 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFasterRCNN Monitoring of Road Damages: Competition and Deployment
Oct 22, 2020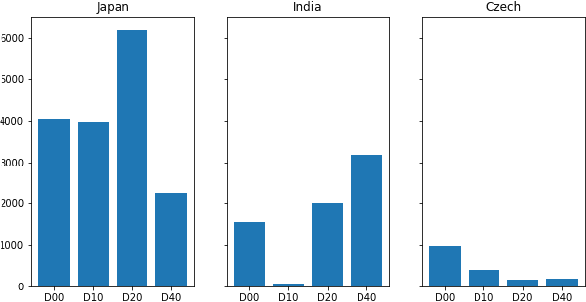
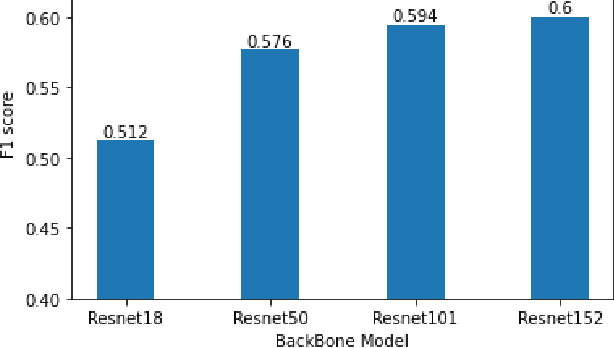
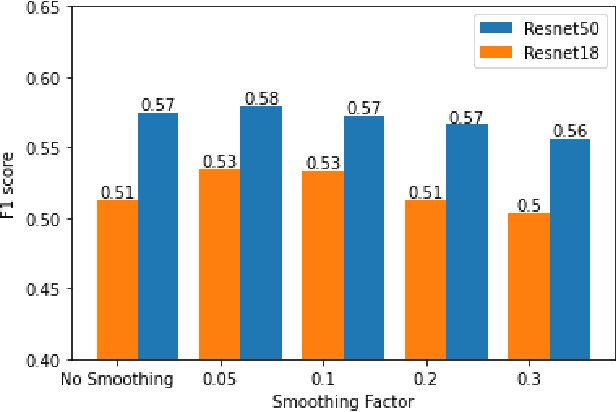
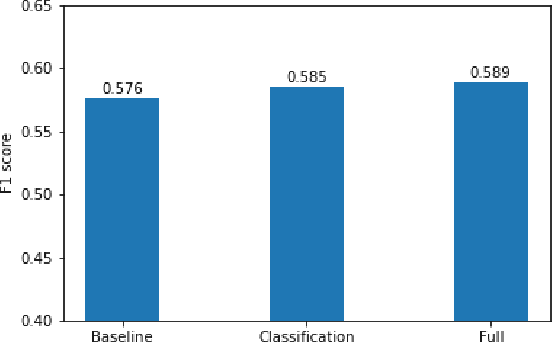
Maintaining aging infrastructure is a challenge currently faced by local and national administrators all around the world. An important prerequisite for efficient infrastructure maintenance is to continuously monitor (i.e., quantify the level of safety and reliability) the state of very large structures. Meanwhile, computer vision has made impressive strides in recent years, mainly due to successful applications of deep learning models. These novel progresses are allowing the automation of vision tasks, which were previously impossible to automate, offering promising possibilities to assist administrators in optimizing their infrastructure maintenance operations. In this context, the IEEE 2020 global Road Damage Detection (RDD) Challenge is giving an opportunity for deep learning and computer vision researchers to get involved and help accurately track pavement damages on road networks. This paper proposes two contributions to that topic: In a first part, we detail our solution to the RDD Challenge. In a second part, we present our efforts in deploying our model on a local road network, explaining the proposed methodology and encountered challenges.
Reversible designs for extreme memory cost reduction of CNN training
Oct 24, 2019
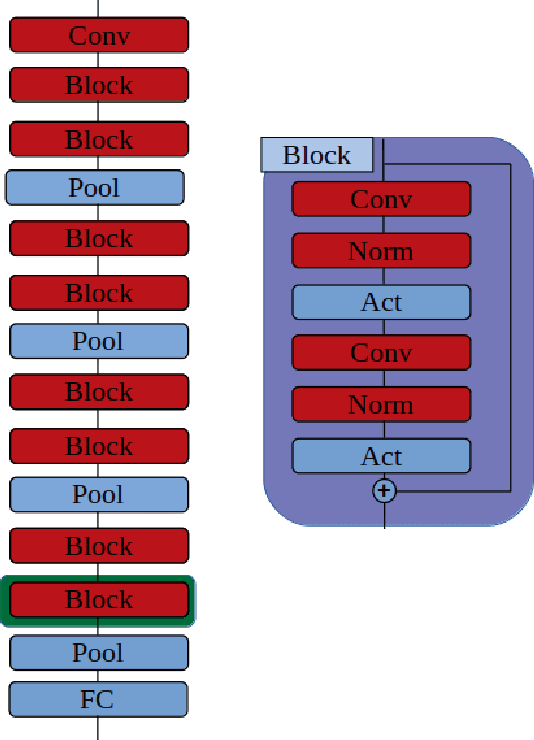

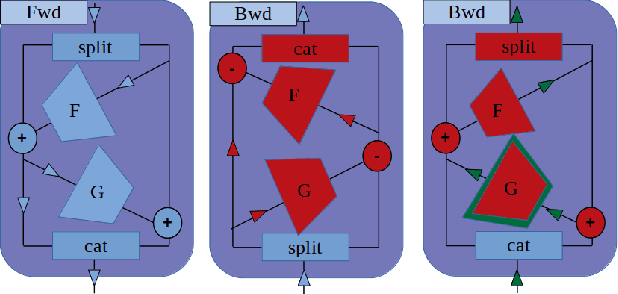
Training Convolutional Neural Networks (CNN) is a resource intensive task that requires specialized hardware for efficient computation. One of the most limiting bottleneck of CNN training is the memory cost associated with storing the activation values of hidden layers needed for the computation of the weights gradient during the backward pass of the backpropagation algorithm. Recently, reversible architectures have been proposed to reduce the memory cost of training large CNN by reconstructing the input activation values of hidden layers from their output during the backward pass, circumventing the need to accumulate these activations in memory during the forward pass. In this paper, we push this idea to the extreme and analyze reversible network designs yielding minimal training memory footprint. We investigate the propagation of numerical errors in long chains of invertible operations and analyze their effect on training. We introduce the notion of pixel-wise memory cost to characterize the memory footprint of model training, and propose a new model architecture able to efficiently train arbitrarily deep neural networks with a minimum memory cost of 352 bytes per input pixel. This new kind of architecture enables training large neural networks on very limited memory, opening the door for neural network training on embedded devices or non-specialized hardware. For instance, we demonstrate training of our model to 93.3% accuracy on the CIFAR10 dataset within 67 minutes on a low-end Nvidia GTX750 GPU with only 1GB of memory.
Assisting human experts in the interpretation of their visual process: A case study on assessing copper surface adhesive potency
Oct 24, 2019



Deep Neural Networks are often though to lack interpretability due to the distributed nature of their internal representations. In contrast, humans can generally justify, in natural language, for their answer to a visual question with simple common sense reasoning. However, human introspection abilities have their own limits as one often struggles to justify for the recognition process behind our lowest level feature recognition ability: for instance, it is difficult to precisely explain why a given texture seems more characteristic of the surface of a finger nail rather than a plastic bottle. In this paper, we showcase an application in which deep learning models can actually help human experts justify for their own low-level visual recognition process: We study the problem of assessing the adhesive potency of copper sheets from microscopic pictures of their surface. Although highly trained material experts are able to qualitatively assess the surface adhesive potency, they are often unable to precisely justify for their decision process. We present a model that, under careful design considerations, is able to provide visual clues for human experts to understand and justify for their own recognition process. Not only can our model assist human experts in their interpretation of the surface characteristics, we show how this model can be used to test different hypothesis of the copper surface response to different manufacturing processes.
On zero-shot recognition of generic objects
Apr 10, 2019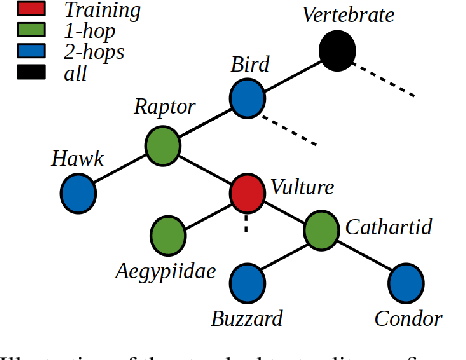
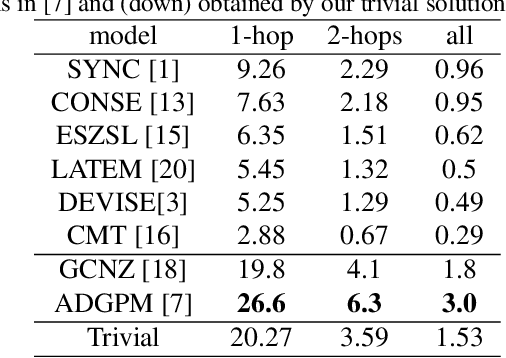
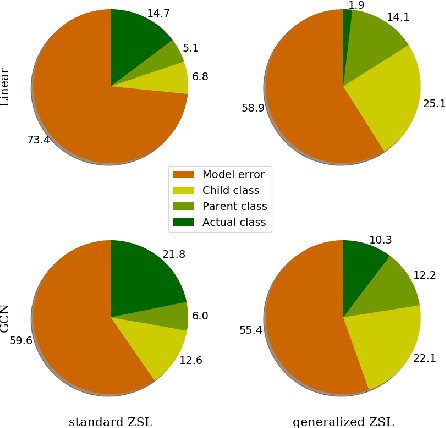
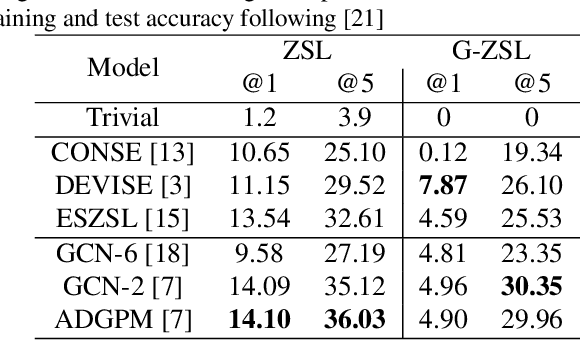
Many recent advances in computer vision are the result of a healthy competition among researchers on high quality, task-specific, benchmarks. After a decade of active research, zero-shot learning (ZSL) models accuracy on the Imagenet benchmark remains far too low to be considered for practical object recognition applications. In this paper, we argue that the main reason behind this apparent lack of progress is the poor quality of this benchmark. We highlight major structural flaws of the current benchmark and analyze different factors impacting the accuracy of ZSL models. We show that the actual classification accuracy of existing ZSL models is significantly higher than was previously thought as we account for these flaws. We then introduce the notion of structural bias specific to ZSL datasets. We discuss how the presence of this new form of bias allows for a trivial solution to the standard benchmark and conclude on the need for a new benchmark. We then detail the semi-automated construction of a new benchmark to address these flaws.