 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSovereign-by-Design A Reference Architecture for AI and Blockchain Enabled Systems
Feb 05, 2026Digital sovereignty has emerged as a central concern for modern software-intensive systems, driven by the dominance of non-sovereign cloud infrastructures, the rapid adoption of Generative AI, and increasingly stringent regulatory requirements. While existing initiatives address governance, compliance, and security in isolation, they provide limited guidance on how sovereignty can be operationalized at the architectural level. In this paper, we argue that sovereignty must be treated as a first-class architectural property rather than a purely regulatory objective. We introduce a Sovereign Reference Architecture that integrates self-sovereign identity, blockchain-based trust and auditability, sovereign data governance, and Generative AI deployed under explicit architectural control. The architecture explicitly captures the dual role of Generative AI as both a source of governance risk and an enabler of compliance, accountability, and continuous assurance when properly constrained. By framing sovereignty as an architectural quality attribute, our work bridges regulatory intent and concrete system design, offering a coherent foundation for building auditable, evolvable, and jurisdiction-aware AI-enabled systems. The proposed reference architecture provides a principled starting point for future research and practice at the intersection of software architecture, Generative AI, and digital sovereignty.
A Defect is Being Born: How Close Are We? A Time Sensitive Forecasting Approach
Jan 05, 2026Background. Defect prediction has been a highly active topic among researchers in the Empirical Software Engineering field. Previous literature has successfully achieved the most accurate prediction of an incoming fault and identified the features and anomalies that precede it through just-in-time prediction. As software systems evolve continuously, there is a growing need for time-sensitive methods capable of forecasting defects before they manifest. Aim. Our study seeks to explore the effectiveness of time-sensitive techniques for defect forecasting. Moreover, we aim to investigate the early indicators that precede the occurrence of a defect. Method. We will train multiple time-sensitive forecasting techniques to forecast the future bug density of a software project, as well as identify the early symptoms preceding the occurrence of a defect. Expected results. Our expected results are translated into empirical evidence on the effectiveness of our approach for early estimation of bug proneness.
The Invisible Hand of AI Libraries Shaping Open Source Projects and Communities
Jan 05, 2026In the early 1980s, Open Source Software emerged as a revolutionary concept amidst the dominance of proprietary software. What began as a revolutionary idea has now become the cornerstone of computer science. Amidst OSS projects, AI is increasing its presence and relevance. However, despite the growing popularity of AI, its adoption and impacts on OSS projects remain underexplored. We aim to assess the adoption of AI libraries in Python and Java OSS projects and examine how they shape development, including the technical ecosystem and community engagement. To this end, we will perform a large-scale analysis on 157.7k potential OSS repositories, employing repository metrics and software metrics to compare projects adopting AI libraries against those that do not. We expect to identify measurable differences in development activity, community engagement, and code complexity between OSS projects that adopt AI libraries and those that do not, offering evidence-based insights into how AI integration reshapes software development practices.
SQuaD: The Software Quality Dataset
Nov 14, 2025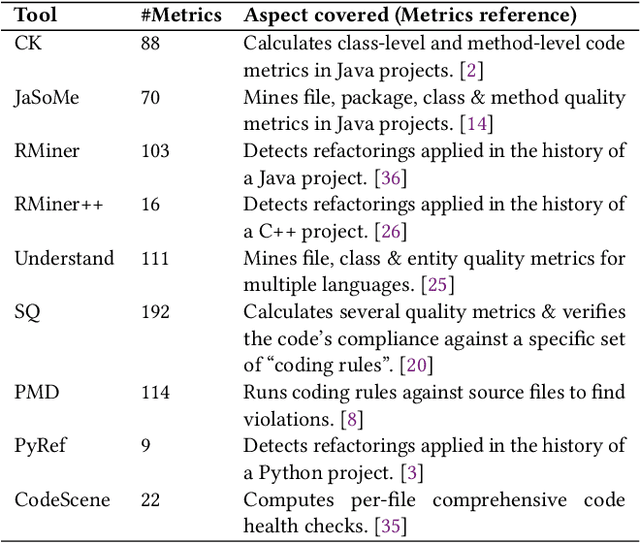
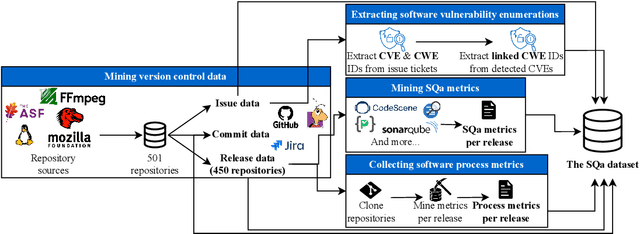
Software quality research increasingly relies on large-scale datasets that measure both the product and process aspects of software systems. However, existing resources often focus on limited dimensions, such as code smells, technical debt, or refactoring activity, thereby restricting comprehensive analyses across time and quality dimensions. To address this gap, we present the Software Quality Dataset (SQuaD), a multi-dimensional, time-aware collection of software quality metrics extracted from 450 mature open-source projects across diverse ecosystems, including Apache, Mozilla, FFmpeg, and the Linux kernel. By integrating nine state-of-the-art static analysis tools, i.e., SonarQube, CodeScene, PMD, Understand, CK, JaSoMe, RefactoringMiner, RefactoringMiner++, and PyRef, our dataset unifies over 700 unique metrics at method, class, file, and project levels. Covering a total of 63,586 analyzed project releases, SQuaD also provides version control and issue-tracking histories, software vulnerability data (CVE/CWE), and process metrics proven to enhance Just-In-Time (JIT) defect prediction. The SQuaD enables empirical research on maintainability, technical debt, software evolution, and quality assessment at unprecedented scale. We also outline emerging research directions, including automated dataset updates and cross-project quality modeling to support the continuous evolution of software analytics. The dataset is publicly available on ZENODO (DOI: 10.5281/zenodo.17566690).
What Were You Thinking? An LLM-Driven Large-Scale Study of Refactoring Motivations in Open-Source Projects
Sep 09, 2025Context. Code refactoring improves software quality without changing external behavior. Despite its advantages, its benefits are hindered by the considerable cost of time, resources, and continuous effort it demands. Aim. Understanding why developers refactor, and which metrics capture these motivations, may support wider and more effective use of refactoring in practice. Method. We performed a large-scale empirical study to analyze developers refactoring activity, leveraging Large Language Models (LLMs) to identify underlying motivations from version control data, comparing our findings with previous motivations reported in the literature. Results. LLMs matched human judgment in 80% of cases, but aligned with literature-based motivations in only 47%. They enriched 22% of motivations with more detailed rationale, often highlighting readability, clarity, and structural improvements. Most motivations were pragmatic, focused on simplification and maintainability. While metrics related to developer experience and code readability ranked highest, their correlation with motivation categories was weak. Conclusions. We conclude that LLMs effectively capture surface-level motivations but struggle with architectural reasoning. Their value lies in providing localized explanations, which, when combined with software metrics, can form hybrid approaches. Such integration offers a promising path toward prioritizing refactoring more systematically and balancing short-term improvements with long-term architectural goals.
CppSATD: A Reusable Self-Admitted Technical Debt Dataset in C++
May 02, 2025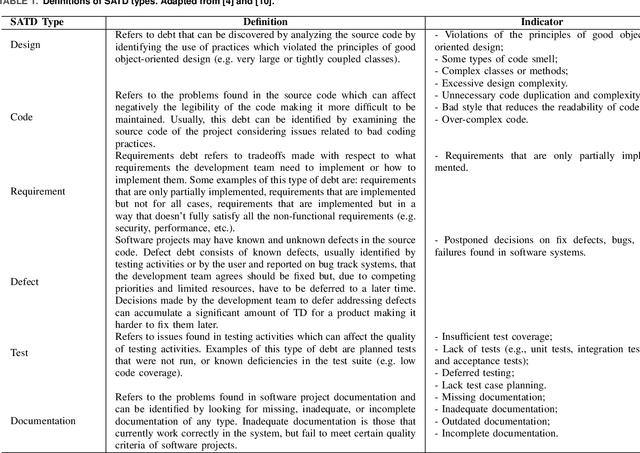
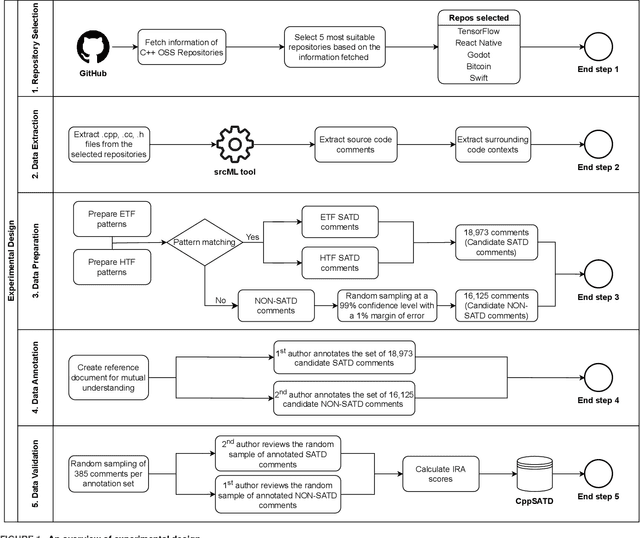


In software development, technical debt (TD) refers to suboptimal implementation choices made by the developers to meet urgent deadlines and limited resources, posing challenges for future maintenance. Self-Admitted Technical Debt (SATD) is a sub-type of TD, representing specific TD instances ``openly admitted'' by the developers and often expressed through source code comments. Previous research on SATD has focused predominantly on the Java programming language, revealing a significant gap in cross-language SATD. Such a narrow focus limits the generalizability of existing findings as well as SATD detection techniques across multiple programming languages. Our work addresses such limitation by introducing CppSATD, a dedicated C++ SATD dataset, comprising over 531,000 annotated comments and their source code contexts. Our dataset can serve as a foundation for future studies that aim to develop SATD detection methods in C++, generalize the existing findings to other languages, or contribute novel insights to cross-language SATD research.
Generative AI for Software Architecture. Applications, Trends, Challenges, and Future Directions
Mar 17, 2025



Context: Generative Artificial Intelligence (GenAI) is transforming much of software development, yet its application in software architecture is still in its infancy, and no prior study has systematically addressed the topic. Aim: We aim to systematically synthesize the use, rationale, contexts, usability, and future challenges of GenAI in software architecture. Method: We performed a multivocal literature review (MLR), analyzing peer-reviewed and gray literature, identifying current practices, models, adoption contexts, and reported challenges, extracting themes via open coding. Results: Our review identified significant adoption of GenAI for architectural decision support and architectural reconstruction. OpenAI GPT models are predominantly applied, and there is consistent use of techniques such as few-shot prompting and retrieved-augmented generation (RAG). GenAI has been applied mostly to initial stages of the Software Development Life Cycle (SDLC), such as Requirements-to-Architecture and Architecture-to-Code. Monolithic and microservice architectures were the dominant targets. However, rigorous testing of GenAI outputs was typically missing from the studies. Among the most frequent challenges are model precision, hallucinations, ethical aspects, privacy issues, lack of architecture-specific datasets, and the absence of sound evaluation frameworks. Conclusions: GenAI shows significant potential in software design, but several challenges remain on its path to greater adoption. Research efforts should target designing general evaluation methodologies, handling ethics and precision, increasing transparency and explainability, and promoting architecture-specific datasets and benchmarks to bridge the gap between theoretical possibilities and practical use.
On Large Language Models in Mission-Critical IT Governance: Are We Ready Yet?
Dec 16, 2024Context. The security of critical infrastructure has been a fundamental concern since the advent of computers, and this concern has only intensified in today's cyber warfare landscape. Protecting mission-critical systems (MCSs), including essential assets like healthcare, telecommunications, and military coordination, is vital for national security. These systems require prompt and comprehensive governance to ensure their resilience, yet recent events have shown that meeting these demands is increasingly challenging. Aim. Building on prior research that demonstrated the potential of GAI, particularly Large Language Models (LLMs), in improving risk analysis tasks, we aim to explore practitioners' perspectives, specifically developers and security personnel, on using generative AI (GAI) in the governance of IT MCSs seeking to provide insights and recommendations for various stakeholders, including researchers, practitioners, and policymakers. Method. We designed a survey to collect practical experiences, concerns, and expectations of practitioners who develop and implement security solutions in the context of MCSs. Analyzing this data will help identify key trends, challenges, and opportunities for introducing GAIs in this niche domain. Conclusions and Future Works. Our findings highlight that the safe use of LLMs in MCS governance requires interdisciplinary collaboration. Researchers should focus on designing regulation-oriented models and focus on accountability; practitioners emphasize data protection and transparency, while policymakers must establish a unified AI framework with global benchmarks to ensure ethical and secure LLMs-based MCS governance.
6GSoft: Software for Edge-to-Cloud Continuum
Jul 09, 2024In the era of 6G, developing and managing software requires cutting-edge software engineering (SE) theories and practices tailored for such complexity across a vast number of connected edge devices. Our project aims to lead the development of sustainable methods and energy-efficient orchestration models specifically for edge environments, enhancing architectural support driven by AI for contemporary edge-to-cloud continuum computing. This initiative seeks to position Finland at the forefront of the 6G landscape, focusing on sophisticated edge orchestration and robust software architectures to optimize the performance and scalability of edge networks. Collaborating with leading Finnish universities and companies, the project emphasizes deep industry-academia collaboration and international expertise to address critical challenges in edge orchestration and software architecture, aiming to drive significant advancements in software productivity and market impact.
Beyond Words: On Large Language Models Actionability in Mission-Critical Risk Analysis
Jun 11, 2024



Context. Risk analysis assesses potential risks in specific scenarios. Risk analysis principles are context-less; the same methodology can be applied to a risk connected to health and information technology security. Risk analysis requires a vast knowledge of national and international regulations and standards and is time and effort-intensive. A large language model can quickly summarize information in less time than a human and can be fine-tuned to specific tasks. Aim. Our empirical study aims to investigate the effectiveness of Retrieval-Augmented Generation and fine-tuned LLM in Risk analysis. To our knowledge, no prior study has explored its capabilities in risk analysis. Method. We manually curated \totalscenarios unique scenarios leading to \totalsamples representative samples from over 50 mission-critical analyses archived by the industrial context team in the last five years. We compared the base GPT-3.5 and GPT-4 models versus their Retrieval-Augmented Generation and fine-tuned counterparts. We employ two human experts as competitors of the models and three other three human experts to review the models and the former human expert's analysis. The reviewers analyzed 5,000 scenario analyses. Results and Conclusions. HEs demonstrated higher accuracy, but LLMs are quicker and more actionable. Moreover, our findings show that RAG-assisted LLMs have the lowest hallucination rates, effectively uncovering hidden risks and complementing human expertise. Thus, the choice of model depends on specific needs, with FTMs for accuracy, RAG for hidden risks discovery, and base models for comprehensiveness and actionability. Therefore, experts can leverage LLMs for an effective complementing companion in risk analysis within a condensed timeframe. They can also save costs by averting unnecessary expenses associated with implementing unwarranted countermeasures.