 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-shot Sound Event Classification Using a Sound Attribute Vector with Global and Local Feature Learning
Mar 18, 2023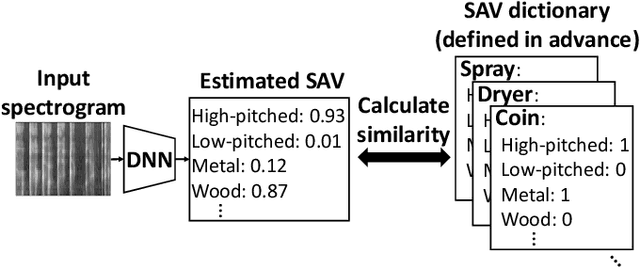
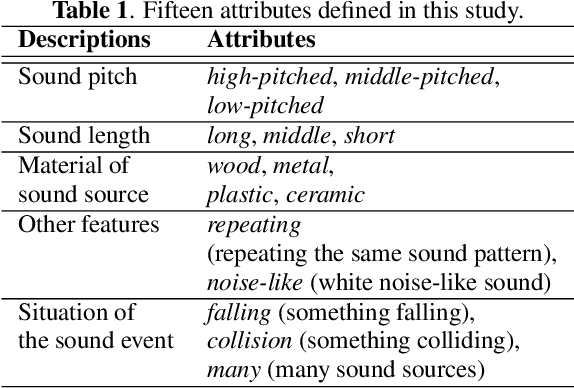
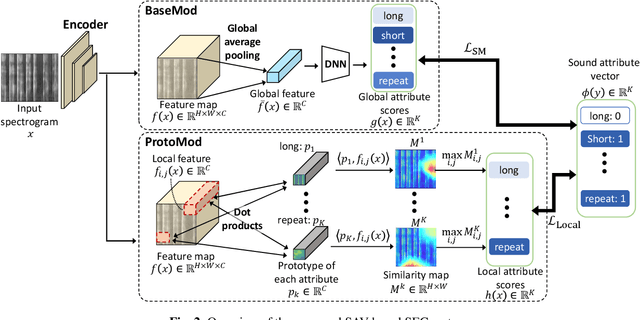
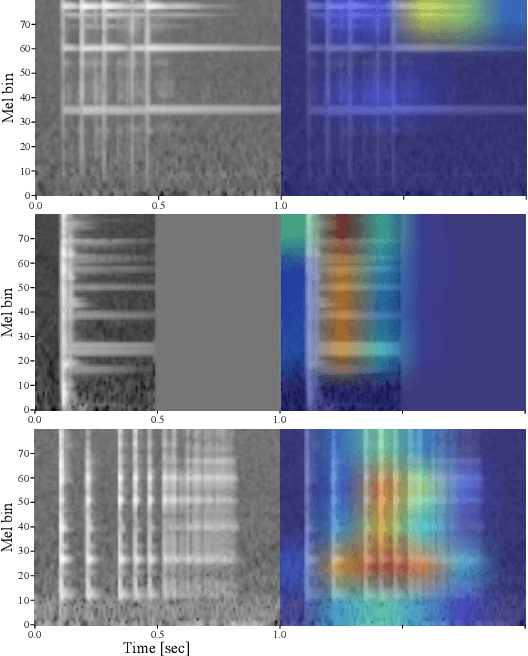
This paper introduces a zero-shot sound event classification (ZS-SEC) method to identify sound events that have never occurred in training data. In our previous work, we proposed a ZS-SEC method using sound attribute vectors (SAVs), where a deep neural network model infers attribute information that describes the sound of an event class instead of inferring its class label directly. Our previous method showed that it could classify unseen events to some extent; however, the accuracy for unseen events was far inferior to that for seen events. In this paper, we propose a new ZS-SEC method that can learn discriminative global features and local features simultaneously to enhance SAV-based ZS-SEC. In the proposed method, while the global features are learned in order to discriminate the event classes in the training data, the spectro-temporal local features are learned in order to regress the attribute information using attribute prototypes. The experimental results show that our proposed method can improve the accuracy of SAV-based ZS-SEC and can visualize the region in the spectrogram related to each attribute.
Learn to See Faster: Pushing the Limits of High-Speed Camera with Deep Underexposed Image Denoising
Nov 29, 2022
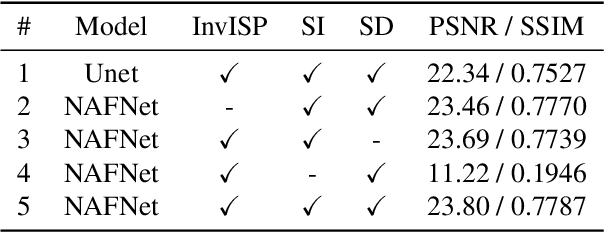
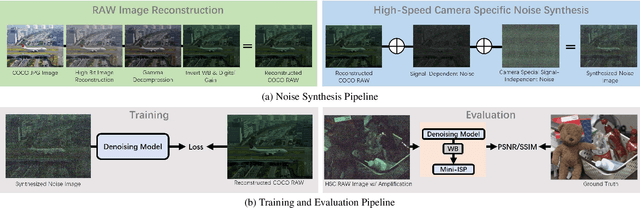
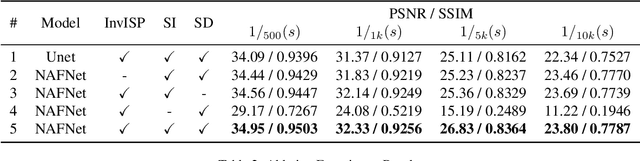
The ability to record high-fidelity videos at high acquisition rates is central to the study of fast moving phenomena. The difficulty of imaging fast moving scenes lies in a trade-off between motion blur and underexposure noise: On the one hand, recordings with long exposure times suffer from motion blur effects caused by movements in the recorded scene. On the other hand, the amount of light reaching camera photosensors decreases with exposure times so that short-exposure recordings suffer from underexposure noise. In this paper, we propose to address this trade-off by treating the problem of high-speed imaging as an underexposed image denoising problem. We combine recent advances on underexposed image denoising using deep learning and adapt these methods to the specificity of the high-speed imaging problem. Leveraging large external datasets with a sensor-specific noise model, our method is able to speedup the acquisition rate of a High-Speed Camera over one order of magnitude while maintaining similar image quality.
Optical Flow Regularization of Implicit Neural Representations for Video Frame Interpolation
Jun 22, 2022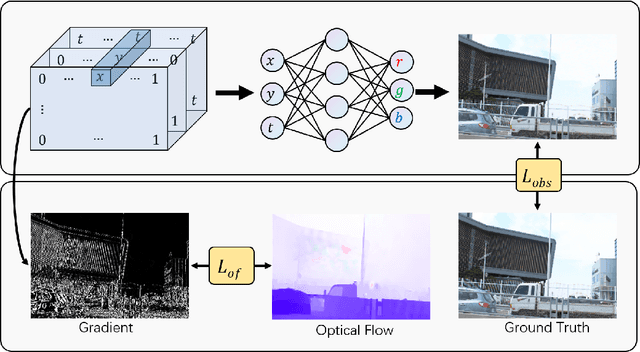
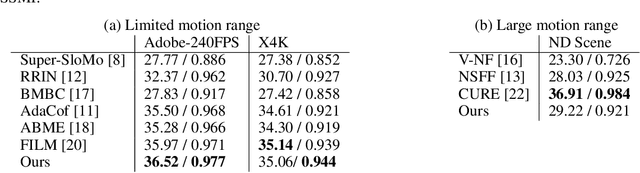
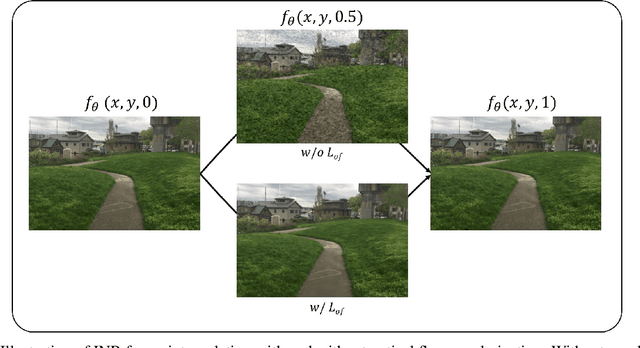
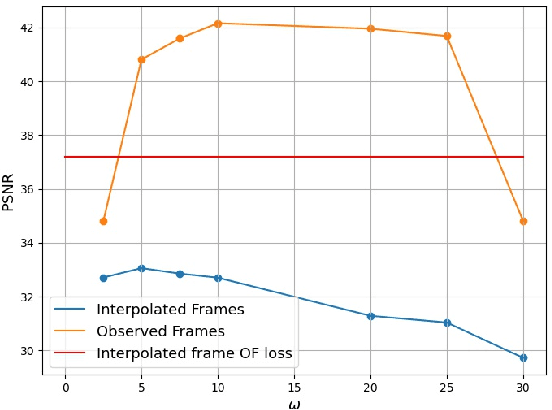
Recent works have shown the ability of Implicit Neural Representations (INR) to carry meaningful representations of signal derivatives. In this work, we leverage this property to perform Video Frame Interpolation (VFI) by explicitly constraining the derivatives of the INR to satisfy the optical flow constraint equation. We achieve state of the art VFI on limited motion ranges using only a target video and its optical flow, without learning the interpolation operator from additional training data. We further show that constraining the INR derivatives not only allows to better interpolate intermediate frames but also improves the ability of narrow networks to fit the observed frames, which suggests potential applications to video compression and INR optimization.
Current Source Localization Using Deep Prior with Depth Weighting
Mar 26, 2022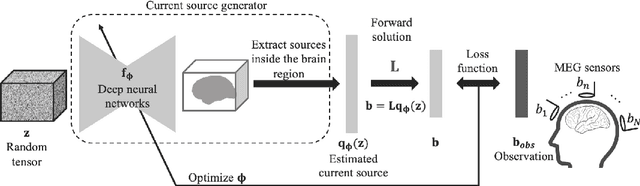
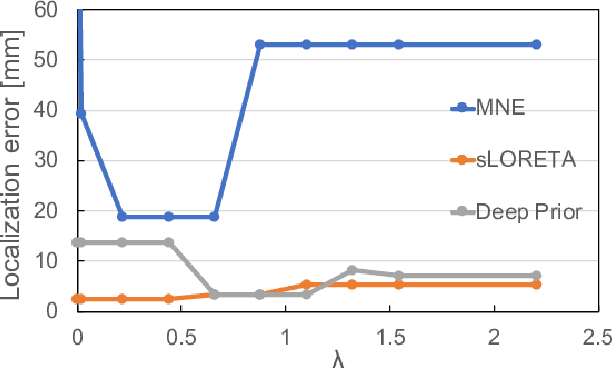
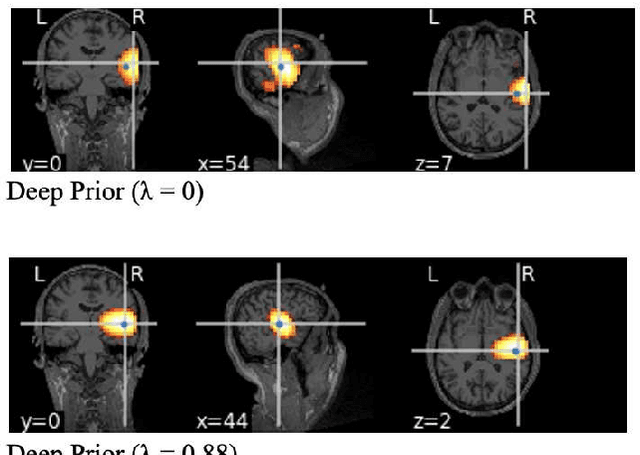
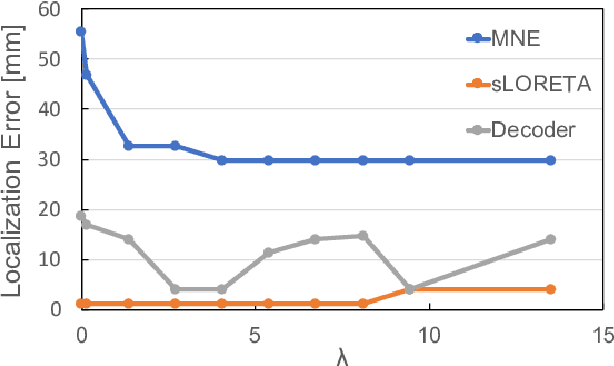
This paper proposes a novel neuronal current source localization method based on Deep Prior that represents a more complicated prior distribution of current source using convolutional networks. Deep Prior has been suggested as a means of an unsupervised learning approach that does not require learning using training data, and randomly-initialized neural networks are used to update a source location using a single observation. In our previous work, a Deep-Prior-based current source localization method in the brain has been proposed but the performance was not almost the same as those of conventional approaches, such as sLORETA. In order to improve the Deep-Prior-based approach, in this paper, a depth weight of the current source is introduced for Deep Prior, where depth weighting amounts to assigning more penalty to the superficial currents. Its effectiveness is confirmed by experiments of current source estimation on simulated MEG data.
FasterRCNN Monitoring of Road Damages: Competition and Deployment
Oct 22, 2020
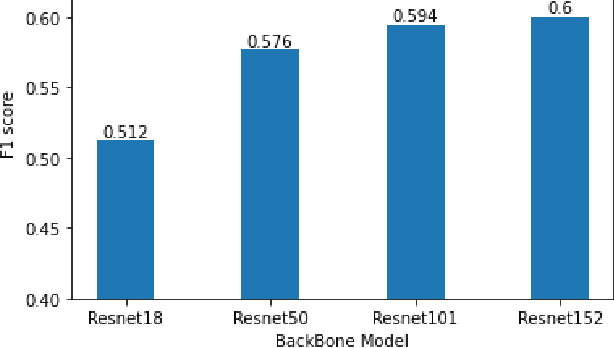
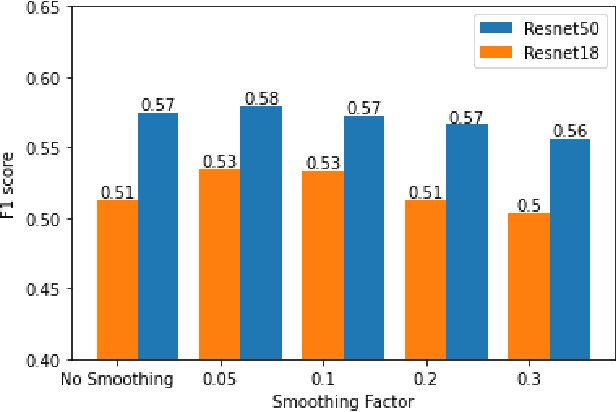
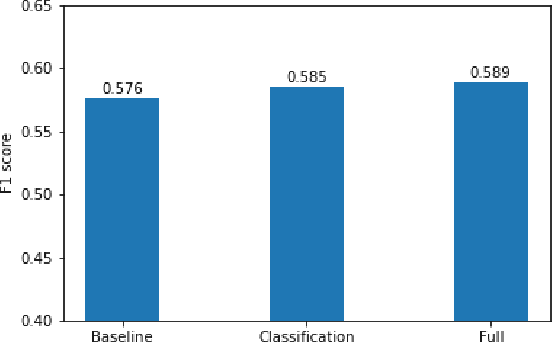
Maintaining aging infrastructure is a challenge currently faced by local and national administrators all around the world. An important prerequisite for efficient infrastructure maintenance is to continuously monitor (i.e., quantify the level of safety and reliability) the state of very large structures. Meanwhile, computer vision has made impressive strides in recent years, mainly due to successful applications of deep learning models. These novel progresses are allowing the automation of vision tasks, which were previously impossible to automate, offering promising possibilities to assist administrators in optimizing their infrastructure maintenance operations. In this context, the IEEE 2020 global Road Damage Detection (RDD) Challenge is giving an opportunity for deep learning and computer vision researchers to get involved and help accurately track pavement damages on road networks. This paper proposes two contributions to that topic: In a first part, we detail our solution to the RDD Challenge. In a second part, we present our efforts in deploying our model on a local road network, explaining the proposed methodology and encountered challenges.
Auxiliary Interference Speaker Loss for Target-Speaker Speech Recognition
Jun 26, 2019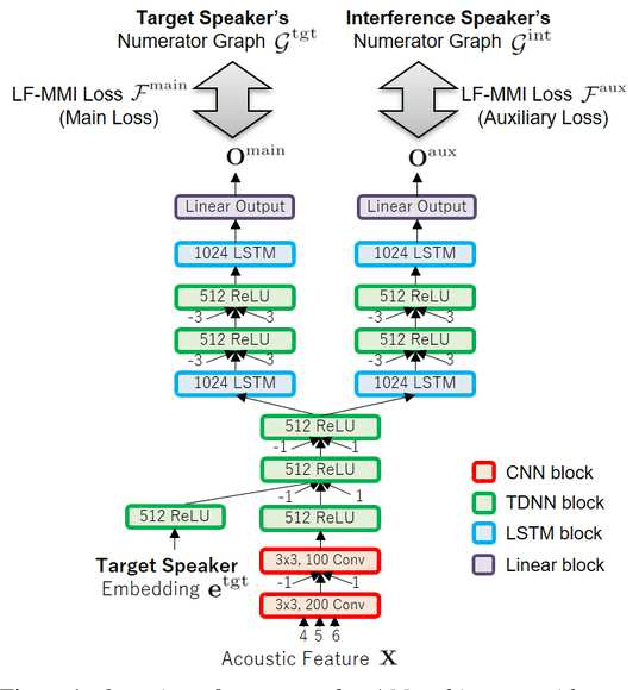

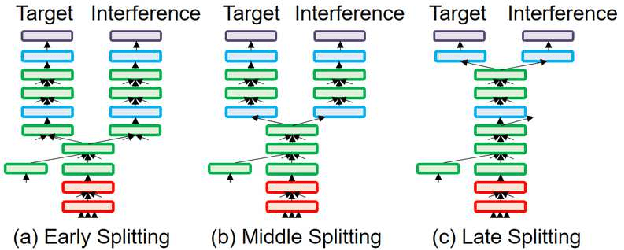

In this paper, we propose a novel auxiliary loss function for target-speaker automatic speech recognition (ASR). Our method automatically extracts and transcribes target speaker's utterances from a monaural mixture of multiple speakers speech given a short sample of the target speaker. The proposed auxiliary loss function attempts to additionally maximize interference speaker ASR accuracy during training. This will regularize the network to achieve a better representation for speaker separation, thus achieving better accuracy on the target-speaker ASR. We evaluated our proposed method using two-speaker-mixed speech in various signal-to-interference-ratio conditions. We first built a strong target-speaker ASR baseline based on the state-of-the-art lattice-free maximum mutual information. This baseline achieved a word error rate (WER) of 18.06% on the test set while a normal ASR trained with clean data produced a completely corrupted result (WER of 84.71%). Then, our proposed loss further reduced the WER by 6.6% relative to this strong baseline, achieving a WER of 16.87%. In addition to the accuracy improvement, we also showed that the auxiliary output branch for the proposed loss can even be used for a secondary ASR for interference speakers' speech.