 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Exploration at Scale
Mar 18, 2026We develop an online learning algorithm that dramatically improves the data efficiency of reinforcement learning from human feedback (RLHF). Our algorithm incrementally updates reward and language models as choice data is received. The reward model is fit to the choice data, while the language model is updated by a variation of reinforce, with reinforcement signals provided by the reward model. Several features enable the efficiency gains: a small affirmative nudge added to each reinforcement signal, an epistemic neural network that models reward uncertainty, and information-directed exploration. With Gemma large language models (LLMs), our algorithm matches the performance of offline RLHF trained on 200K labels using fewer than 20K labels, representing more than a 10x gain in data efficiency. Extrapolating from our results, we expect our algorithm trained on 1M labels to match offline RLHF trained on 1B labels. This represents a 1,000x gain. To our knowledge, these are the first results to demonstrate that such large improvements are possible.
Synthetic DOmain-Targeted Augmentation (S-DOTA) Improves Model Generalization in Digital Pathology
May 03, 2023Machine learning algorithms have the potential to improve patient outcomes in digital pathology. However, generalization of these tools is currently limited by sensitivity to variations in tissue preparation, staining procedures and scanning equipment that lead to domain shift in digitized slides. To overcome this limitation and improve model generalization, we studied the effectiveness of two Synthetic DOmain-Targeted Augmentation (S-DOTA) methods, namely CycleGAN-enabled Scanner Transform (ST) and targeted Stain Vector Augmentation (SVA), and compared them against the International Color Consortium (ICC) profile-based color calibration (ICC Cal) method and a baseline method using traditional brightness, color and noise augmentations. We evaluated the ability of these techniques to improve model generalization to various tasks and settings: four models, two model types (tissue segmentation and cell classification), two loss functions, six labs, six scanners, and three indications (hepatocellular carcinoma (HCC), nonalcoholic steatohepatitis (NASH), prostate adenocarcinoma). We compared these methods based on the macro-averaged F1 scores on in-distribution (ID) and out-of-distribution (OOD) test sets across multiple domains, and found that S-DOTA methods (i.e., ST and SVA) led to significant improvements over ICC Cal and baseline on OOD data while maintaining comparable performance on ID data. Thus, we demonstrate that S-DOTA may help address generalization due to domain shift in real world applications.
Efficient Principal Subspace Projection of Streaming Data Through Fast Similarity Matching
Aug 06, 2018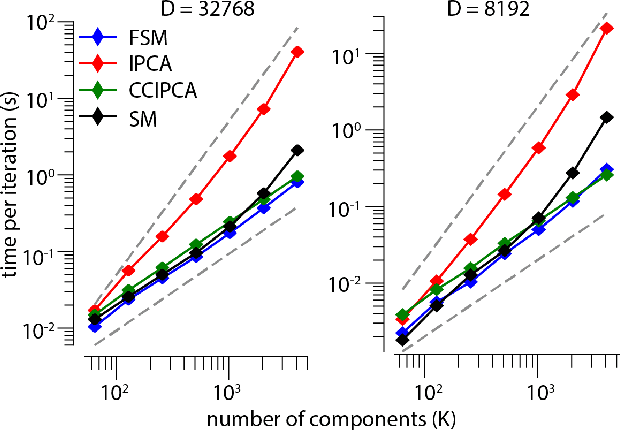
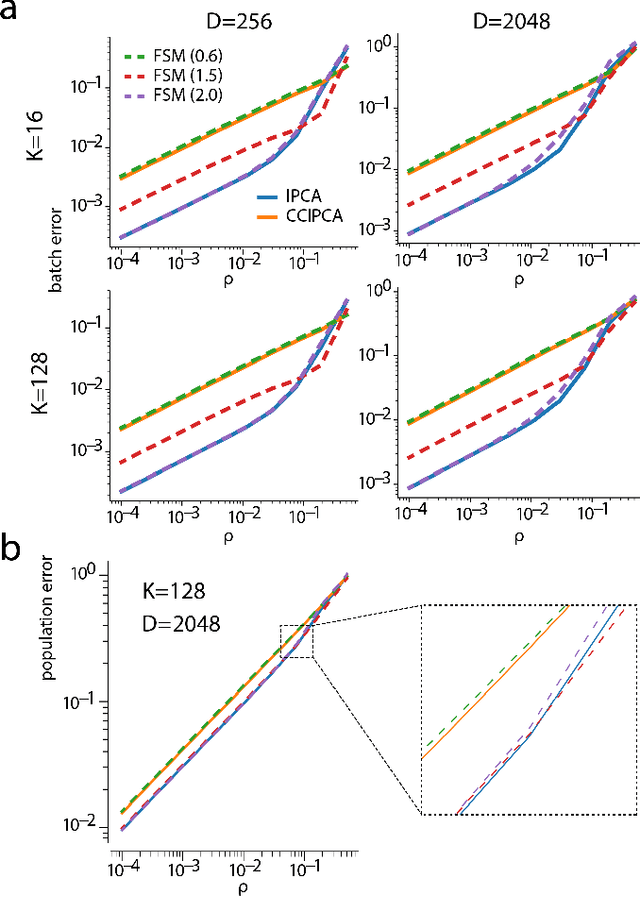
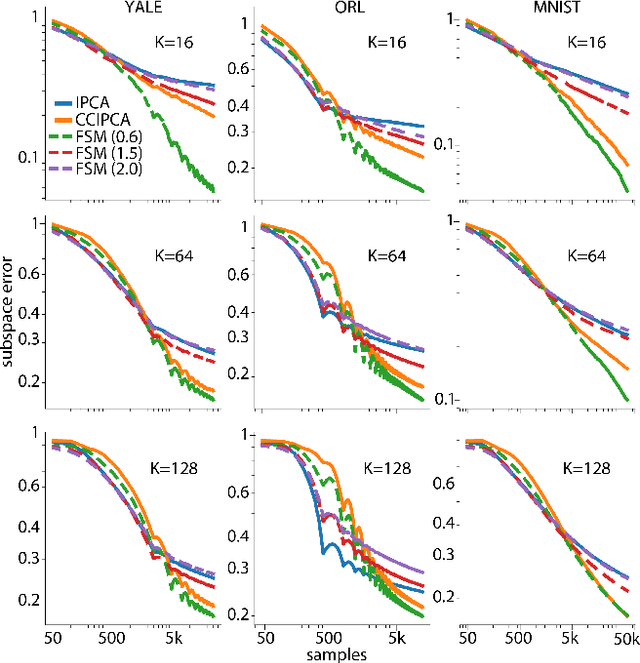
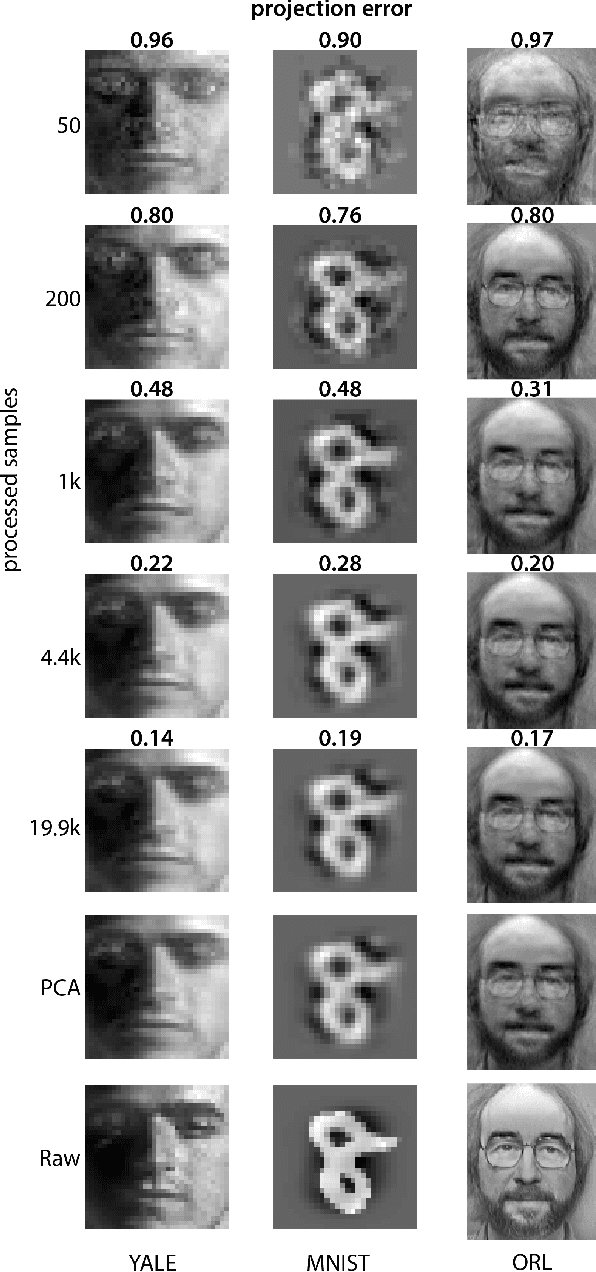
Big data problems frequently require processing datasets in a streaming fashion, either because all data are available at once but collectively are larger than available memory or because the data intrinsically arrive one data point at a time and must be processed online. Here, we introduce a computationally efficient version of similarity matching, a framework for online dimensionality reduction that incrementally estimates the top K-dimensional principal subspace of streamed data while keeping in memory only the last sample and the current iterate. To assess the performance of our approach, we construct and make public a test suite containing both a synthetic data generator and the infrastructure to test online dimensionality reduction algorithms on real datasets, as well as performant implementations of our algorithm and competing algorithms with similar aims. Among the algorithms considered we find our approach to be competitive, performing among the best on both synthetic and real data.
Sparse canonical correlation analysis
Jun 02, 2017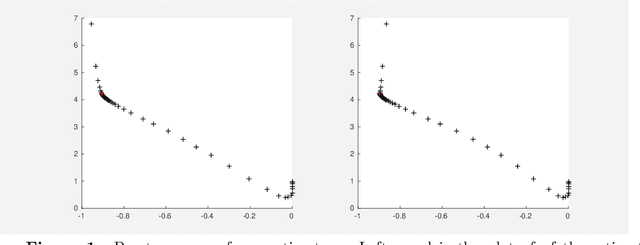
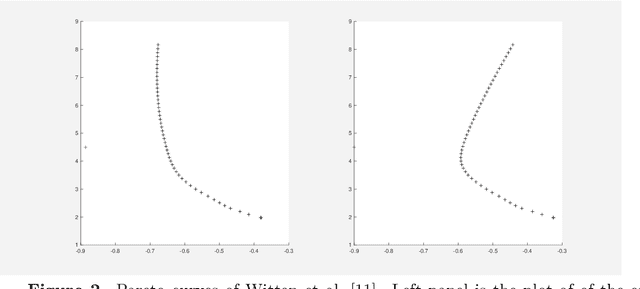

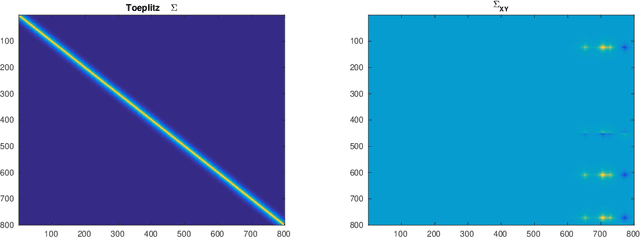
Canonical correlation analysis was proposed by Hotelling [6] and it measures linear relationship between two multidimensional variables. In high dimensional setting, the classical canonical correlation analysis breaks down. We propose a sparse canonical correlation analysis by adding l1 constraints on the canonical vectors and show how to solve it efficiently using linearized alternating direction method of multipliers (ADMM) and using TFOCS as a black box. We illustrate this idea on simulated data.