 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandomized Classifiers vs Human Decision-Makers: Trustworthy AI May Have to Act Randomly and Society Seems to Accept This
Nov 15, 2021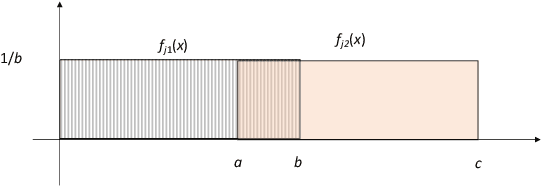
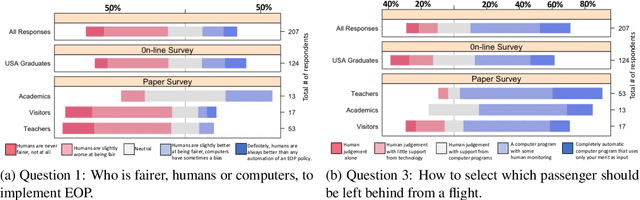

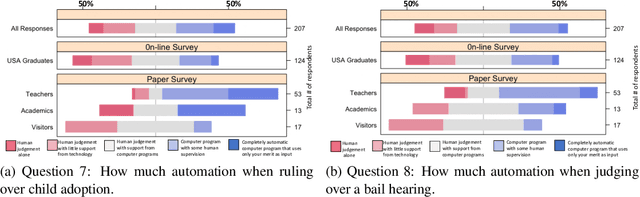
As \emph{artificial intelligence} (AI) systems are increasingly involved in decisions affecting our lives, ensuring that automated decision-making is fair and ethical has become a top priority. Intuitively, we feel that akin to human decisions, judgments of artificial agents should necessarily be grounded in some moral principles. Yet a decision-maker (whether human or artificial) can only make truly ethical (based on any ethical theory) and fair (according to any notion of fairness) decisions if full information on all the relevant factors on which the decision is based are available at the time of decision-making. This raises two problems: (1) In settings, where we rely on AI systems that are using classifiers obtained with supervised learning, some induction/generalization is present and some relevant attributes may not be present even during learning. (2) Modeling such decisions as games reveals that any -- however ethical -- pure strategy is inevitably susceptible to exploitation. Moreover, in many games, a Nash Equilibrium can only be obtained by using mixed strategies, i.e., to achieve mathematically optimal outcomes, decisions must be randomized. In this paper, we argue that in supervised learning settings, there exist random classifiers that perform at least as well as deterministic classifiers, and may hence be the optimal choice in many circumstances. We support our theoretical results with an empirical study indicating a positive societal attitude towards randomized artificial decision-makers, and discuss some policy and implementation issues related to the use of random classifiers that relate to and are relevant for current AI policy and standardization initiatives.
Tree Index: A New Cluster Evaluation Technique
Mar 24, 2020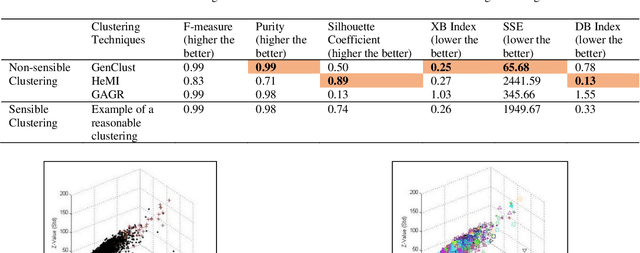


We introduce a cluster evaluation technique called Tree Index. Our Tree Index algorithm aims at describing the structural information of the clustering rather than the quantitative format of cluster-quality indexes (where the representation power of clustering is some cumulative error similar to vector quantization). Our Tree Index is finding margins amongst clusters for easy learning without the complications of Minimum Description Length. Our Tree Index produces a decision tree from the clustered data set, using the cluster identifiers as labels. It combines the entropy of each leaf with their depth. Intuitively, a shorter tree with pure leaves generalizes the data well (the clusters are easy to learn because they are well separated). So, the labels are meaningful clusters. If the clustering algorithm does not separate well, trees learned from their results will be large and too detailed. We show that, on the clustering results (obtained by various techniques) on a brain dataset, Tree Index discriminates between reasonable and non-sensible clusters. We confirm the effectiveness of Tree Index through graphical visualizations. Tree Index evaluates the sensible solutions higher than the non-sensible solutions while existing cluster-quality indexes fail to do so.
ROBO: Robust, Fully Neural Object Detection for Robot Soccer
Oct 24, 2019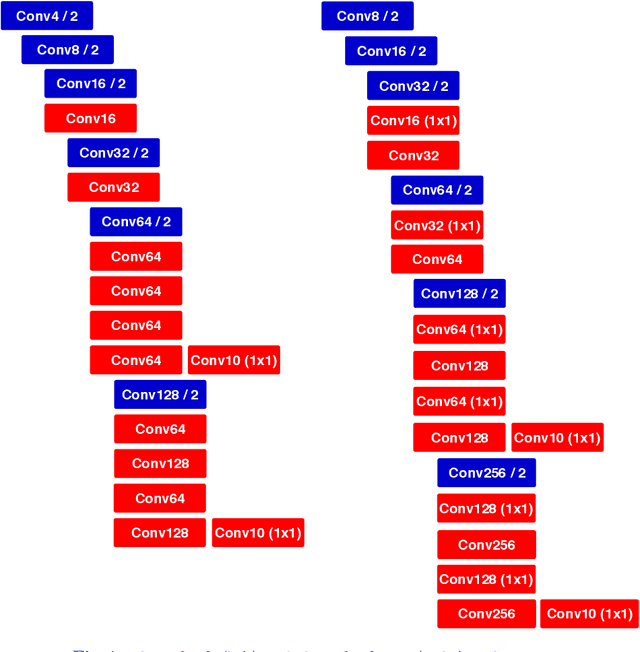
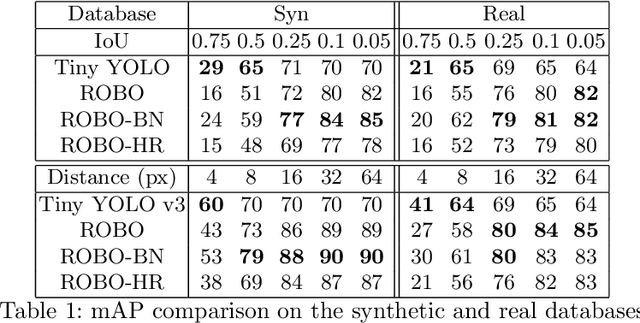

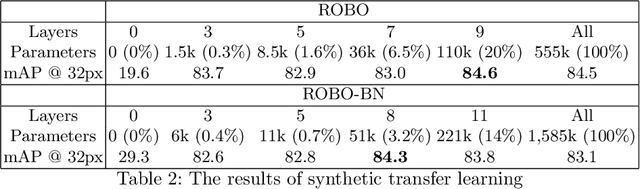
Deep Learning has become exceptionally popular in the last few years due to its success in computer vision and other fields of AI. However, deep neural networks are computationally expensive, which limits their application in low power embedded systems, such as mobile robots. In this paper, an efficient neural network architecture is proposed for the problem of detecting relevant objects in robot soccer environments. The ROBO model's increase in efficiency is achieved by exploiting the peculiarities of the environment. Compared to the state-of-the-art Tiny YOLO model, the proposed network provides approximately 35 times decrease in run time, while achieving superior average precision, although at the cost of slightly worse localization accuracy.
Exploiting Reduction Rules and Data Structures: Local Search for Minimum Vertex Cover in Massive Graphs
Sep 19, 2015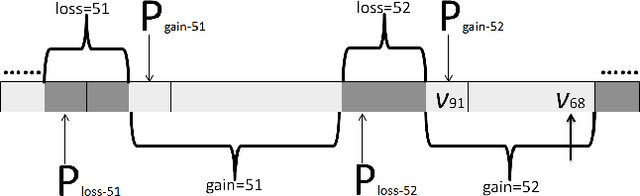
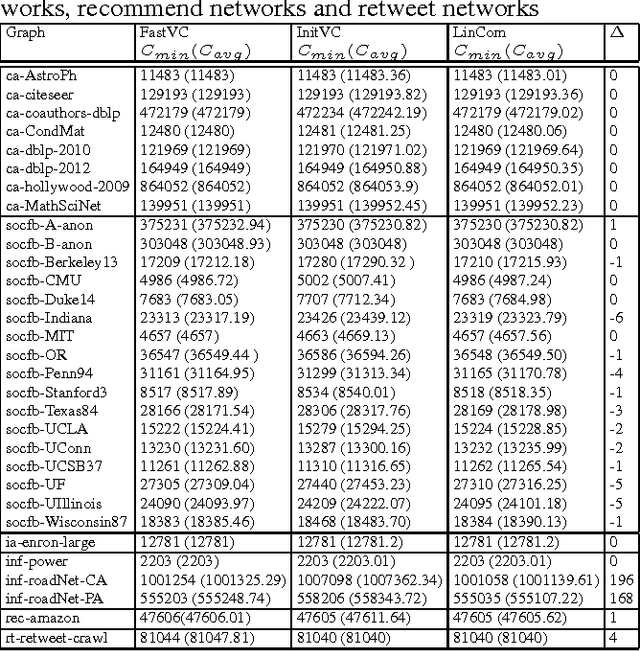
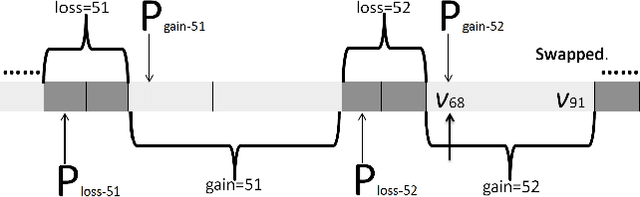
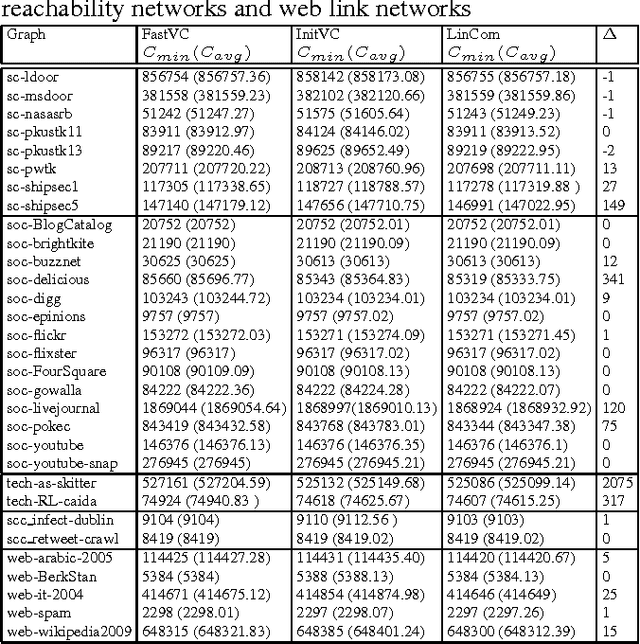
The Minimum Vertex Cover (MinVC) problem is a well-known NP-hard problem. Recently there has been great interest in solving this problem on real-world massive graphs. For such graphs, local search is a promising approach to finding optimal or near-optimal solutions. In this paper we propose a local search algorithm that exploits reduction rules and data structures to solve the MinVC problem in such graphs. Experimental results on a wide range of real-word massive graphs show that our algorithm finds better covers than state-of-the-art local search algorithms for MinVC. Also we present interesting results about the complexities of some well-known heuristics.