 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Proposal for Amending Privacy Regulations to Tackle the Challenges Stemming from Combining Data Sets
Nov 26, 2021

Modern information and communication technology practices present novel threats to privacy. We focus on some shortcomings in current data protection regulation's ability to adequately address the ramifications of AI-driven data processing practices, in particular those of combining data sets. We propose that privacy regulation relies less on individuals' privacy expectations and recommend regulatory reform in two directions: (1) abolishing the distinction between personal and anonymized data for the purposes of triggering the application of data protection laws and (2) developing methods to prioritize regulatory intervention based on the level of privacy risk posed by individual data processing actions. This is an interdisciplinary paper that intends to build a bridge between the various communities involved in privacy research. We put special emphasis on linking technical notions with their regulatory implications and introducing the relevant technical and legal terminology in use to foster more efficient coordination between the policymaking and technical communities and enable a timely solution of the problems raised.
Randomized Classifiers vs Human Decision-Makers: Trustworthy AI May Have to Act Randomly and Society Seems to Accept This
Nov 15, 2021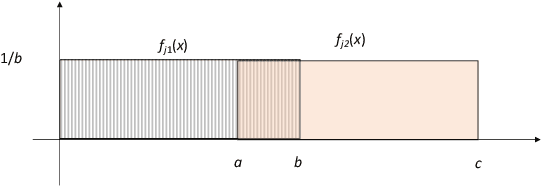
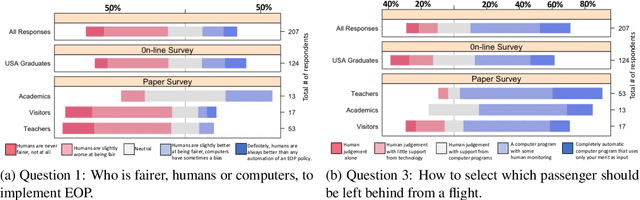

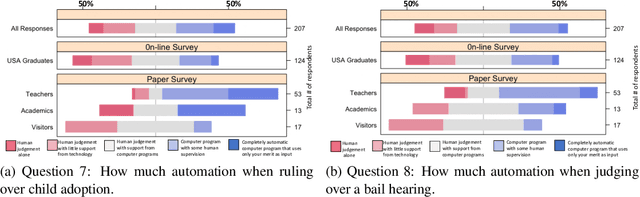
As \emph{artificial intelligence} (AI) systems are increasingly involved in decisions affecting our lives, ensuring that automated decision-making is fair and ethical has become a top priority. Intuitively, we feel that akin to human decisions, judgments of artificial agents should necessarily be grounded in some moral principles. Yet a decision-maker (whether human or artificial) can only make truly ethical (based on any ethical theory) and fair (according to any notion of fairness) decisions if full information on all the relevant factors on which the decision is based are available at the time of decision-making. This raises two problems: (1) In settings, where we rely on AI systems that are using classifiers obtained with supervised learning, some induction/generalization is present and some relevant attributes may not be present even during learning. (2) Modeling such decisions as games reveals that any -- however ethical -- pure strategy is inevitably susceptible to exploitation. Moreover, in many games, a Nash Equilibrium can only be obtained by using mixed strategies, i.e., to achieve mathematically optimal outcomes, decisions must be randomized. In this paper, we argue that in supervised learning settings, there exist random classifiers that perform at least as well as deterministic classifiers, and may hence be the optimal choice in many circumstances. We support our theoretical results with an empirical study indicating a positive societal attitude towards randomized artificial decision-makers, and discuss some policy and implementation issues related to the use of random classifiers that relate to and are relevant for current AI policy and standardization initiatives.