 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReport on the AAPM Grand Challenge on deep generative modeling for learning medical image statistics
May 03, 2024



The findings of the 2023 AAPM Grand Challenge on Deep Generative Modeling for Learning Medical Image Statistics are reported in this Special Report. The goal of this challenge was to promote the development of deep generative models (DGMs) for medical imaging and to emphasize the need for their domain-relevant assessment via the analysis of relevant image statistics. As part of this Grand Challenge, a training dataset was developed based on 3D anthropomorphic breast phantoms from the VICTRE virtual imaging toolbox. A two-stage evaluation procedure consisting of a preliminary check for memorization and image quality (based on the Frechet Inception distance (FID)), and a second stage evaluating the reproducibility of image statistics corresponding to domain-relevant radiomic features was developed. A summary measure was employed to rank the submissions. Additional analyses of submissions was performed to assess DGM performance specific to individual feature families, and to identify various artifacts. 58 submissions from 12 unique users were received for this Challenge. The top-ranked submission employed a conditional latent diffusion model, whereas the joint runners-up employed a generative adversarial network, followed by another network for image superresolution. We observed that the overall ranking of the top 9 submissions according to our evaluation method (i) did not match the FID-based ranking, and (ii) differed with respect to individual feature families. Another important finding from our additional analyses was that different DGMs demonstrated similar kinds of artifacts. This Grand Challenge highlighted the need for domain-specific evaluation to further DGM design as well as deployment. It also demonstrated that the specification of a DGM may differ depending on its intended use.
AmbientFlow: Invertible generative models from incomplete, noisy measurements
Sep 09, 2023Generative models have gained popularity for their potential applications in imaging science, such as image reconstruction, posterior sampling and data sharing. Flow-based generative models are particularly attractive due to their ability to tractably provide exact density estimates along with fast, inexpensive and diverse samples. Training such models, however, requires a large, high quality dataset of objects. In applications such as computed imaging, it is often difficult to acquire such data due to requirements such as long acquisition time or high radiation dose, while acquiring noisy or partially observed measurements of these objects is more feasible. In this work, we propose AmbientFlow, a framework for learning flow-based generative models directly from noisy and incomplete data. Using variational Bayesian methods, a novel framework for establishing flow-based generative models from noisy, incomplete data is proposed. Extensive numerical studies demonstrate the effectiveness of AmbientFlow in correctly learning the object distribution. The utility of AmbientFlow in a downstream inference task of image reconstruction is demonstrated.
High-Dimensional MR Reconstruction Integrating Subspace and Adaptive Generative Models
Jun 16, 2023We present a novel method that integrates subspace modeling with an adaptive generative image prior for high-dimensional MR image reconstruction. The subspace model imposes an explicit low-dimensional representation of the high-dimensional images, while the generative image prior serves as a spatial constraint on the "contrast-weighted" images or the spatial coefficients of the subspace model. A formulation was introduced to synergize these two components with complimentary regularization such as joint sparsity. A special pretraining plus subject-specific network adaptation strategy was proposed to construct an accurate generative-model-based representation for images with varying contrasts, validated by experimental data. An iterative algorithm was introduced to jointly update the subspace coefficients and the multiresolution latent space of the generative image model that leveraged a recently developed intermediate layer optimization technique for network inversion. We evaluated the utility of the proposed method in two high-dimensional imaging applications: accelerated MR parameter mapping and high-resolution MRSI. Improved performance over state-of-the-art subspace-based methods was demonstrated in both cases. Our work demonstrated the potential of integrating data-driven and adaptive generative models with low-dimensional representation for high-dimensional imaging problems.
Assessing the ability of generative adversarial networks to learn canonical medical image statistics
Apr 27, 2022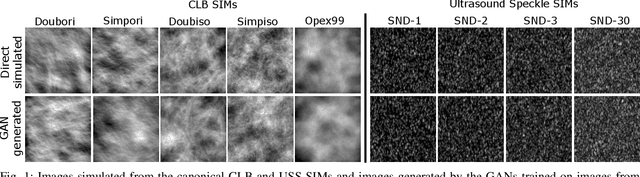
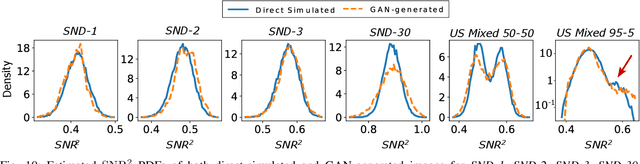
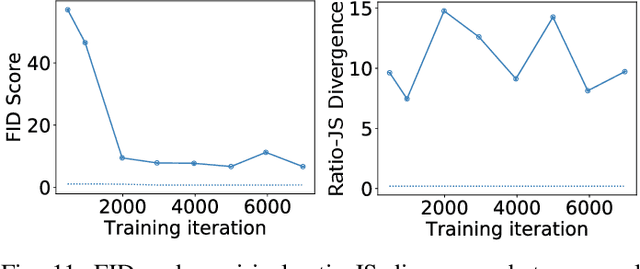
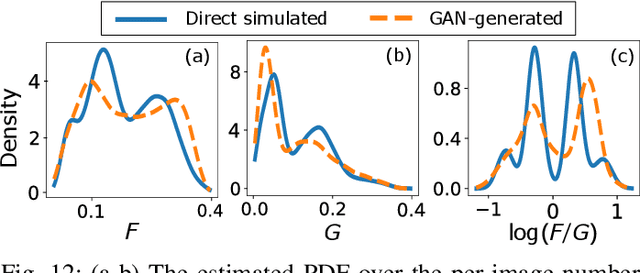
In recent years, generative adversarial networks (GANs) have gained tremendous popularity for potential applications in medical imaging, such as medical image synthesis, restoration, reconstruction, translation, as well as objective image quality assessment. Despite the impressive progress in generating high-resolution, perceptually realistic images, it is not clear if modern GANs reliably learn the statistics that are meaningful to a downstream medical imaging application. In this work, the ability of a state-of-the-art GAN to learn the statistics of canonical stochastic image models (SIMs) that are relevant to objective assessment of image quality is investigated. It is shown that although the employed GAN successfully learned several basic first- and second-order statistics of the specific medical SIMs under consideration and generated images with high perceptual quality, it failed to correctly learn several per-image statistics pertinent to the these SIMs, highlighting the urgent need to assess medical image GANs in terms of objective measures of image quality.
Evaluating Procedures for Establishing Generative Adversarial Network-based Stochastic Image Models in Medical Imaging
Apr 07, 2022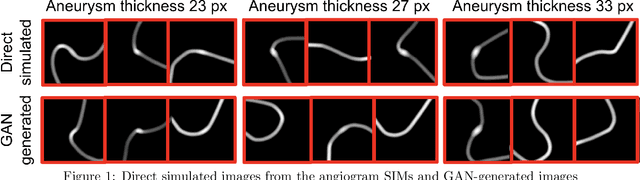
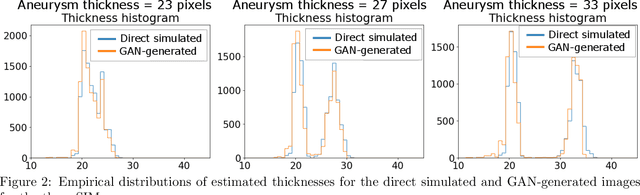
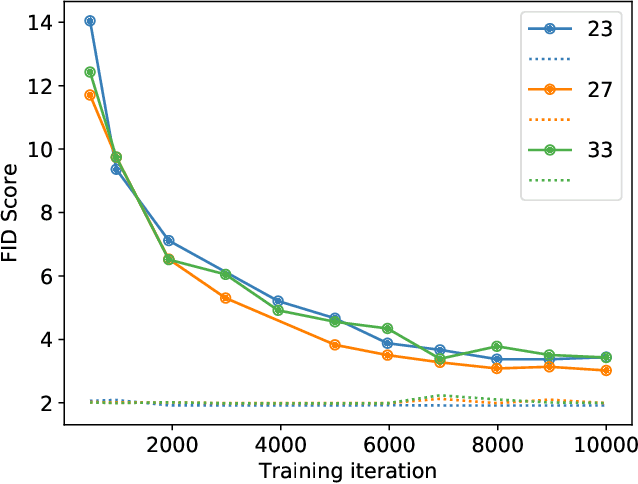
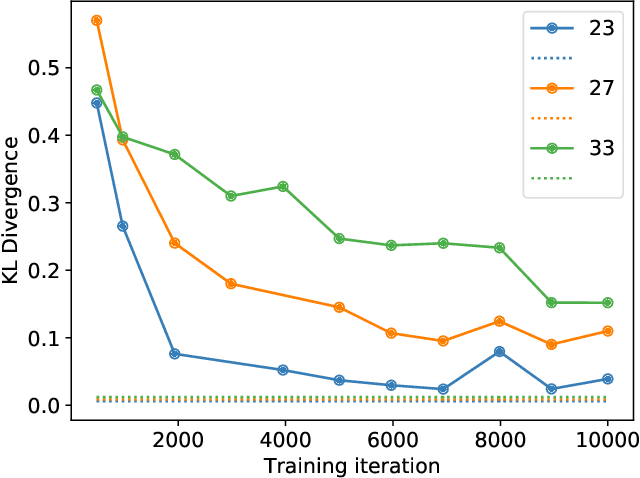
Modern generative models, such as generative adversarial networks (GANs), hold tremendous promise for several areas of medical imaging, such as unconditional medical image synthesis, image restoration, reconstruction and translation, and optimization of imaging systems. However, procedures for establishing stochastic image models (SIMs) using GANs remain generic and do not address specific issues relevant to medical imaging. In this work, canonical SIMs that simulate realistic vessels in angiography images are employed to evaluate procedures for establishing SIMs using GANs. The GAN-based SIM is compared to the canonical SIM based on its ability to reproduce those statistics that are meaningful to the particular medically realistic SIM considered. It is shown that evaluating GANs using classical metrics and medically relevant metrics may lead to different conclusions about the fidelity of the trained GANs. This work highlights the need for the development of objective metrics for evaluating GANs.
Prior image-based medical image reconstruction using a style-based generative adversarial network
Feb 17, 2022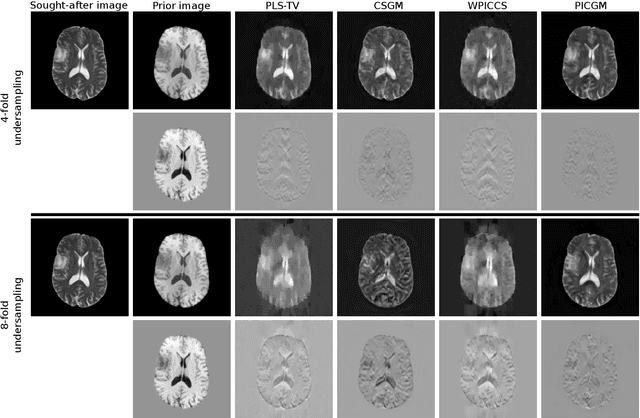
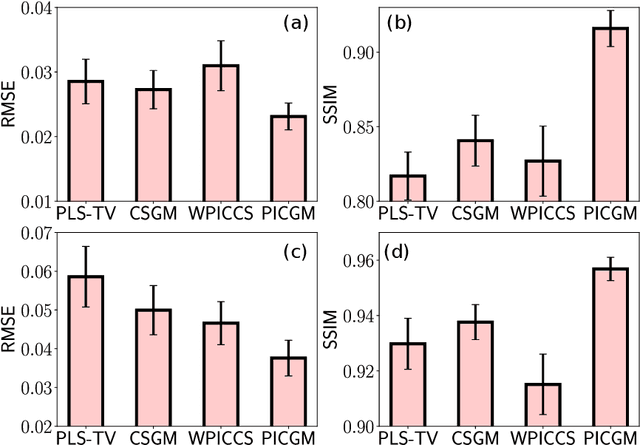
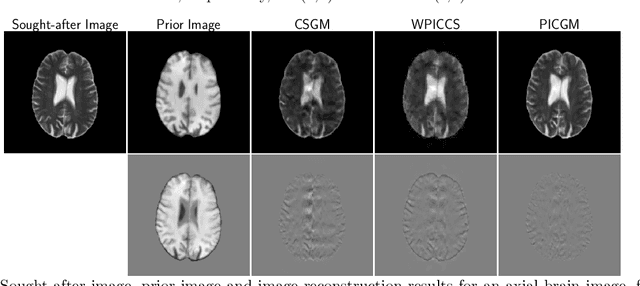

Computed medical imaging systems require a computational reconstruction procedure for image formation. In order to recover a useful estimate of the object to-be-imaged when the recorded measurements are incomplete, prior knowledge about the nature of object must be utilized. In order to improve the conditioning of an ill-posed imaging inverse problem, deep learning approaches are being actively investigated for better representing object priors and constraints. This work proposes to use a style-based generative adversarial network (StyleGAN) to constrain an image reconstruction problem in the case where additional information in the form of a prior image of the sought-after object is available. An optimization problem is formulated in the intermediate latent-space of a StyleGAN, that is disentangled with respect to meaningful image attributes or "styles", such as the contrast used in magnetic resonance imaging (MRI). Discrepancy between the sought-after and prior images is measured in the disentangled latent-space, and is used to regularize the inverse problem in the form of constraints on specific styles of the disentangled latent-space. A stylized numerical study inspired by MR imaging is designed, where the sought-after and the prior image are structurally similar, but belong to different contrast mechanisms. The presented numerical studies demonstrate the superiority of the proposed approach as compared to classical approaches in the form of traditional metrics.
Impact of deep learning-based image super-resolution on binary signal detection
Jul 06, 2021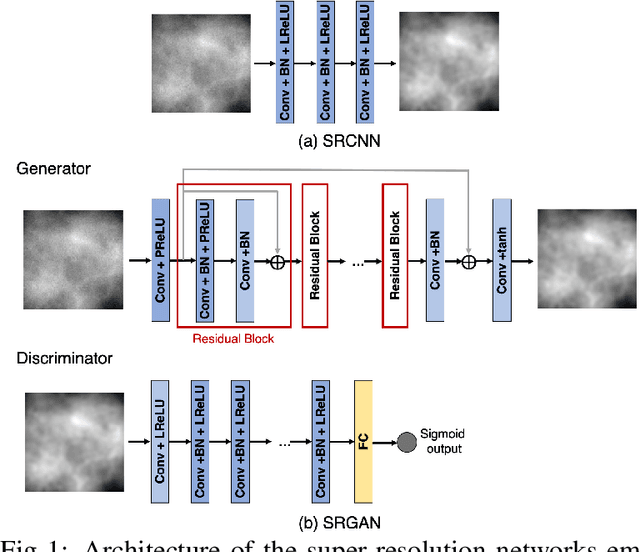



Deep learning-based image super-resolution (DL-SR) has shown great promise in medical imaging applications. To date, most of the proposed methods for DL-SR have only been assessed by use of traditional measures of image quality (IQ) that are commonly employed in the field of computer vision. However, the impact of these methods on objective measures of image quality that are relevant to medical imaging tasks remains largely unexplored. In this study, we investigate the impact of DL-SR methods on binary signal detection performance. Two popular DL-SR methods, the super-resolution convolutional neural network (SRCNN) and the super-resolution generative adversarial network (SRGAN), were trained by use of simulated medical image data. Binary signal-known-exactly with background-known-statistically (SKE/BKS) and signal-known-statistically with background-known-statistically (SKS/BKS) detection tasks were formulated. Numerical observers, which included a neural network-approximated ideal observer and common linear numerical observers, were employed to assess the impact of DL-SR on task performance. The impact of the complexity of the DL-SR network architectures on task-performance was quantified. In addition, the utility of DL-SR for improving the task-performance of sub-optimal observers was investigated. Our numerical experiments confirmed that, as expected, DL-SR could improve traditional measures of IQ. However, for many of the study designs considered, the DL-SR methods provided little or no improvement in task performance and could even degrade it. It was observed that DL-SR could improve the task-performance of sub-optimal observers under certain conditions. The presented study highlights the urgent need for the objective assessment of DL-SR methods and suggests avenues for improving their efficacy in medical imaging applications.
Prior Image-Constrained Reconstruction using Style-Based Generative Models
Feb 24, 2021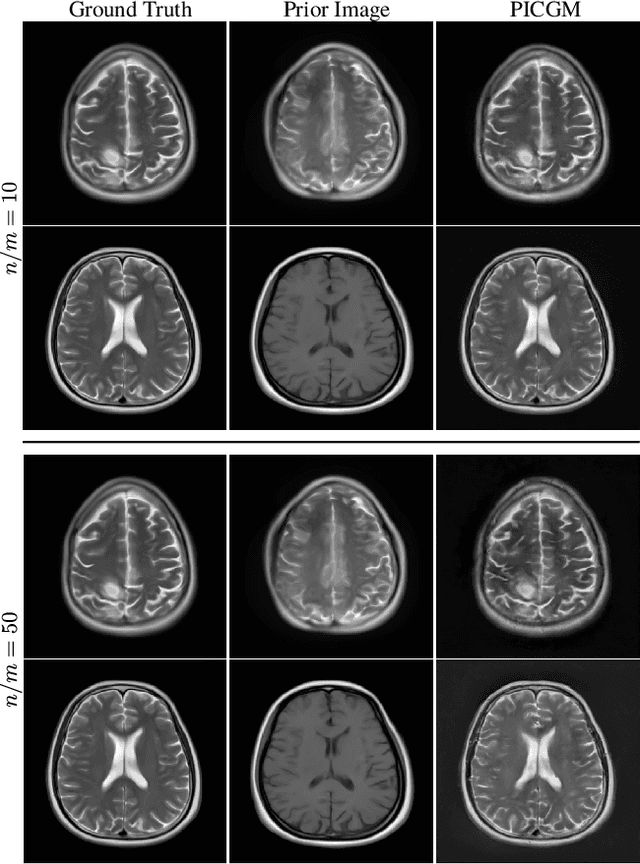

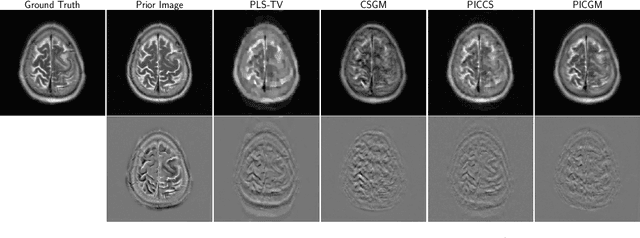
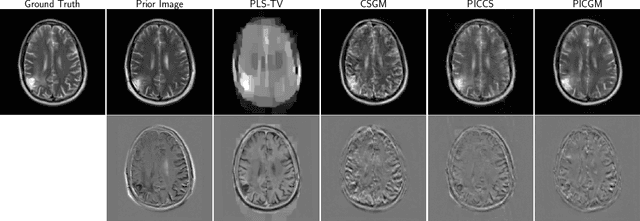
Obtaining an accurate and reliable estimate of an object from highly incomplete imaging measurements remains a holy grail of imaging science. Deep learning methods have shown promise in learning object priors or constraints to improve the conditioning of an ill-posed imaging inverse problem. In this study, a framework for estimating an object of interest that is semantically related to a known prior image, is proposed. An optimization problem is formulated in the disentangled latent space of a style-based generative model, and semantically meaningful constraints are imposed using the disentangled latent representation of the prior image. Stable recovery from incomplete measurements with the help of a prior image is theoretically analyzed. Numerical experiments demonstrating the superior performance of our approach as compared to related methods are presented.
On hallucinations in tomographic image reconstruction
Dec 01, 2020

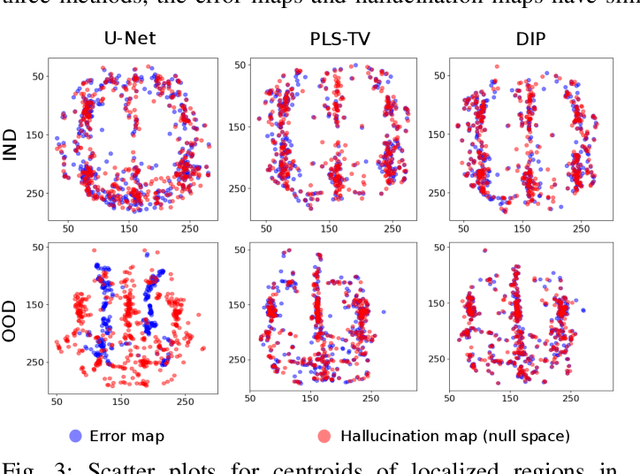
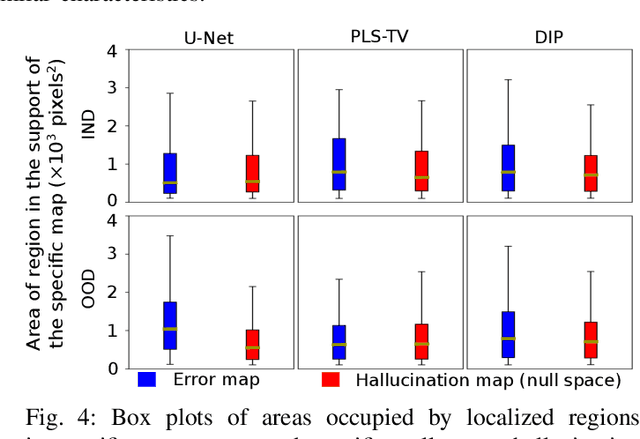
Tomographic image reconstruction is generally an ill-posed linear inverse problem. Such ill-posed inverse problems are typically regularized using prior knowledge of the sought-after object property. Recently, deep neural networks have been actively investigated for regularizing image reconstruction problems by learning a prior for the object properties from training images. However, an analysis of the prior information learned by these deep networks and their ability to generalize to data that may lie outside the training distribution is still being explored. An inaccurate prior might lead to false structures being hallucinated in the reconstructed image and that is a cause for serious concern in medical imaging. In this work, we propose to illustrate the effect of the prior imposed by a reconstruction method by decomposing the image estimate into generalized measurement and null components. The concept of a hallucination map is introduced for the general purpose of understanding the effect of the prior in regularized reconstruction methods. Numerical studies are conducted corresponding to a stylized tomographic imaging modality. The behavior of different reconstruction methods under the proposed formalism is discussed with the help of the numerical studies.