128 and 6 for the NSFNET and GEANT2 topologies respectively.
Graph Neural Networks for Communication Networks: Context, Use Cases and Opportunities
Dec 29, 2021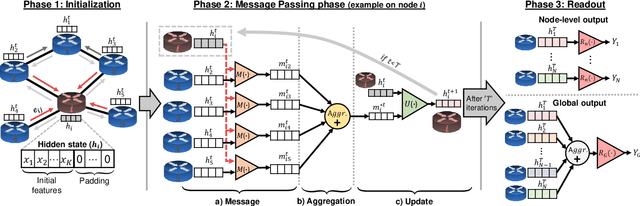
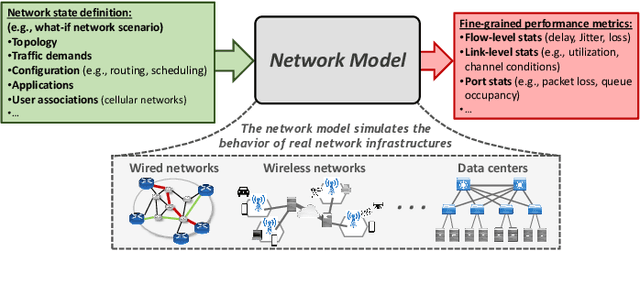
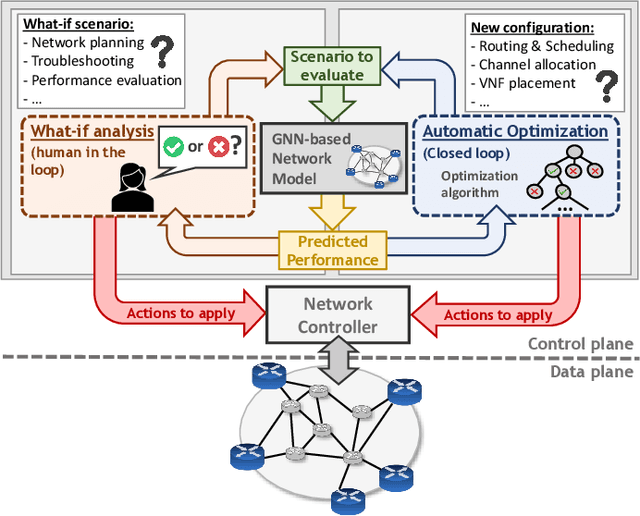
Graph neural networks (GNN) have shown outstanding applications in many fields where data is fundamentally represented as graphs (e.g., chemistry, biology, recommendation systems). In this vein, communication networks comprise many fundamental components that are naturally represented in a graph-structured manner (e.g., topology, configurations, traffic flows). This position article presents GNNs as a fundamental tool for modeling, control and management of communication networks. GNNs represent a new generation of data-driven models that can accurately learn and reproduce the complex behaviors behind real networks. As a result, such models can be applied to a wide variety of networking use cases, such as planning, online optimization, or troubleshooting. The main advantage of GNNs over traditional neural networks lies in its unprecedented generalization capabilities when applied to other networks and configurations unseen during training, which is a critical feature for achieving practical data-driven solutions for networking. This article comprises a brief tutorial on GNNs and their possible applications to communication networks. To showcase the potential of this technology, we present two use cases with state-of-the-art GNN models respectively applied to wired and wireless networks. Lastly, we delve into the key open challenges and opportunities yet to be explored in this novel research area.
Physics Constrained Flow Neural Network for Short-Timescale Predictions in Data Communications Networks
Dec 23, 2021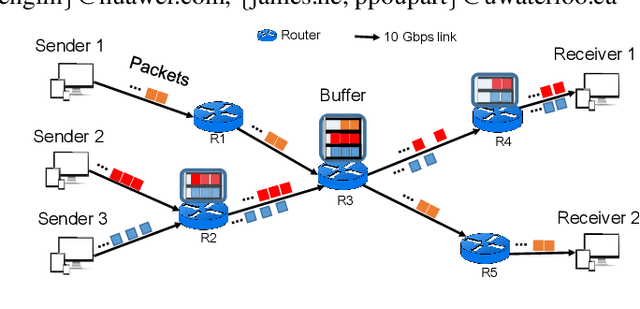

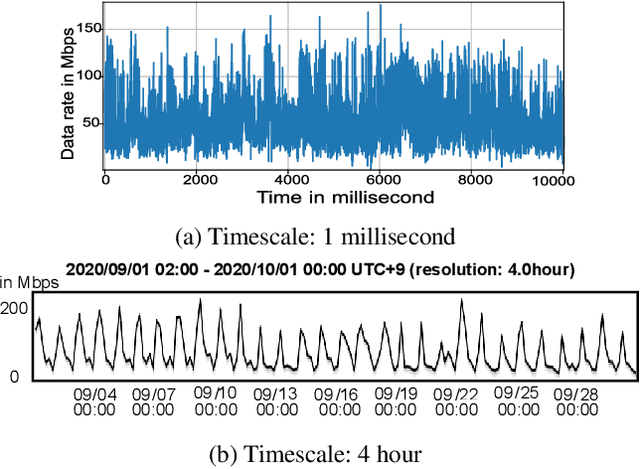
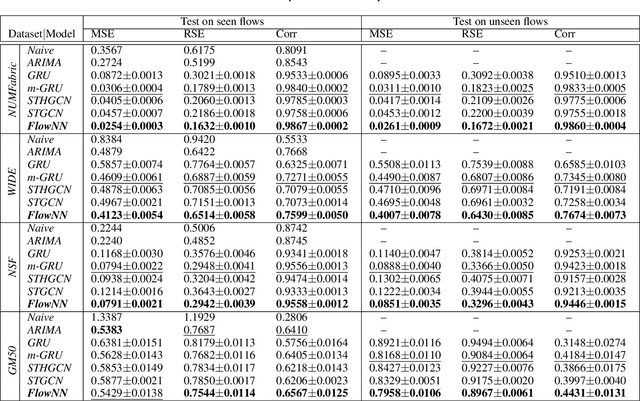
Machine learning is gaining growing momentum in various recent models for the dynamic analysis of information flows in data communications networks. These preliminary models often rely on off-the-shelf learning models to predict from historical statistics while disregarding the physics governing the generating behaviors of these flows. This paper instead introduces Flow Neural Network (FlowNN) to improve the feature representation with learned physical bias. This is implemented by an induction layer, working upon the embedding layer, to impose the physics connected data correlations, and a self-supervised learning strategy with stop-gradient to make the learned physics universal. For the short-timescale network prediction tasks, FlowNN achieves 17% - 71% of loss decrease than the state-of-the-art baselines on both synthetic and real-world networking datasets, which shows the strength of this new approach. Code will be made available.
ENERO: Efficient Real-Time Routing Optimization
Sep 22, 2021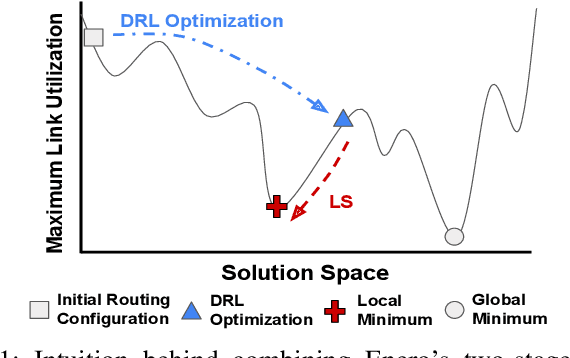
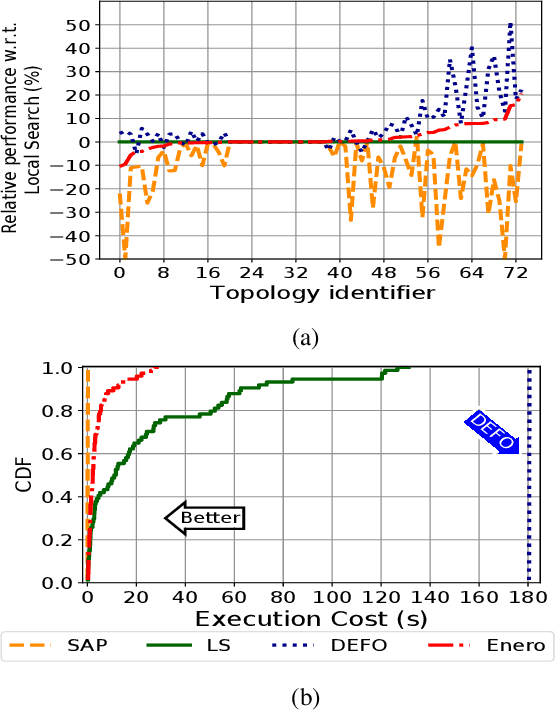
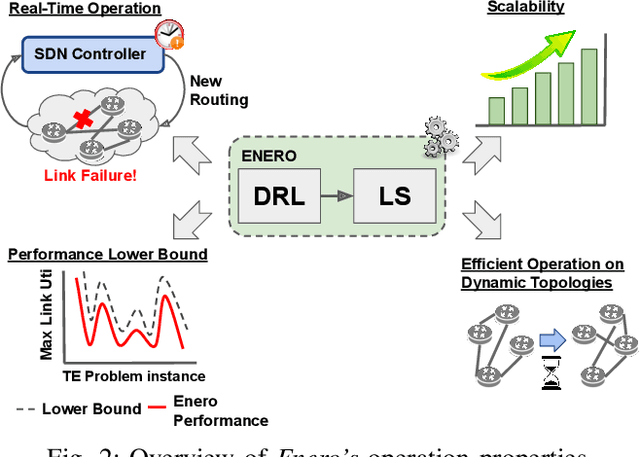

Wide Area Networks (WAN) are a key infrastructure in today's society. During the last years, WANs have seen a considerable increase in network's traffic as well as in the number of network applications. To enable the deployment of emergent network applications (e.g., Vehicular networks, Internet of Things), existing Traffic Engineering (TE) solutions must be able to achieve high performance real-time network operation. In addition, TE solutions must be able to adapt to dynamic scenarios (e.g., changes in the traffic matrix or topology link failures). However, current TE technologies rely on hand-crafted heuristics or computationally expensive solvers, which are not suitable for highly dynamic TE scenarios. In this paper we propose Enero, an efficient real-time TE engine. Enero is based on a two-stage optimization process. In the first one, it leverages Deep Reinforcement Learning (DRL) to optimize the routing configuration by generating a long-term TE strategy. We integrated a Graph Neural Network (GNN) into the DRL agent to enable efficient TE on dynamic networks. In the second stage, Enero uses a Local Search algorithm to improve DRL's solution without adding computational overhead to the optimization process. Enero offers a lower bound in performance, enabling the network operator to know the worst-case performance of the DRL agent. We believe that the lower bound in performance will lighten the path of deploying DRL-based solutions in real-world network scenarios. The experimental results indicate that Enero is able to operate in real-world dynamic network topologies in 4.5 seconds on average for topologies up to 100 edges.
Is Machine Learning Ready for Traffic Engineering Optimization?
Sep 03, 2021
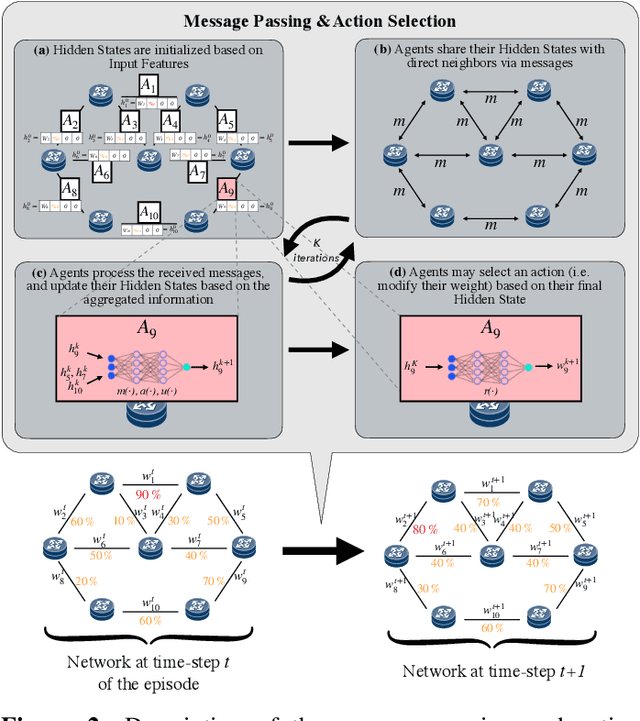
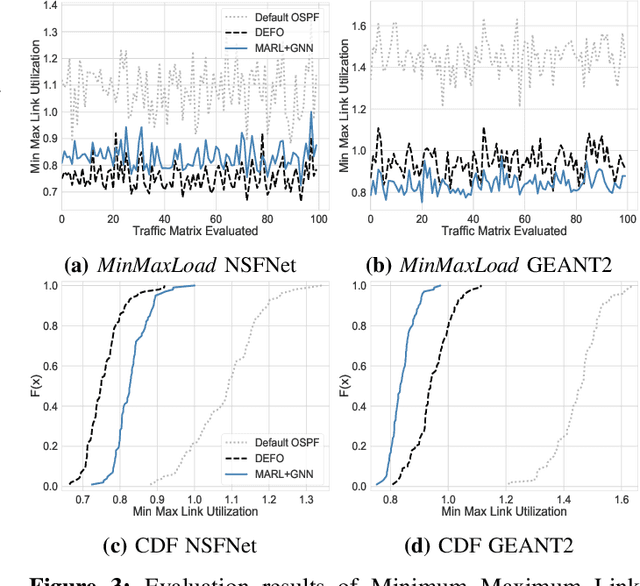
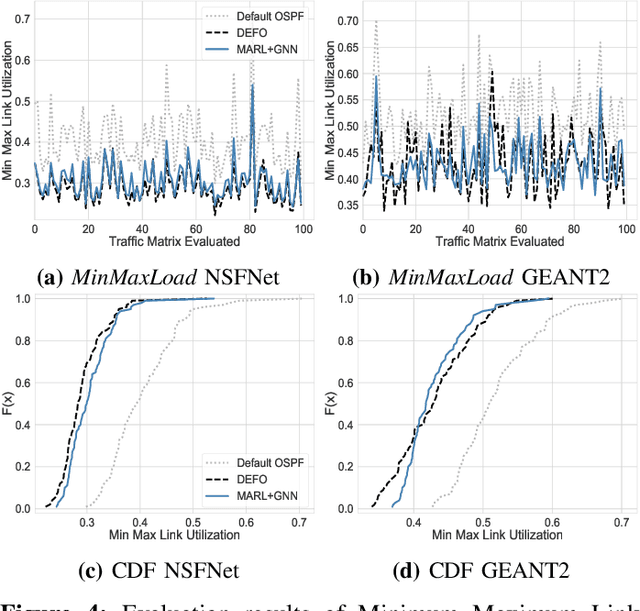
Traffic Engineering (TE) is a basic building block of the Internet. In this paper, we analyze whether modern Machine Learning (ML) methods are ready to be used for TE optimization. We address this open question through a comparative analysis between the state of the art in ML and the state of the art in TE. To this end, we first present a novel distributed system for TE that leverages the latest advancements in ML. Our system implements a novel architecture that combines Multi-Agent Reinforcement Learning (MARL) and Graph Neural Networks (GNN) to minimize network congestion. In our evaluation, we compare our MARL+GNN system with DEFO, a network optimizer based on Constraint Programming that represents the state of the art in TE. Our experimental results show that the proposed MARL+GNN solution achieves equivalent performance to DEFO in a wide variety of network scenarios including three real-world network topologies. At the same time, we show that MARL+GNN can achieve significant reductions in execution time (from the scale of minutes with DEFO to a few seconds with our solution).