 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe WMDP Benchmark: Measuring and Reducing Malicious Use With Unlearning
Mar 06, 2024



The White House Executive Order on Artificial Intelligence highlights the risks of large language models (LLMs) empowering malicious actors in developing biological, cyber, and chemical weapons. To measure these risks of malicious use, government institutions and major AI labs are developing evaluations for hazardous capabilities in LLMs. However, current evaluations are private, preventing further research into mitigating risk. Furthermore, they focus on only a few, highly specific pathways for malicious use. To fill these gaps, we publicly release the Weapons of Mass Destruction Proxy (WMDP) benchmark, a dataset of 4,157 multiple-choice questions that serve as a proxy measurement of hazardous knowledge in biosecurity, cybersecurity, and chemical security. WMDP was developed by a consortium of academics and technical consultants, and was stringently filtered to eliminate sensitive information prior to public release. WMDP serves two roles: first, as an evaluation for hazardous knowledge in LLMs, and second, as a benchmark for unlearning methods to remove such hazardous knowledge. To guide progress on unlearning, we develop CUT, a state-of-the-art unlearning method based on controlling model representations. CUT reduces model performance on WMDP while maintaining general capabilities in areas such as biology and computer science, suggesting that unlearning may be a concrete path towards reducing malicious use from LLMs. We release our benchmark and code publicly at https://wmdp.ai
FedDICE: A ransomware spread detection in a distributed integrated clinical environment using federated learning and SDN based mitigation
Jun 09, 2021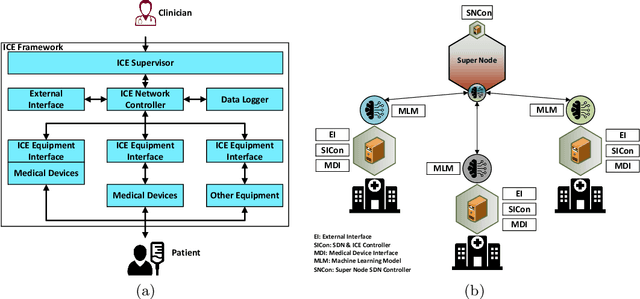
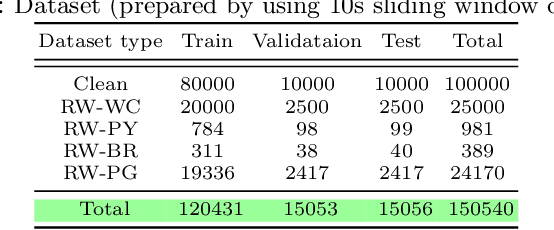
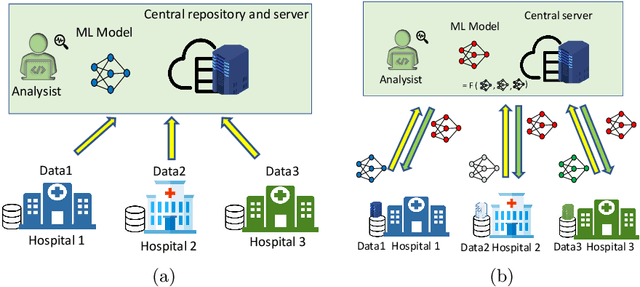
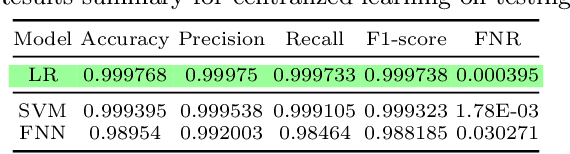
An integrated clinical environment (ICE) enables the connection and coordination of the internet of medical things around the care of patients in hospitals. However, ransomware attacks and their spread on hospital infrastructures, including ICE, are rising. Often the adversaries are targeting multiple hospitals with the same ransomware attacks. These attacks are detected by using machine learning algorithms. But the challenge is devising the anti-ransomware learning mechanisms and services under the following conditions: (1) provide immunity to other hospitals if one of them got the attack, (2) hospitals are usually distributed over geographical locations, and (3) direct data sharing is avoided due to privacy concerns. In this regard, this paper presents a federated distributed integrated clinical environment, aka. FedDICE. FedDICE integrates federated learning (FL), which is privacy-preserving learning, to SDN-oriented security architecture to enable collaborative learning, detection, and mitigation of ransomware attacks. We demonstrate the importance of FedDICE in a collaborative environment with up to four hospitals and four popular ransomware families, namely WannaCry, Petya, BadRabbit, and PowerGhost. Our results find that in both IID and non-IID data setups, FedDICE achieves the centralized baseline performance that needs direct data sharing for detection. However, as a trade-off to data privacy, FedDICE observes overhead in the anti-ransomware model training, e.g., 28x for the logistic regression model. Besides, FedDICE utilizes SDN's dynamic network programmability feature to remove the infected devices in ICE.
Towards a Robust Classifier: An MDL-Based Method for Generating Adversarial Examples
Dec 11, 2019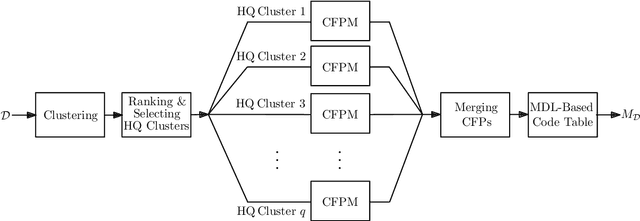
We address the problem of adversarial examples in machine learning where an adversary tries to misguide a classifier by making functionality-preserving modifications to original samples. We assume a black-box scenario where the adversary has access to only the feature set, and the final hard-decision output of the classifier. We propose a method to generate adversarial examples using the minimum description length (MDL) principle. Our final aim is to improve the robustness of the classifier by considering generated examples in rebuilding the classifier. We evaluate our method for the application of static malware detection in portable executable (PE) files. We consider API calls of PE files as their distinguishing features where the feature vector is a binary vector representing the presence-absence of API calls. In our method, we first create a dataset of benign samples by querying the target classifier. We next construct a code table of frequent patterns for the compression of this dataset using the MDL principle. We finally generate an adversarial example corresponding to a malware sample by selecting and adding a pattern from the benign code table to the malware sample. The selected pattern is the one that minimizes the length of the compressed adversarial example given the code table. This modification preserves the functionalities of the original malware sample as all original API calls are kept, and only some new API calls are added. Considering a neural network, we show that the evasion rate is 78.24 percent for adversarial examples compared to 8.16 percent for original malware samples. This shows the effectiveness of our method in generating examples that need to be considered in rebuilding the classifier.
An MDL-Based Classifier for Transactional Datasets with Application in Malware Detection
Oct 09, 2019
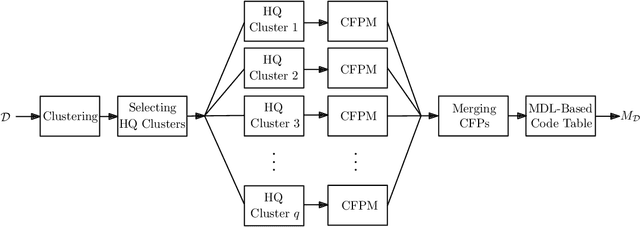
We design a classifier for transactional datasets with application in malware detection. We build the classifier based on the minimum description length (MDL) principle. This involves selecting a model that best compresses the training dataset for each class considering the MDL criterion. To select a model for a dataset, we first use clustering followed by closed frequent pattern mining to extract a subset of closed frequent patterns (CFPs). We show that this method acts as a pattern summarization method to avoid pattern explosion; this is done by giving priority to longer CFPs, and without requiring to extract all CFPs. We then use the MDL criterion to further summarize extracted patterns, and construct a code table of patterns. This code table is considered as the selected model for the compression of the dataset. We evaluate our classifier for the problem of static malware detection in portable executable (PE) files. We consider API calls of PE files as their distinguishing features. The presence-absence of API calls forms a transactional dataset. Using our proposed method, we construct two code tables, one for the benign training dataset, and one for the malware training dataset. Our dataset consists of 19696 benign, and 19696 malware samples, each a binary sequence of size 22761. We compare our classifier with deep neural networks providing us with the state-of-the-art performance. The comparison shows that our classifier performs very close to deep neural networks. We also discuss that our classifier is an interpretable classifier. This provides the motivation to use this type of classifiers where some degree of explanation is required as to why a sample is classified under one class rather than the other class.