 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn zero-shot recognition of generic objects
Paper and Code
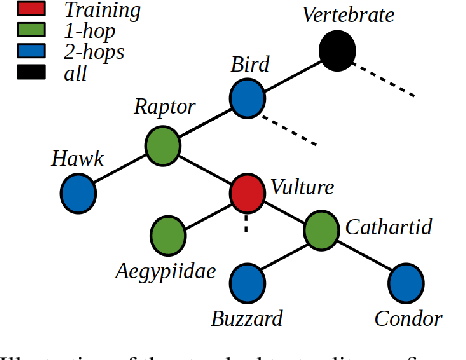
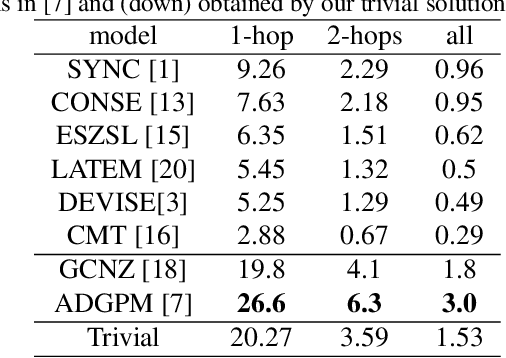
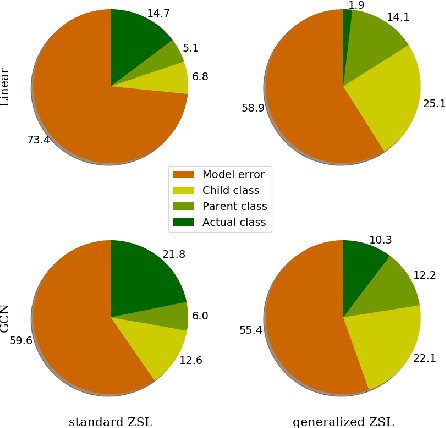
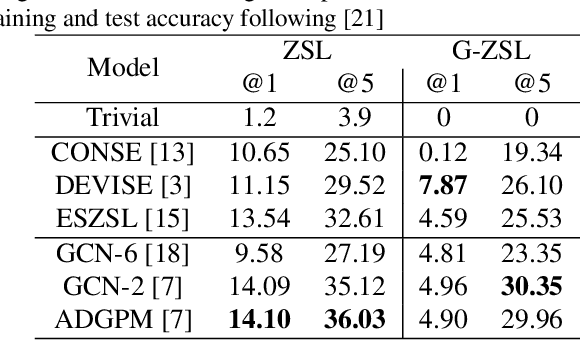
Many recent advances in computer vision are the result of a healthy competition among researchers on high quality, task-specific, benchmarks. After a decade of active research, zero-shot learning (ZSL) models accuracy on the Imagenet benchmark remains far too low to be considered for practical object recognition applications. In this paper, we argue that the main reason behind this apparent lack of progress is the poor quality of this benchmark. We highlight major structural flaws of the current benchmark and analyze different factors impacting the accuracy of ZSL models. We show that the actual classification accuracy of existing ZSL models is significantly higher than was previously thought as we account for these flaws. We then introduce the notion of structural bias specific to ZSL datasets. We discuss how the presence of this new form of bias allows for a trivial solution to the standard benchmark and conclude on the need for a new benchmark. We then detail the semi-automated construction of a new benchmark to address these flaws.