 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHunyuan3D 2.0: Scaling Diffusion Models for High Resolution Textured 3D Assets Generation
Jan 21, 2025



We present Hunyuan3D 2.0, an advanced large-scale 3D synthesis system for generating high-resolution textured 3D assets. This system includes two foundation components: a large-scale shape generation model -- Hunyuan3D-DiT, and a large-scale texture synthesis model -- Hunyuan3D-Paint. The shape generative model, built on a scalable flow-based diffusion transformer, aims to create geometry that properly aligns with a given condition image, laying a solid foundation for downstream applications. The texture synthesis model, benefiting from strong geometric and diffusion priors, produces high-resolution and vibrant texture maps for either generated or hand-crafted meshes. Furthermore, we build Hunyuan3D-Studio -- a versatile, user-friendly production platform that simplifies the re-creation process of 3D assets. It allows both professional and amateur users to manipulate or even animate their meshes efficiently. We systematically evaluate our models, showing that Hunyuan3D 2.0 outperforms previous state-of-the-art models, including the open-source models and closed-source models in geometry details, condition alignment, texture quality, and etc. Hunyuan3D 2.0 is publicly released in order to fill the gaps in the open-source 3D community for large-scale foundation generative models. The code and pre-trained weights of our models are available at: https://github.com/Tencent/Hunyuan3D-2
Learn to See Faster: Pushing the Limits of High-Speed Camera with Deep Underexposed Image Denoising
Nov 29, 2022
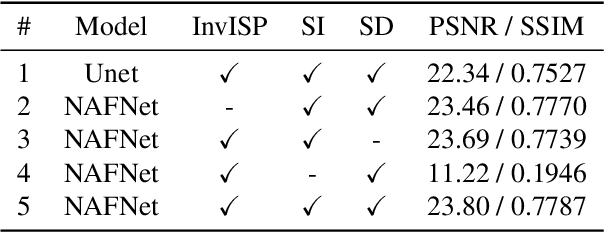
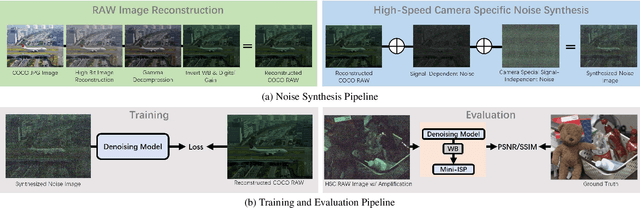
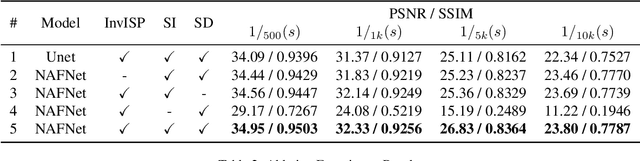
The ability to record high-fidelity videos at high acquisition rates is central to the study of fast moving phenomena. The difficulty of imaging fast moving scenes lies in a trade-off between motion blur and underexposure noise: On the one hand, recordings with long exposure times suffer from motion blur effects caused by movements in the recorded scene. On the other hand, the amount of light reaching camera photosensors decreases with exposure times so that short-exposure recordings suffer from underexposure noise. In this paper, we propose to address this trade-off by treating the problem of high-speed imaging as an underexposed image denoising problem. We combine recent advances on underexposed image denoising using deep learning and adapt these methods to the specificity of the high-speed imaging problem. Leveraging large external datasets with a sensor-specific noise model, our method is able to speedup the acquisition rate of a High-Speed Camera over one order of magnitude while maintaining similar image quality.
Optical Flow Regularization of Implicit Neural Representations for Video Frame Interpolation
Jun 22, 2022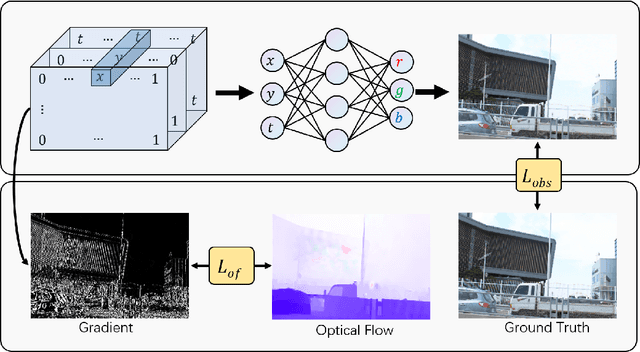
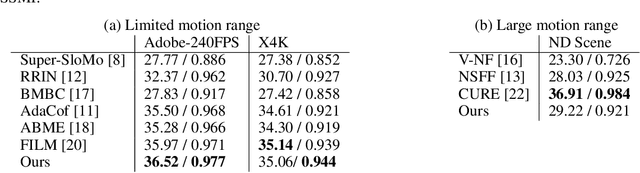
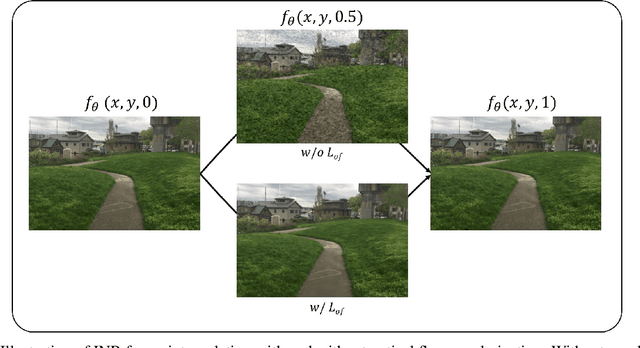
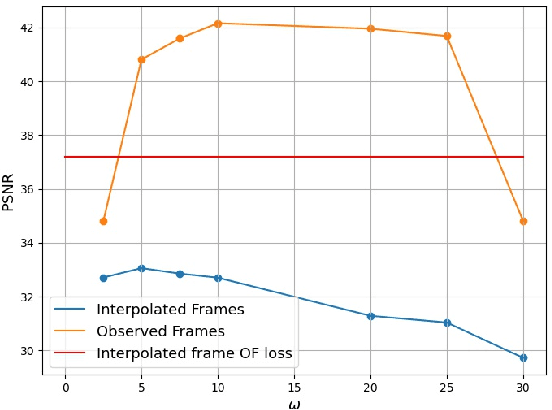
Recent works have shown the ability of Implicit Neural Representations (INR) to carry meaningful representations of signal derivatives. In this work, we leverage this property to perform Video Frame Interpolation (VFI) by explicitly constraining the derivatives of the INR to satisfy the optical flow constraint equation. We achieve state of the art VFI on limited motion ranges using only a target video and its optical flow, without learning the interpolation operator from additional training data. We further show that constraining the INR derivatives not only allows to better interpolate intermediate frames but also improves the ability of narrow networks to fit the observed frames, which suggests potential applications to video compression and INR optimization.