 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-shot Sound Event Classification Using a Sound Attribute Vector with Global and Local Feature Learning
Mar 18, 2023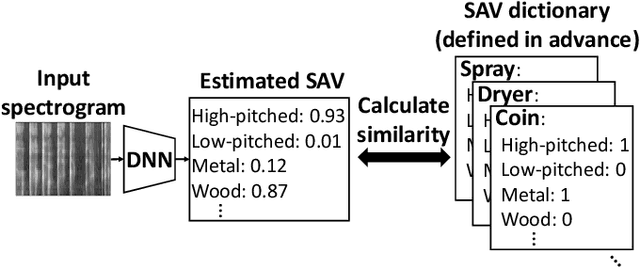
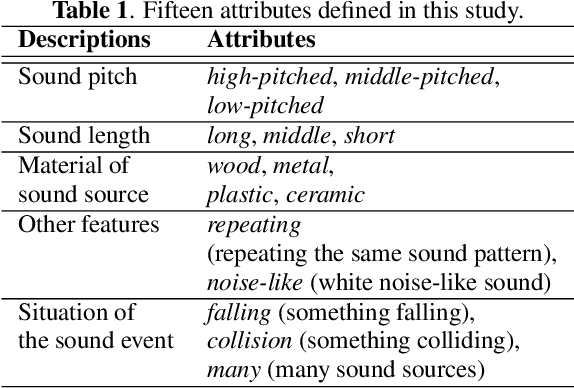
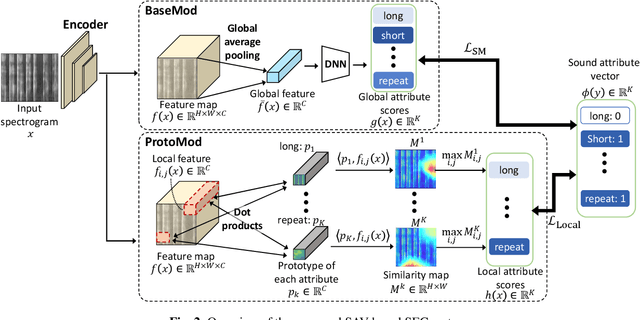
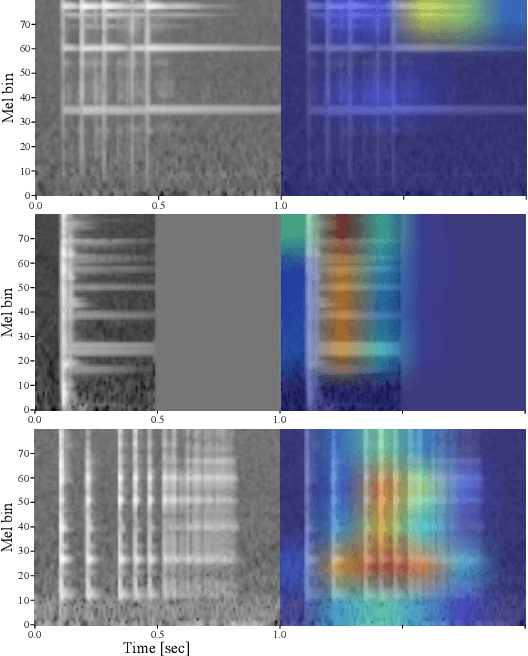
This paper introduces a zero-shot sound event classification (ZS-SEC) method to identify sound events that have never occurred in training data. In our previous work, we proposed a ZS-SEC method using sound attribute vectors (SAVs), where a deep neural network model infers attribute information that describes the sound of an event class instead of inferring its class label directly. Our previous method showed that it could classify unseen events to some extent; however, the accuracy for unseen events was far inferior to that for seen events. In this paper, we propose a new ZS-SEC method that can learn discriminative global features and local features simultaneously to enhance SAV-based ZS-SEC. In the proposed method, while the global features are learned in order to discriminate the event classes in the training data, the spectro-temporal local features are learned in order to regress the attribute information using attribute prototypes. The experimental results show that our proposed method can improve the accuracy of SAV-based ZS-SEC and can visualize the region in the spectrogram related to each attribute.