 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA tutorial on MDL hypothesis testing for graph analysis
Oct 31, 2018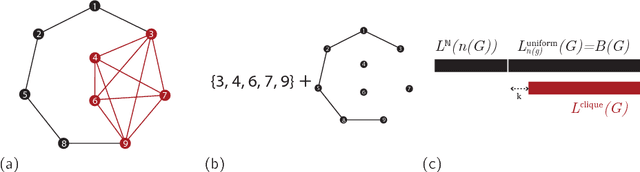
This document provides a tutorial description of the use of the MDL principle in complex graph analysis. We give a brief summary of the preliminary subjects, and describe the basic principle, using the example of analysing the size of the largest clique in a graph. We also provide a discussion of how to interpret the results of such an analysis, making note of several common pitfalls.
An Expectation-Maximization Algorithm for the Fractal Inverse Problem
Jun 30, 2017
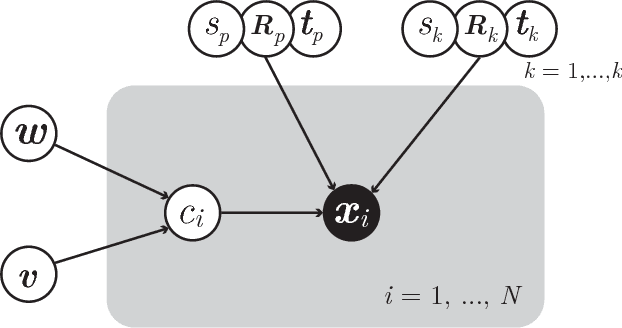

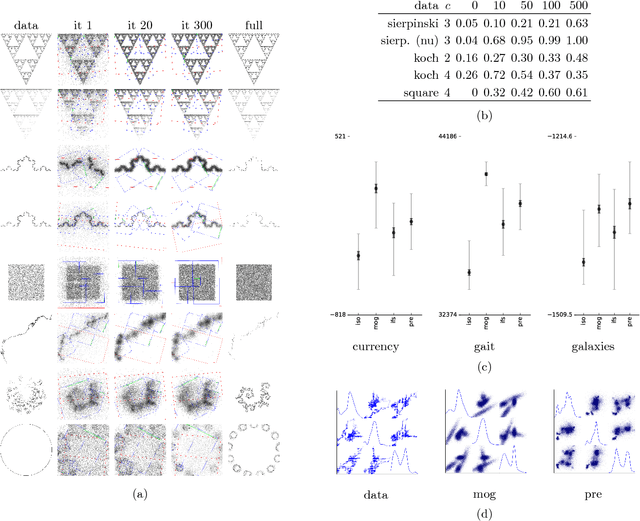
We present an Expectation-Maximization algorithm for the fractal inverse problem: the problem of fitting a fractal model to data. In our setting the fractals are Iterated Function Systems (IFS), with similitudes as the family of transformations. The data is a point cloud in ${\mathbb R}^H$ with arbitrary dimension $H$. Each IFS defines a probability distribution on ${\mathbb R}^H$, so that the fractal inverse problem can be cast as a problem of parameter estimation. We show that the algorithm reconstructs well-known fractals from data, with the model converging to high precision parameters. We also show the utility of the model as an approximation for datasources outside the IFS model class.
Finding Network Motifs in Large Graphs using Compression as a Measure of Relevance
Jun 09, 2017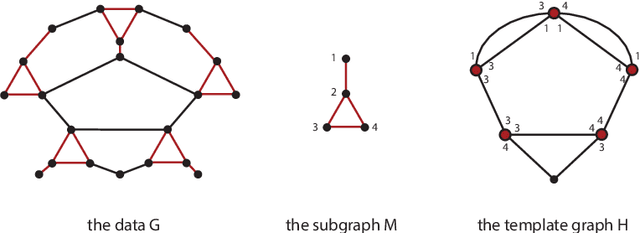
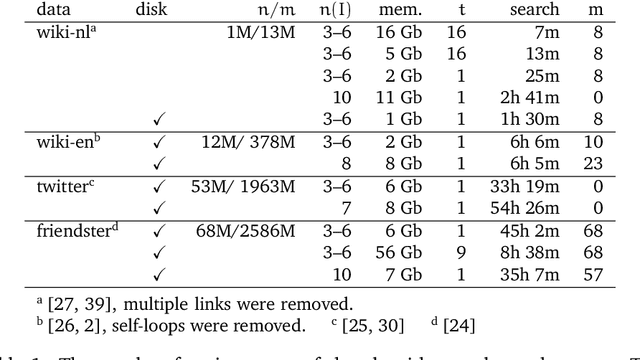
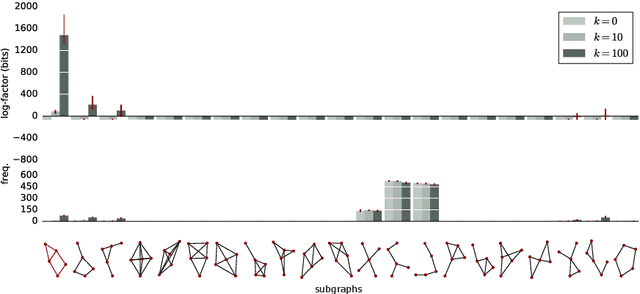
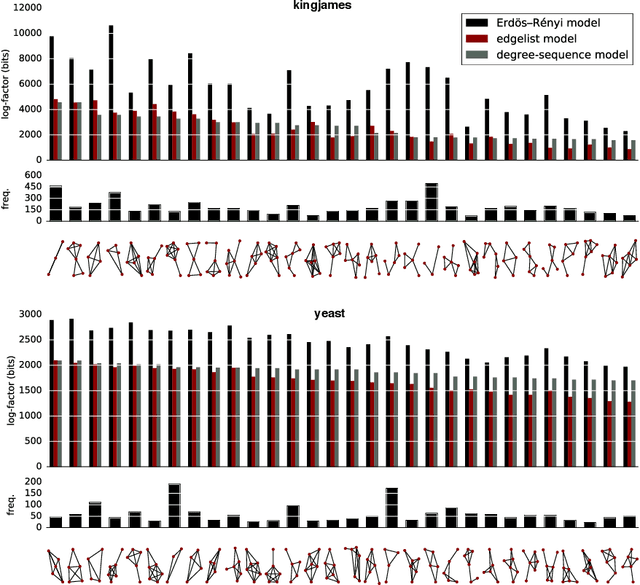
We introduce a new method for finding network motifs: interesting or informative subgraph patterns in a network. Current methods for finding motifs rely on the frequency of the motif: specifically, subgraphs are motifs when their frequency in the data is high compared to the expected frequency under a null model. To compute this expectation, the search for motifs is normally repeated on as many as 1000 random graphs sampled from the null model; a prohibitively expensive step. We use ideas from the Minimum Description Length (MDL) literature to define a new measure of motif relevance, and a new algorithm for detecting motifs. Our method allows motif analysis to scale to networks with billions of links, while still resulting in informative motifs.
Universal Codes from Switching Strategies
Nov 26, 2013
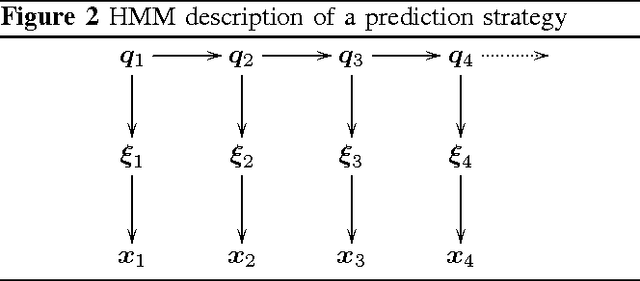
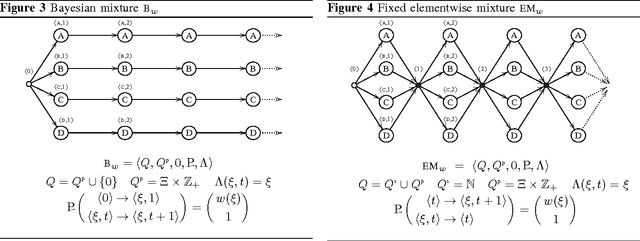
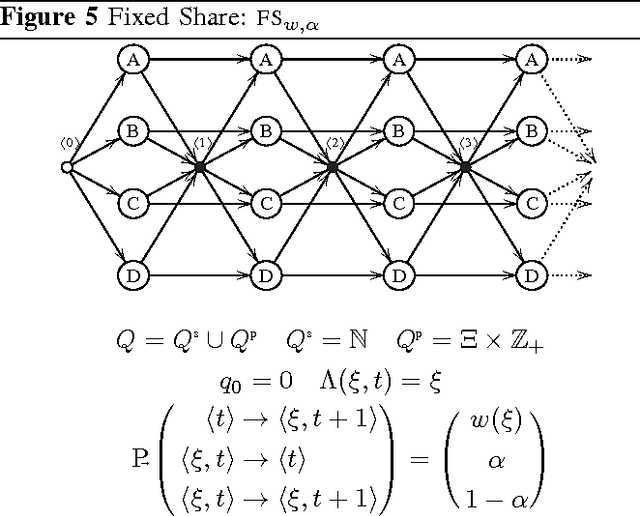
We discuss algorithms for combining sequential prediction strategies, a task which can be viewed as a natural generalisation of the concept of universal coding. We describe a graphical language based on Hidden Markov Models for defining prediction strategies, and we provide both existing and new models as examples. The models include efficient, parameterless models for switching between the input strategies over time, including a model for the case where switches tend to occur in clusters, and finally a new model for the scenario where the prediction strategies have a known relationship, and where jumps are typically between strongly related ones. This last model is relevant for coding time series data where parameter drift is expected. As theoretical ontributions we introduce an interpolation construction that is useful in the development and analysis of new algorithms, and we establish a new sophisticated lemma for analysing the individual sequence regret of parameterised models.
Follow the Leader If You Can, Hedge If You Must
Jan 17, 2013

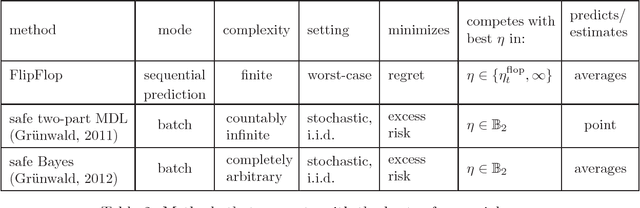
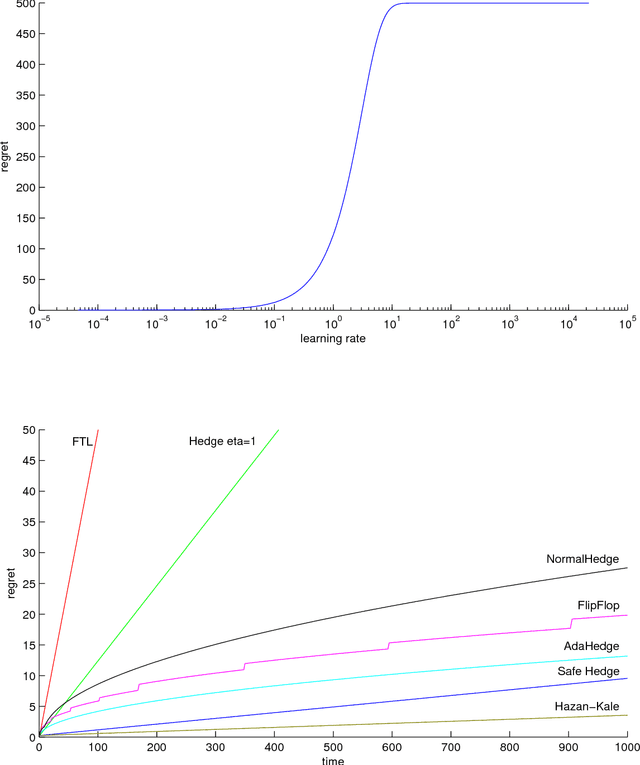
Follow-the-Leader (FTL) is an intuitive sequential prediction strategy that guarantees constant regret in the stochastic setting, but has terrible performance for worst-case data. Other hedging strategies have better worst-case guarantees but may perform much worse than FTL if the data are not maximally adversarial. We introduce the FlipFlop algorithm, which is the first method that provably combines the best of both worlds. As part of our construction, we develop AdaHedge, which is a new way of dynamically tuning the learning rate in Hedge without using the doubling trick. AdaHedge refines a method by Cesa-Bianchi, Mansour and Stoltz (2007), yielding slightly improved worst-case guarantees. By interleaving AdaHedge and FTL, the FlipFlop algorithm achieves regret within a constant factor of the FTL regret, without sacrificing AdaHedge's worst-case guarantees. AdaHedge and FlipFlop do not need to know the range of the losses in advance; moreover, unlike earlier methods, both have the intuitive property that the issued weights are invariant under rescaling and translation of the losses. The losses are also allowed to be negative, in which case they may be interpreted as gains.
* under submission
Adaptive Hedge
Oct 28, 2011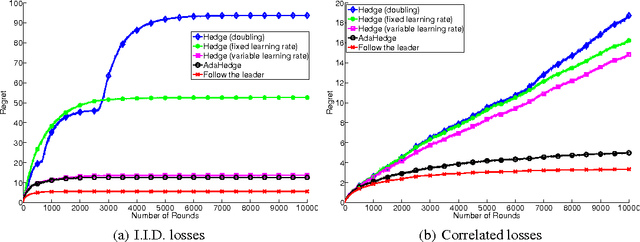
Most methods for decision-theoretic online learning are based on the Hedge algorithm, which takes a parameter called the learning rate. In most previous analyses the learning rate was carefully tuned to obtain optimal worst-case performance, leading to suboptimal performance on easy instances, for example when there exists an action that is significantly better than all others. We propose a new way of setting the learning rate, which adapts to the difficulty of the learning problem: in the worst case our procedure still guarantees optimal performance, but on easy instances it achieves much smaller regret. In particular, our adaptive method achieves constant regret in a probabilistic setting, when there exists an action that on average obtains strictly smaller loss than all other actions. We also provide a simulation study comparing our approach to existing methods.
* This is the full version of the paper with the same name that will appear in Advances in Neural Information Processing Systems 24 (NIPS 2011), 2012. The two papers are identical, except that this version contains an extra section of Additional Material
Catching Up Faster by Switching Sooner: A Prequential Solution to the AIC-BIC Dilemma
Jul 07, 2008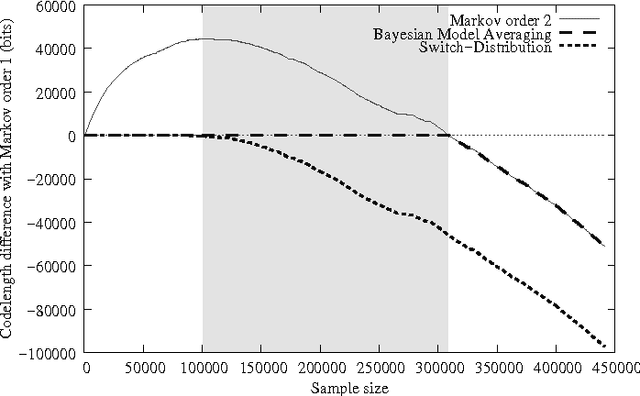
Bayesian model averaging, model selection and its approximations such as BIC are generally statistically consistent, but sometimes achieve slower rates og convergence than other methods such as AIC and leave-one-out cross-validation. On the other hand, these other methods can br inconsistent. We identify the "catch-up phenomenon" as a novel explanation for the slow convergence of Bayesian methods. Based on this analysis we define the switch distribution, a modification of the Bayesian marginal distribution. We show that, under broad conditions,model selection and prediction based on the switch distribution is both consistent and achieves optimal convergence rates, thereby resolving the AIC-BIC dilemma. The method is practical; we give an efficient implementation. The switch distribution has a data compression interpretation, and can thus be viewed as a "prequential" or MDL method; yet it is different from the MDL methods that are usually considered in the literature. We compare the switch distribution to Bayes factor model selection and leave-one-out cross-validation.
Combining Expert Advice Efficiently
Feb 15, 2008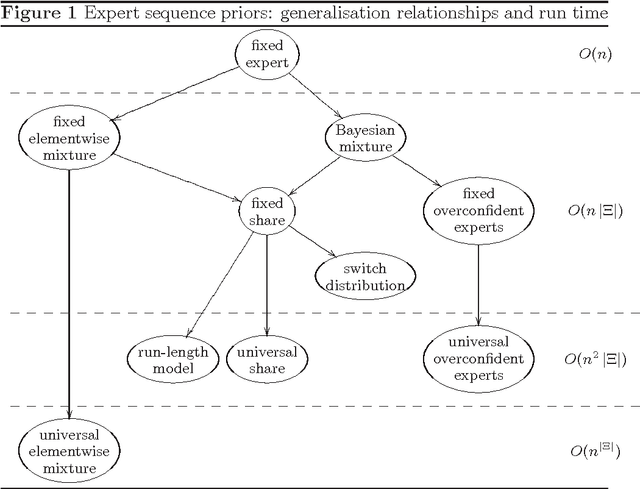
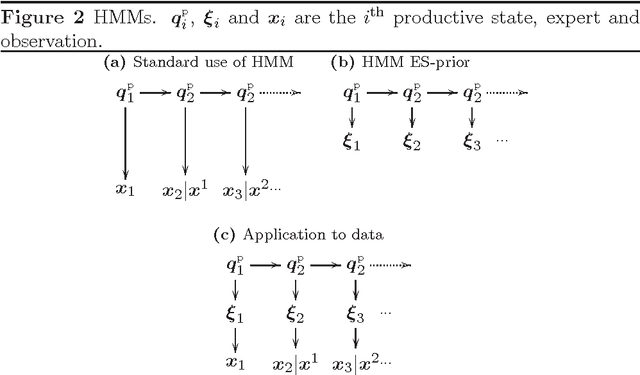
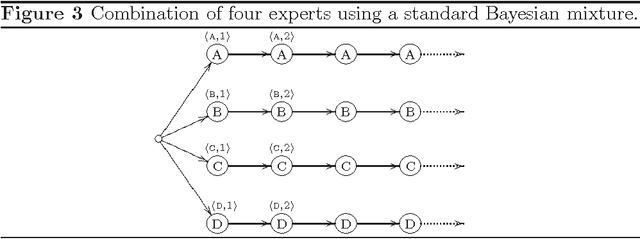
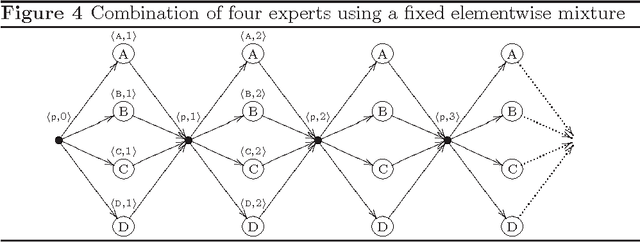
We show how models for prediction with expert advice can be defined concisely and clearly using hidden Markov models (HMMs); standard HMM algorithms can then be used to efficiently calculate, among other things, how the expert predictions should be weighted according to the model. We cast many existing models as HMMs and recover the best known running times in each case. We also describe two new models: the switch distribution, which was recently developed to improve Bayesian/Minimum Description Length model selection, and a new generalisation of the fixed share algorithm based on run-length coding. We give loss bounds for all models and shed new light on their relationships.
Asymptotic Log-loss of Prequential Maximum Likelihood Codes
Feb 01, 2005
We analyze the Dawid-Rissanen prequential maximum likelihood codes relative to one-parameter exponential family models M. If data are i.i.d. according to an (essentially) arbitrary P, then the redundancy grows at rate c/2 ln n. We show that c=v1/v2, where v1 is the variance of P, and v2 is the variance of the distribution m* in M that is closest to P in KL divergence. This shows that prequential codes behave quite differently from other important universal codes such as the 2-part MDL, Shtarkov and Bayes codes, for which c=1. This behavior is undesirable in an MDL model selection setting.
An Empirical Study of MDL Model Selection with Infinite Parametric Complexity
Jan 14, 2005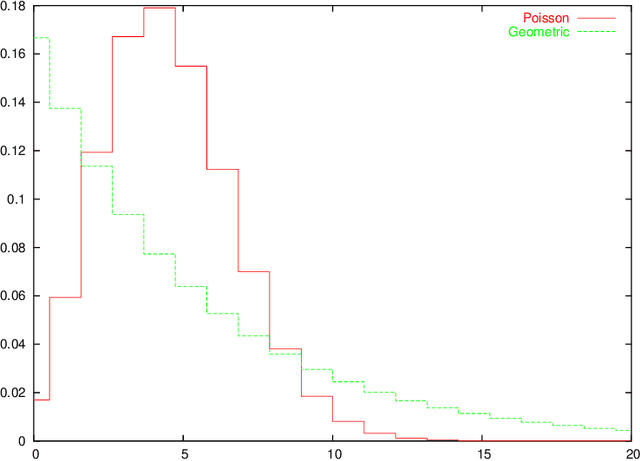
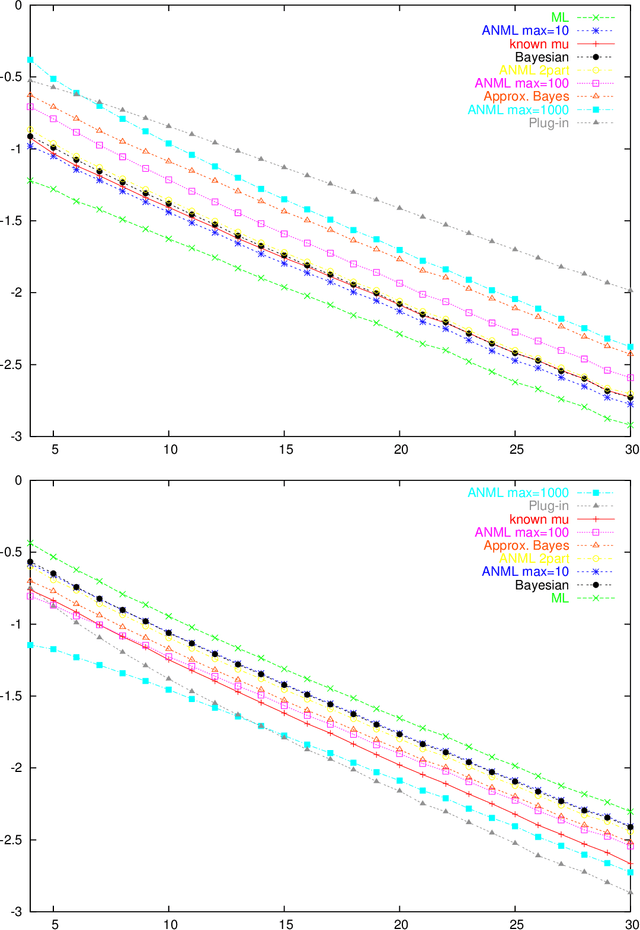
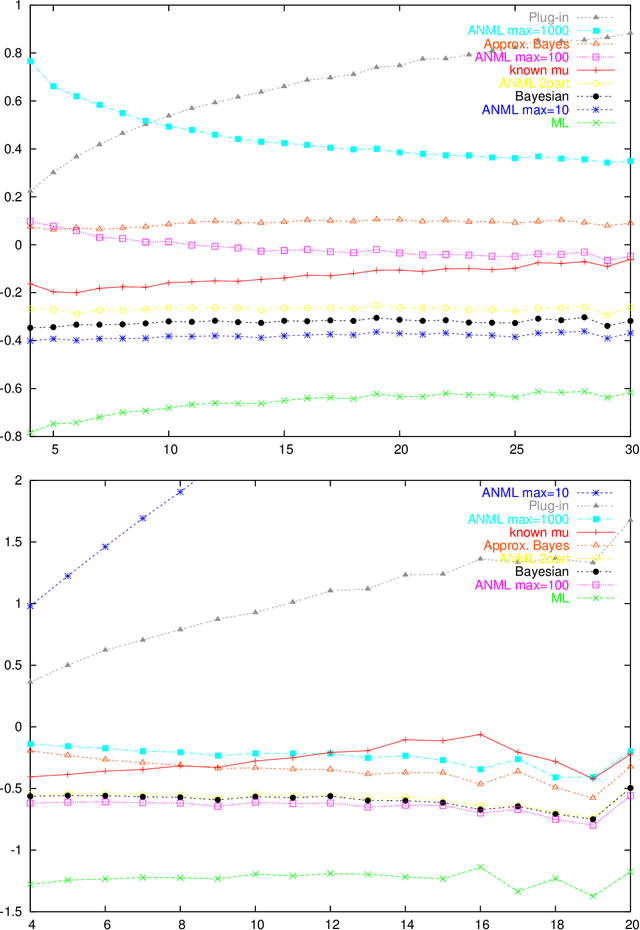
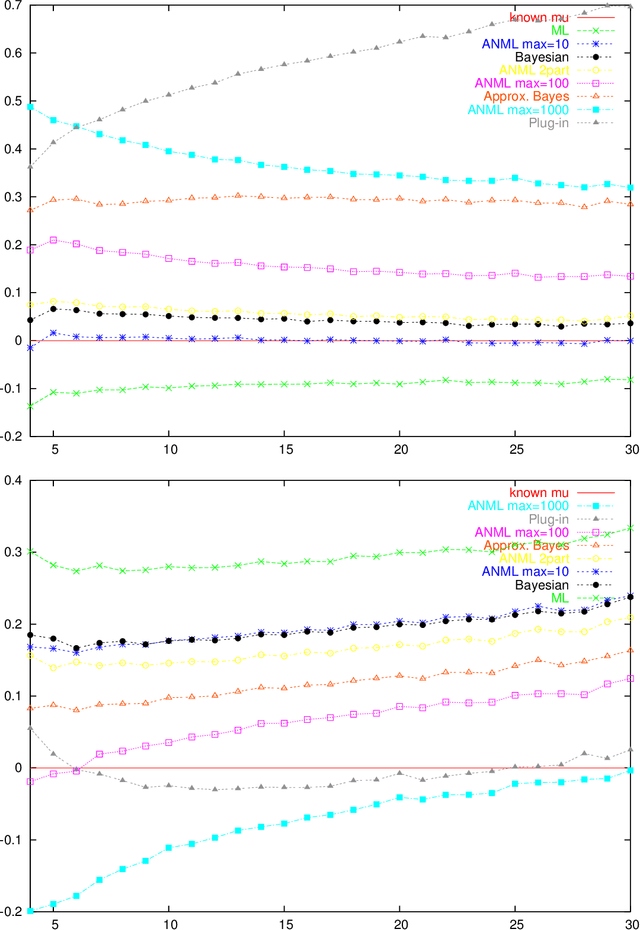
Parametric complexity is a central concept in MDL model selection. In practice it often turns out to be infinite, even for quite simple models such as the Poisson and Geometric families. In such cases, MDL model selection as based on NML and Bayesian inference based on Jeffreys' prior can not be used. Several ways to resolve this problem have been proposed. We conduct experiments to compare and evaluate their behaviour on small sample sizes. We find interestingly poor behaviour for the plug-in predictive code; a restricted NML model performs quite well but it is questionable if the results validate its theoretical motivation. The Bayesian model with the improper Jeffreys' prior is the most dependable.