 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Robustness of Kernel Ridge Regression Using the Cauchy Loss Function
Mar 26, 2025



Robust regression aims to develop methods for estimating an unknown regression function in the presence of outliers, heavy-tailed distributions, or contaminated data, which can severely impact performance. Most existing theoretical results in robust regression assume that the noise has a finite absolute mean, an assumption violated by certain distributions, such as Cauchy and some Pareto noise. In this paper, we introduce a generalized Cauchy noise framework that accommodates all noise distributions with finite moments of any order, even when the absolute mean is infinite. Within this framework, we study the \textit{kernel Cauchy ridge regressor} (\textit{KCRR}), which minimizes a regularized empirical Cauchy risk to achieve robustness. To derive the $L_2$-risk bound for KCRR, we establish a connection between the excess Cauchy risk and $L_2$-risk for sufficiently large scale parameters of the Cauchy loss, which reveals that these two risks are equivalent. Furthermore, under the assumption that the regression function satisfies H\"older smoothness, we derive excess Cauchy risk bounds for KCRR, showing improved performance as the scale parameter decreases. By considering the twofold effect of the scale parameter on the excess Cauchy risk and its equivalence with the $L_2$-risk, we establish the almost minimax-optimal convergence rate for KCRR in terms of $L_2$-risk, highlighting the robustness of the Cauchy loss in handling various types of noise. Finally, we validate the effectiveness of KCRR through experiments on both synthetic and real-world datasets under diverse noise corruption scenarios.
A/B/n Testing with Control in the Presence of Subpopulations
Oct 29, 2021
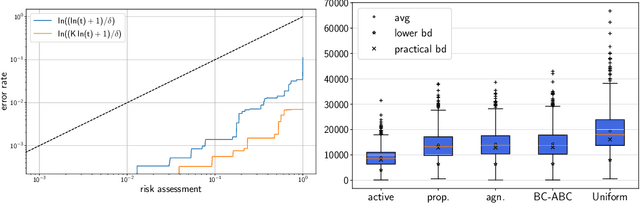

Motivated by A/B/n testing applications, we consider a finite set of distributions (called \emph{arms}), one of which is treated as a \emph{control}. We assume that the population is stratified into homogeneous subpopulations. At every time step, a subpopulation is sampled and an arm is chosen: the resulting observation is an independent draw from the arm conditioned on the subpopulation. The quality of each arm is assessed through a weighted combination of its subpopulation means. We propose a strategy for sequentially choosing one arm per time step so as to discover as fast as possible which arms, if any, have higher weighted expectation than the control. This strategy is shown to be asymptotically optimal in the following sense: if $\tau_\delta$ is the first time when the strategy ensures that it is able to output the correct answer with probability at least $1-\delta$, then $\mathbb{E}[\tau_\delta]$ grows linearly with $\log(1/\delta)$ at the exact optimal rate. This rate is identified in the paper in three different settings: (1) when the experimenter does not observe the subpopulation information, (2) when the subpopulation of each sample is observed but not chosen, and (3) when the experimenter can select the subpopulation from which each response is sampled. We illustrate the efficiency of the proposed strategy with numerical simulations on synthetic and real data collected from an A/B/n experiment.
Safe Testing
Jun 18, 2019


We present a new theory of hypothesis testing. The main concept is the S-value, a notion of evidence which, unlike p-values, allows for effortlessly combining evidence from several tests, even in the common scenario where the decision to perform a new test depends on the previous test outcome: safe tests based on S-values generally preserve Type-I error guarantees under such "optional continuation". S-values exist for completely general testing problems with composite null and alternatives. Their prime interpretation is in terms of gambling or investing, each S-value corresponding to a particular investment. Surprisingly, optimal "GROW" S-values, which lead to fastest capital growth, are fully characterized by the joint information projection (JIPr) between the set of all Bayes marginal distributions on H0 and H1. Thus, optimal S-values also have an interpretation as Bayes factors, with priors given by the JIPr. We illustrate the theory using two classical testing scenarios: the one-sample t-test and the 2x2 contingency table. In the t-test setting, GROW s-values correspond to adopting the right Haar prior on the variance, like in Jeffreys' Bayesian t-test. However, unlike Jeffreys', the "default" safe t-test puts a discrete 2-point prior on the effect size, leading to better behavior in terms of statistical power. Sharing Fisherian, Neymanian and Jeffreys-Bayesian interpretations, S-values and safe tests may provide a methodology acceptable to adherents of all three schools.
Mixture Martingales Revisited with Applications to Sequential Tests and Confidence Intervals
Nov 28, 2018
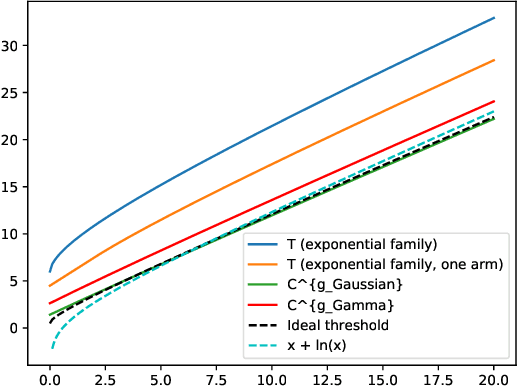
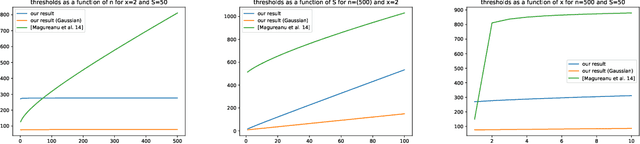
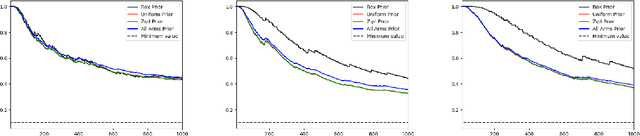
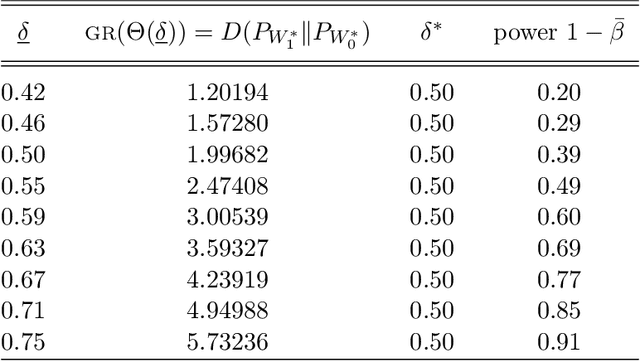
This paper presents new deviation inequalities that are valid uniformly in time under adaptive sampling in a multi-armed bandit model. The deviations are measured using the Kullback-Leibler divergence in a given one-dimensional exponential family, and may take into account several arms at a time. They are obtained by constructing for each arm a mixture martingale based on a hierarchical prior, and by multiplying those martingales. Our deviation inequalities allow us to analyze stopping rules based on generalized likelihood ratios for a large class of sequential identification problems, and to construct tight confidence intervals for some functions of the means of the arms.
Sequential Test for the Lowest Mean: From Thompson to Murphy Sampling
Jun 04, 2018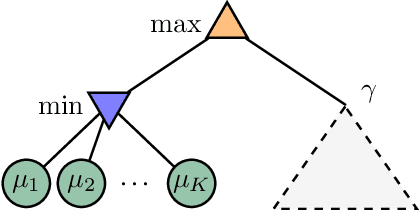
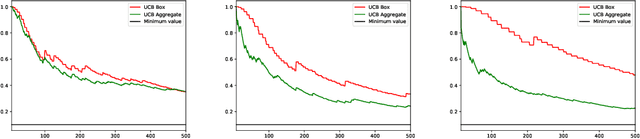
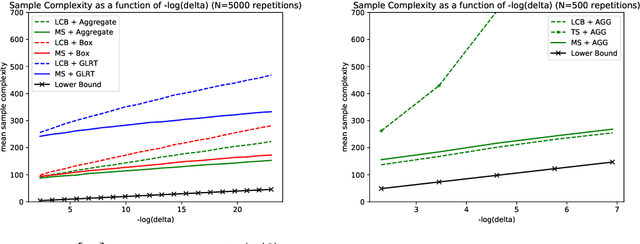
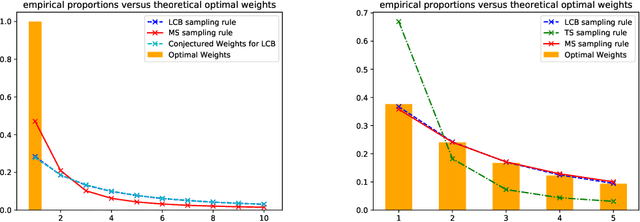
Learning the minimum/maximum mean among a finite set of distributions is a fundamental sub-task in planning, game tree search and reinforcement learning. We formalize this learning task as the problem of sequentially testing how the minimum mean among a finite set of distributions compares to a given threshold. We develop refined non-asymptotic lower bounds, which show that optimality mandates very different sampling behavior for a low vs high true minimum. We show that Thompson Sampling and the intuitive Lower Confidence Bounds policy each nail only one of these cases. We develop a novel approach that we call Murphy Sampling. Even though it entertains exclusively low true minima, we prove that MS is optimal for both possibilities. We then design advanced self-normalized deviation inequalities, fueling more aggressive stopping rules. We complement our theoretical guarantees by experiments showing that MS works best in practice.
Monte-Carlo Tree Search by Best Arm Identification
Nov 06, 2017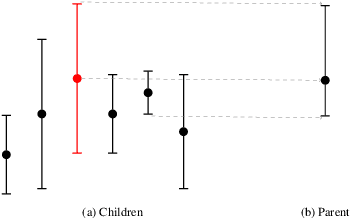
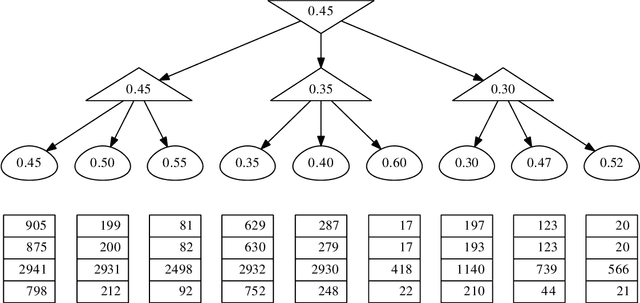
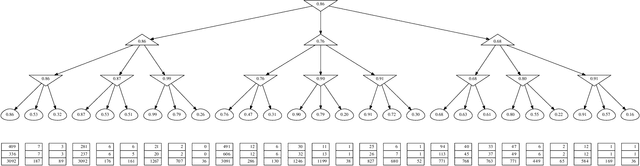
Recent advances in bandit tools and techniques for sequential learning are steadily enabling new applications and are promising the resolution of a range of challenging related problems. We study the game tree search problem, where the goal is to quickly identify the optimal move in a given game tree by sequentially sampling its stochastic payoffs. We develop new algorithms for trees of arbitrary depth, that operate by summarizing all deeper levels of the tree into confidence intervals at depth one, and applying a best arm identification procedure at the root. We prove new sample complexity guarantees with a refined dependence on the problem instance. We show experimentally that our algorithms outperform existing elimination-based algorithms and match previous special-purpose methods for depth-two trees.
Maximin Action Identification: A New Bandit Framework for Games
Feb 15, 2016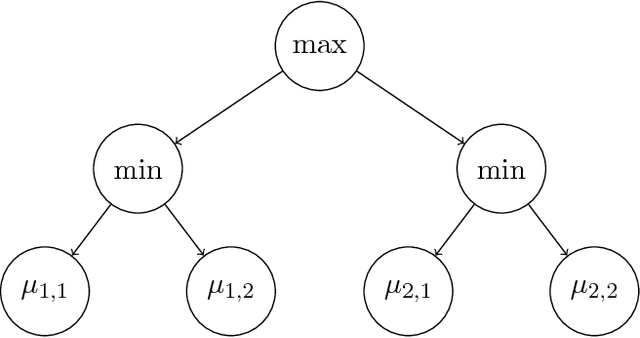
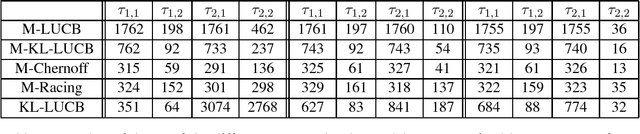
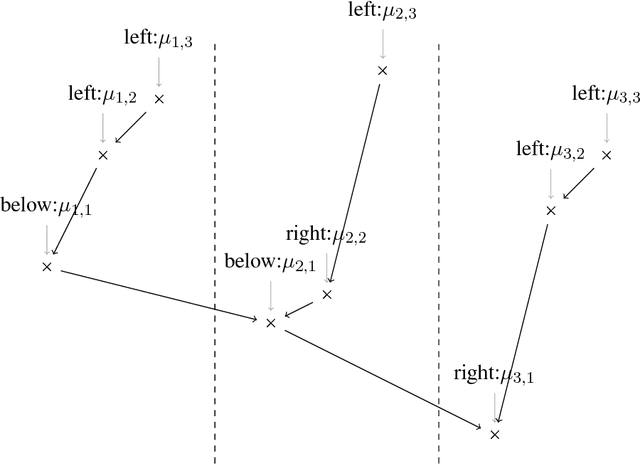
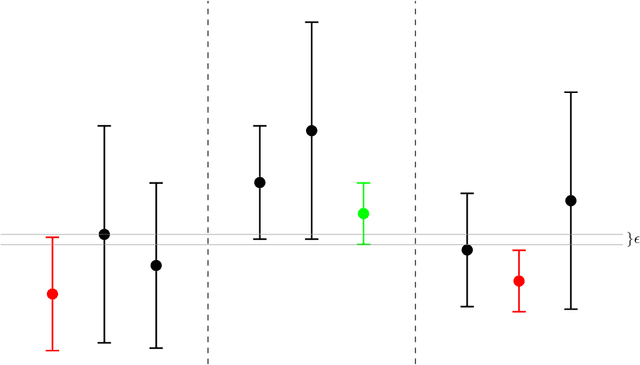
We study an original problem of pure exploration in a strategic bandit model motivated by Monte Carlo Tree Search. It consists in identifying the best action in a game, when the player may sample random outcomes of sequentially chosen pairs of actions. We propose two strategies for the fixed-confidence setting: Maximin-LUCB, based on lower-and upper-confidence bounds; and Maximin-Racing, which operates by successively eliminating the sub-optimal actions. We discuss the sample complexity of both methods and compare their performance empirically. We sketch a lower bound analysis, and possible connections to an optimal algorithm.
Combining Expert Advice Efficiently
Feb 15, 2008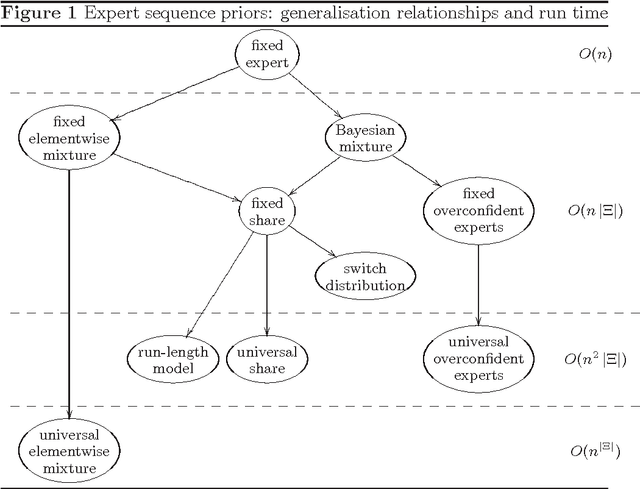
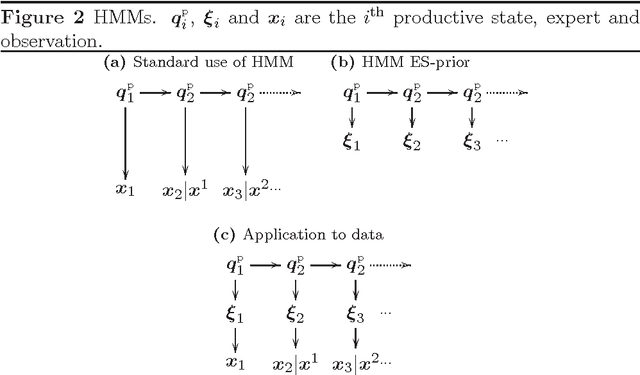
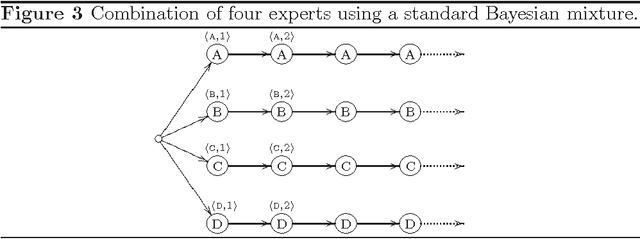
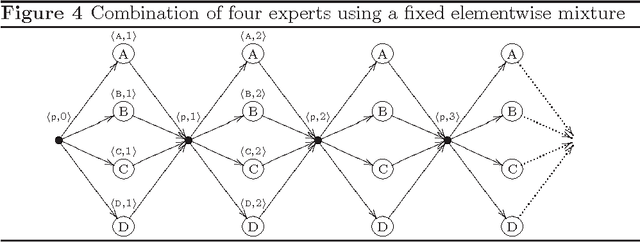
We show how models for prediction with expert advice can be defined concisely and clearly using hidden Markov models (HMMs); standard HMM algorithms can then be used to efficiently calculate, among other things, how the expert predictions should be weighted according to the model. We cast many existing models as HMMs and recover the best known running times in each case. We also describe two new models: the switch distribution, which was recently developed to improve Bayesian/Minimum Description Length model selection, and a new generalisation of the fixed share algorithm based on run-length coding. We give loss bounds for all models and shed new light on their relationships.