 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Proposal for Amending Privacy Regulations to Tackle the Challenges Stemming from Combining Data Sets
Nov 26, 2021

Modern information and communication technology practices present novel threats to privacy. We focus on some shortcomings in current data protection regulation's ability to adequately address the ramifications of AI-driven data processing practices, in particular those of combining data sets. We propose that privacy regulation relies less on individuals' privacy expectations and recommend regulatory reform in two directions: (1) abolishing the distinction between personal and anonymized data for the purposes of triggering the application of data protection laws and (2) developing methods to prioritize regulatory intervention based on the level of privacy risk posed by individual data processing actions. This is an interdisciplinary paper that intends to build a bridge between the various communities involved in privacy research. We put special emphasis on linking technical notions with their regulatory implications and introducing the relevant technical and legal terminology in use to foster more efficient coordination between the policymaking and technical communities and enable a timely solution of the problems raised.
Feature engineering workflow for activity recognition from synchronized inertial measurement units
Dec 18, 2019
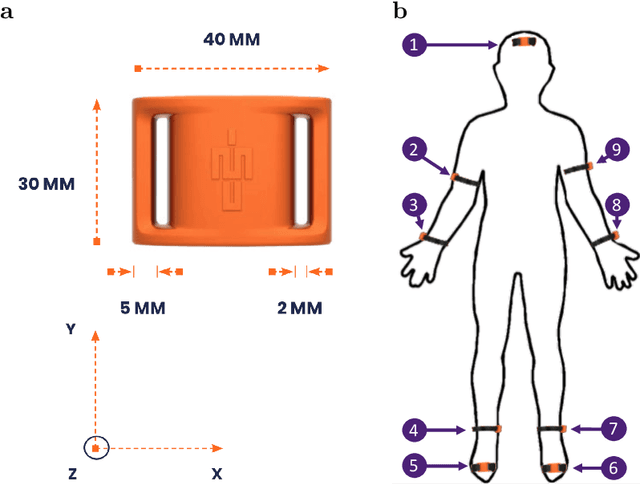
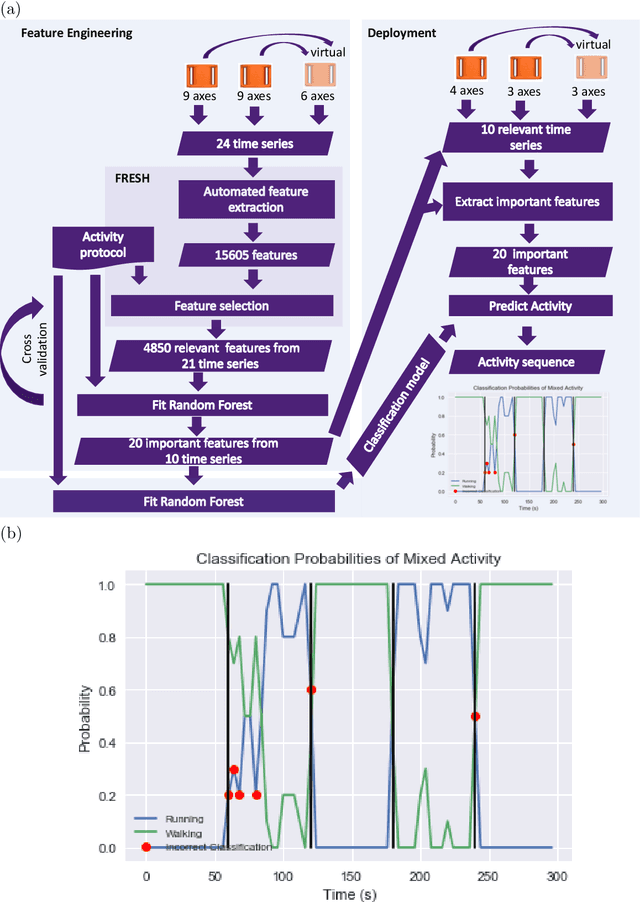
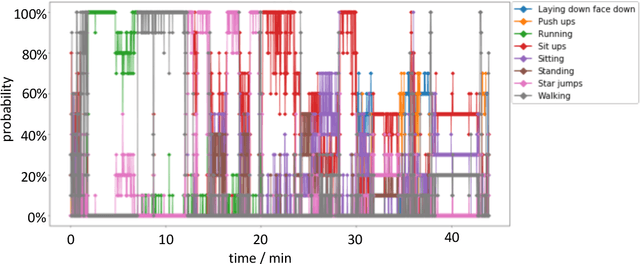
The ubiquitous availability of wearable sensors is responsible for driving the Internet-of-Things but is also making an impact on sport sciences and precision medicine. While human activity recognition from smartphone data or other types of inertial measurement units (IMU) has evolved to one of the most prominent daily life examples of machine learning, the underlying process of time-series feature engineering still seems to be time-consuming. This lengthy process inhibits the development of IMU-based machine learning applications in sport science and precision medicine. This contribution discusses a feature engineering workflow, which automates the extraction of time-series feature on based on the FRESH algorithm (FeatuRe Extraction based on Scalable Hypothesis tests) to identify statistically significant features from synchronized IMU sensors (IMeasureU Ltd, NZ). The feature engineering workflow has five main steps: time-series engineering, automated time-series feature extraction, optimized feature extraction, fitting of a specialized classifier, and deployment of optimized machine learning pipeline. The workflow is discussed for the case of a user-specific running-walking classification, and the generalization to a multi-user multi-activity classification is demonstrated.
Distributed and parallel time series feature extraction for industrial big data applications
May 19, 2017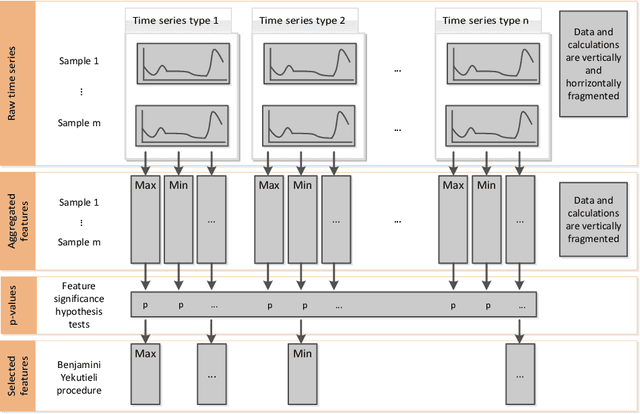
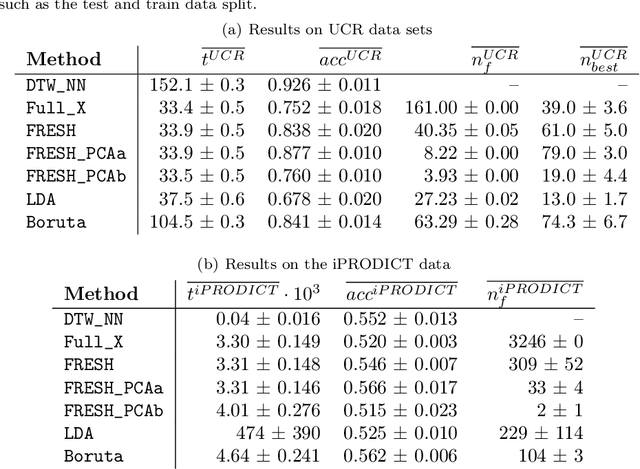
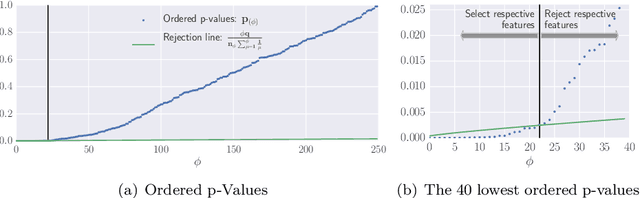
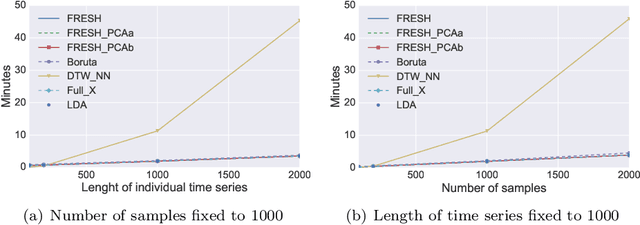
The all-relevant problem of feature selection is the identification of all strongly and weakly relevant attributes. This problem is especially hard to solve for time series classification and regression in industrial applications such as predictive maintenance or production line optimization, for which each label or regression target is associated with several time series and meta-information simultaneously. Here, we are proposing an efficient, scalable feature extraction algorithm for time series, which filters the available features in an early stage of the machine learning pipeline with respect to their significance for the classification or regression task, while controlling the expected percentage of selected but irrelevant features. The proposed algorithm combines established feature extraction methods with a feature importance filter. It has a low computational complexity, allows to start on a problem with only limited domain knowledge available, can be trivially parallelized, is highly scalable and based on well studied non-parametric hypothesis tests. We benchmark our proposed algorithm on all binary classification problems of the UCR time series classification archive as well as time series from a production line optimization project and simulated stochastic processes with underlying qualitative change of dynamics.